Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Computer network wikipedia , lookup
IEEE 802.1aq wikipedia , lookup
Deep packet inspection wikipedia , lookup
Distributed operating system wikipedia , lookup
Network tap wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
Quality of service wikipedia , lookup
Computer cluster wikipedia , lookup
Airborne Networking wikipedia , lookup
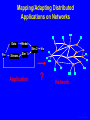
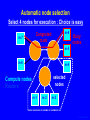
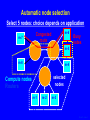
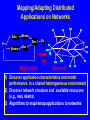
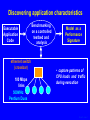
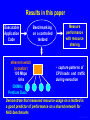
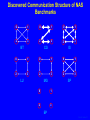
Characterizing NAS Benchmark Performance on Shared Heterogeneous Networks Jaspal Subhlok Shreenivasa Venkataramaiah Amitoj Singh University of Houston Heterogeneous Computing Workshop, April 15, 2002 Rice01, slide 1 Mapping/Adapting Distributed Applications on Networks Data Model Sim 2 Pre Stream Vis Sim 1 Application ? Network Rice01, slide 2 Automatic node selection Select 4 nodes for execution : Choice is easy m-7 m-6 Congested route Busy nodes m-5 m-8 m-4 selected nodes Compute nodes Routers m-1 m-2 m-3 Rice01, slide 3 Automatic node selection Select 5 nodes: choice depends on application m-7 m-6 Congested route Busy nodes m-5 m-8 m-4 selected nodes Compute nodes Routers m-1 m-2 m-3 Rice01, slide 4 Mapping/Adapting Distributed Applications on Networks Data Model Sim 2 Pre Stream Vis Sim 1 Application ? Network 1) Discover application characteristics and model performance in a shared heterogeneous environment 2) Discover network structure and available resources (e.g., NWS, REMOS) 3) Algorithms to map/remap applications to networks Rice01, slide 5 Methodology for Building Application Performance Signature Performance signature = model to predict application execution time under given network conditions 1. Execute the application on a controlled testbed 2. Measure system level activity during execution – such as CPU, communication and memory usage 3. Analyze and discover program level activity (message sizes, sequences, synchronization waits) 4. Develop a performance signature • No access to source code/libraries assumed Rice01, slide 6 Discovering application characteristics Executable Application Code ethernet switch (crossbar) 100 Mbps links 500MHz Pentium Duos Benchmarking on a controlled testbed and analysis Model as a Performance Signature • capture patterns of CPU loads and traffic during execution Rice01, slide 7 Results in this paper Executable Application Code ethernet switch (crossbar) 100 Mbps links 500MHz Pentium Duos Benchmarking on a controlled testbed Measure performance with resource sharing • capture patterns of CPU loads and traffic during execution Demonstrate that measured resource usage on a testbed is a good predictor of performance on a shared network for NAS benchmarks Rice01, slide 8 Experiment Procedure • Resource utilization of NAS benchmarks measured on a dedicated testbed – CPU probes based on “top” and “vmstat” utility – Bandwidth using “iptraf”, “tcpdump”, SNMP queries • Performance of NAS benchmark measured with competing loads and limited bandwidth – Employ dummynet and NISTnet to limit bandwidth • All measurements presented are on 500MHz Pentium Duos, 100 Mbps network, TCP/IP, FreeBSD • All results on Class A, MPI, NAS Benchmarks Rice01, slide 9 Discovered Communication Structure of NAS Benchmarks 0 1 0 1 0 1 2 3 2 3 2 3 BT CG IS 0 1 0 1 0 1 2 3 2 3 2 3 LU MG SP 0 1 2 3 EP Rice01, slide 10 Percentage increase in execution time Performance with competing computation loads 140 120 All nodes are loaded Most busy node loaded Least busy node loaded 100 • Increase beyond 50% due to lack of coordinated (gang) scheduling and synchronization • Correlation between low CPU utilization and smaller increase in execution time (e.g. MG shows only ~60% CPU utilization) 80 60 40 20 0 EP BT CG IS LU MG SP • Execution time is lower if least busy node has a competing load (20% difference in the busyness level for CG) Rice01, slide 11 140 16 120 14 12 100 10 80 8 60 6 40 4 20 2 0 0 CG IS MG SP BT LU Link network traffic (Mbps) Percentage increase in execution time Performance with Limited Bandwidth (reduced from 100 to 10Mbps) on one link EP Close correlation between link utilization and performance with a shared or slow link Rice01, slide 12 500 80 450 70 400 60 350 50 300 250 40 200 30 150 20 100 10 50 0 0 IS CG SP MG BT LU Total network traffic (Mbps) Percentage increase in execution time Performance with Limited Bandwidth (reduced from 100 to 10 Mbps) on all links EP Close correlation between total network traffic and performance with all shared or slow links Rice01, slide 13 Results and Conclusions (not the last slide) • Computation and communication patterns can be captured by passive, near non-intrusive, monitoring • Benchmarked resource usage pattern is a strong indicator of performance with sharing – strong correlation between application traffic and performance with low bandwidth links – CPU utilization during normal execution a good indicator of performance with node sharing Synchronization and timing effects were not dominant for NAS Benchnmarks Rice01, slide 14 Discussion and Ongoing Work (the last slide) • Capture application level data exchange pattern from network probes (e.g. MPI message sequence, sizes) – slowdown different for different message sizes • Infer the main synchronization/waiting patterns – Impact of unbalanced execution and lack of gang scheduling • Capture impact of CPU scheduling policy for accurate prediction with sharing – Policies try to compensate for waits Goal is to build a quantitative “performance signature” to estimate execution time under any given network conditions, and use it in a resource management prototype system Rice01, slide 15