Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Independent Component Analysis
NiC fMRI-methodology Journal Club
05 Dec. 2008
Overview
• Theory
– PCA
– ICA
• Application
– Data reduction
– Spatial vs. Temporal ICA
– Group-ICA
There will be math …
Non-fMRI example
• The cocktail-party problem
– Many people are speaking in a room
– Given a number of microphone
recordings from different locations,
can the various sources
be reconstructed?
Non-fMRI example
• Signals are collected in row-vectors
Sources
– r1 = 0.8∙s1+0.6∙s2
– r2 = 0.2∙s1+0.5∙s2
r1 0.8 0.6 s1
R A S
r
2 0.2 0.5 s2
Recordings
r2
s2
Non-fMRI example
s1
r1
Non-fMRI example
•
•
•
Assumptions
–
Recordings consist of linearly transformed sources (‘weighted averages’)
–
Original sources are completely unrelated
•
Uncorrelated
•
Independent
Then
–
Sources can be estimated by linearly (back-)transforming the recordings
–
The optimal transformation makes the source estimates ‘as unrelated as possible’
•
Minimize correlations
•
Maximize independence
In fMRI
–
Sources of interest are the various ‘brain systems’
–
Recordings are the acquisition volumes and/or voxel time courses
Non-fMRI example
S1
R1
S2
R2
Theory
PCA
ICA
PCA
• Recordings typically are not uncorrelated
R
r1 r2T
r r r r
1
T
1
2
T
2
0 r1 r2T 0
• Goal: find a transformation matrix V such that transformed
signals Y=V∙R are uncorrelated
y1 y T2 v1 R v 2 R v1 R R T v T2 0
T
• If the transformed signals are properly normalized (|yi|=1)
Y Y V R R V I R R V V
T
T
T
T
T
1
PCA
• Q: how do we find V such that
V V R R
T
T 1
(note that R∙RT equals the covariance matrix)
• A: use the singular value decomposition (SVD)
R U L Λ U TR
such that
V T V U L Λ 2 U TL
resulting in a solution
V Λ 1 U TL
PCA
•
In pictures, PCA performes ‘sphering’
– Fit the data cloud with an ellipsoidal function
– Rotate the ellipsoid such that its axes coincide with the coordinate axes
– Squeeze/stretch the ellipsoid to make it spherical
Rotation
Squeezing/stretching
y2
r2
x2
Recordings
r1
x1
y1
R
X U TL R
Y Λ 1 U TL R
PCA
•
By means of a linear transformation of
the recordings r1 and r2, we found
signals y1 and y2 that are normalized
and completely uncorrelated
•
Yet, these signals do not at all
and s2, and are obviously still mixtures
•
y2
correspond with the original sources s1
However, any rotation will preserve
uncorrelatedness
•
So, how the determine the ‘best’
rotation?
y1
ICA
• Statistical independence
– Knowledge of the value of y1 for a sample does not affect the
statistical distribution of the values of y2
P y2 | y1 P y2
– Equivalently, the joint probability distribution is the product of the
marginal probability ditributions
P y1 , y2 P y1 P y2
– As a result, loosely speaking, all non-gaussian ‘features’ of the
probability distribution are either caused by P(y1) or P(y2), but not by
both, and therefore lie parallel with the coordinate axes
ICA
• Independence implies uncorrelatedness
(But the reverse is not true!)
• Therefore, maximally independent signals are also likely
approximately uncorrelated
• This suggests performing PCA first, to decorrelate the
signals, and determining a suitable rotation next that
optimizes independence but (automatically) preserves
uncorrelatedness
ICA
• A simple idea:
Penalize all data points with a
penalty P=(y12∙y22)
(i.e., for points on any axis)
y2
– No penalty if y1=0 or y2=0
– Positive penalty for points in
any of the four quadrants
– Increasing penalty for points
that are further away from
the axes
y1
ICA
• Minimize the penalty over a
search space that consists of
• The solution is determined up
z2
all rotations
to
– Component order
– Component magnitude
– Component sign
z1
ICA
• Average penalty P
P
1
N
y
2
1, j
y2,2 j
j
• Rotations preserve the euclidean distance to the origin
1
N
y
2
1, j
y
2
2, j
2
C
j
• It follows that minimizing P is equivalent to maximizing K
K C 2P
1
N
y
4
1, j
j
y2,4 j
• K is closely related to kurtosis (‘peakiness’)
ICA
• Central limit theorem
– A mixture of a sufficiently large number of independent random
variables (each with finite mean and variance) will be approximately
normally distributed
• This suggests that the original sources are more non-gaussian
than the mixtures
– Maximum non-gaussianity is the criterion to use to determine the
optimal rotation!
– This cannot be successful if sources are normally distributed
– QuartiMax employs kurtosis as a measure of non-gaussianity
ICA
• If some sources are platykurtotic, the method may fail
• Therefore, maximize
K E yij4 E ij4
2
ICA
• Due to the fourth power, the method is sensitive to outliers
• Therefore, choose any other function G
K E G yij E G ij
– G(y) = y4
– G(y) = log(cosh(y))
– G(y) = 1-exp(-y2)
• FastICA [Hyvärinen]
2
ICA
• Some non-gaussian distributions will happen to have K=0
• Therefore, use mutual information expressed in terms of
negentropy
K E log P yij
E log P
• InfoMax [Bell & Sejnovski]
ij
2
ICA
• Entropy-calculations require approximation of the
probability density function P itself
• Therefore, expand negentropy in terms of lower-order
cumulants (generalized variance/skewness/kurtosis/…)
K E Qijkl y E Qijkl
• JADE [Cardoso]
2
ICA
MatLab code
% Generate signals
S = wavread('D:\sources.wav')';
A = [0.8,0.6;0.2,0.5];
R = A*S;
clear S,A;
% PCA
[UL,LAMBDA,UR] = svd(R,'econ');
V = inv(LAMBDA)*UL';
Y = V*R;
% ICA
Z = rotatefactors(Y','Method','quartimax')';
Z = icatb_fastICA(Y,'approach','symm','g','tanh');
[d1,d2,Z] = icatb_runica(Y);
Z = icatb_jade_opac(Y);
ICA
• In practice, all mentioned
algorithms have been
QuartiMax
InfoMax
FastICA
JADE [?]
reported to perform
satisfactorily
– QuartiMax
– FastICA
– InfoMax
– JADE
ICA
• In practice, all mentioned
algorithms have been
QuartiMax
InfoMax
FastICA
JADE
reported to perform
satisfactorily
– QuartiMax
– FastICA
– InfoMax
– JADE
Application
Data reduction
Spatial vs. Temporal ICA
Group-ICA
Data reduction
•
fMRI-data are gathered in a
matrix Y
Y
Data reduction
•
fMRI-data are gathered in a
matrix Y
Data are decomposed into
time
comp
principal components by means
Ux
∙
Λ
time
comp
=
comp
Y
voxels
of SVD
comp
voxels
•
∙
Ut
Data reduction
•
fMRI-data are gathered in a
matrix Y
Data are decomposed into
time
comp
principal components by means
components are retained
=
Ux
comp
Only the first few strongest
Y
voxels
•
voxels
of SVD
comp
∙
Λ
time
comp
•
∙
Ut
Data reduction
•
fMRI-data are gathered in a
matrix Y
•
of SVD
λ2
×
×
λ3
×
×
Only the first few strongest
components are retained
•
×
Data are decomposed into
principal components by means
•
λ1 ×
Each component is the product of
– a coefficient
– a spatial map
– a time course
…
residuals
+
Y
Temporal vs. Spatial ICA
Temporal ICA
–
Uncorrelated spatial maps
and
–
•
Acquisitions
PCA decomposition results in
Uncorrelated time courses
Voxel j
•
Component
map
ICA rotation results in
–
Maximally independent time courses:
Voxel i
tICA
Spatial ICA
or
sICA
•
Voxels
Maximally independent spatial maps:
Some methods employ criteria in both
domains
Acquisition j
–
Component
time course
Acquisition i
Temporal vs. Spatial ICA
• PCA
Y
=
Ux
∙
Λ
∙
U
St
Ux
∙
Λ
∙
A∙
St
=
Vx ∙
St
Sx
∙
A
∙
Λ∙
U
St
=
Sx ∙
V
St
• tICA
Y
=
• sICA
Y
=
Temporal vs. Spatial ICA
•
Temporal ICA
– Components have independent temporal dynamics:
“Strength of one component at a particular moment in time does not provide
information on the strength of other components at that moment”
– Components may be correlated/dependent in space
– Popular for cocktail party problem
•
Spatial ICA
– Components have independent spatial distributions:
“Strength of one component in particular voxel does not provide information on
the strength of other components in that voxel”
– Components may be correlated/dependent in time
– Popular for fMRI
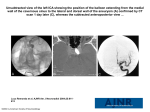
Temporal vs. Spatial ICA
Calhoun et al., 2001
Group-ICA
•
Some problems at the subject level become even more pressing at the
group level
– Independent components have no natural interpretation
– Independent components have no meaningful order
– The magnitude of independent component maps and time courses is
undetermined
– The sign of independent component maps and time courses is arbitrary
•
For group level analyses, some form of ‘matching’ is required
– Assumptions
• Equal coefficients across subjects?
• Equal distributions across subjects?
• Equal dynamics across subjects?
λi ×
×
Group-ICA
•
Method I: Averaging
– E.g.: Schmithorst et al., 2004
•
Principle
– Average the data sets of all subjects before ICA
– Perform ICA on the mean data
•
Key points
– All subjects are assumed to have identical components
• Equal coefficients
>
homogeneous population
• Equal distributions
>
comparable brain organization
• Equal dynamics
>
fixed paradigm; resting state impossible
– Statistical assessment at group level
• Enter ICA time courses into linear regression model (back-projection)
Group-ICA
•
Method II: Tensor-ICA
–
•
E.g.: Beckmann et al., 2005
Principle
–
Stack subjects’ data matrices along a third dimension
–
Decompose data tensor into product of (acquisition-dependent) time course, (voxeldependent) maps, and (subject-dependent) loadings
•
Key points
–
–
Components may differ only in strength
•
Unequal coefficients
>
inhomogeneous population
•
Equal distributions
>
comparable brain organization
•
Equal dynamics
>
fixed paradigm; resting state impossible
Statistical assessment at group level
•
Components as a whole
Group-ICA
•
Method III: Spatial concatenation
–
•
•
E.g.: Svensén et al., 2002
Principle
–
Concatenate subjects’ data matrices along the spatial dimension
–
Perform ICA on aggregate data matrix
–
Partition resulting components into individual maps
Key points
–
–
Components may differ in strength and distribution
•
Unequal coefficients
>
inhomogeneous population
•
Unequal distributions
>
brain plasticity
•
Equal dynamics
>
fixed paradigm; resting state impossible
Statistical assessment at group level
•
Voxel-by-voxel SPMs
Group-ICA
•
Method IV: Temporal concatenation
–
•
•
E.g.: Calhoun et al., 2001
Principle
–
Concatenate subjects’ data matrices along the time dimension
–
Perform ICA on aggregate data matrix
–
Partition resulting components into individual time courses
Key points
–
–
Components may differ in strength and dynamics
•
Unequal coefficients
>
inhomogeneous population
•
Equal distributions
>
comparable brain organization
•
Unequal dynamics
>
flexible paradigm
Statistical assessment at group level
•
Components as a whole, from time course spectrum/power
•
Voxel-by-voxel SPMs, from back-projection (careful with statistics!)
Group-ICA
•
•
•
Method V: Retrospective matching
–
Subjective or (semi)automatic matching on basis of similarity between distribution maps and/or time courses
–
Also used to test the reproducibility of some stochastic ICA algorithms
–
Various principles, various authors
Principle
–
Perform ICA on individual subjects
–
Match similar individual components one-on-one across subjects
Key points
–
–
Components may differ in strength and dynamics
•
Unequal coefficients
>
inhomogeneous population
•
Unequal distributions
>
brain plasticity
•
Unequal dynamics
>
flexible paradigm
Statistical assessment at group level
•
Voxel-by-voxel SPMs (careful with scaling and bias!)
Conclusion
• ICA has the major advantage that it requires minimal assumptions
or prior knowledge
• However, interpretation of the meaning of components occurs
retrospectively and may be ambiguous
• Unfortunately, methods and statistics are not fully characterized
yet and still quite heavily under development
• Therefore - IMHO – independent component analysis is an
excellent tool for exploratory experiments, but should not be your
first choice for confirmatory studies