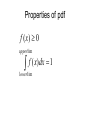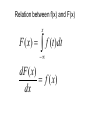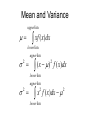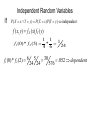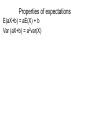Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Continuous Random Variables Chapter 5 Nutan S. Mishra Department of Mathematics and Statistics University of South Alabama Continuous Random Variable When random variable X takes values on an interval For example GPA of students X [0, 4] High day temperature in Mobile X ( 20,∞) Recall in case of discrete variables a simple event was described as (X = k) and then we can compute P(X = k) which is called probability mass function In case of continuous variable we make a change in the definition of an event. Continuous Random Variable Let X [0,4], then there are infinite number of values which x may take. If we assign probability to each value then P(X=k) 0 for a continuous variable In this case we define an event as (x-x ≤ X ≤ x+x ) where x is a very tiny increment in x. And thus we assign the probability to this event P(x-x ≤ X ≤ x+x ) = f(x) dx f(x) is called probability density function (pdf) Properties of pdf f ( x) 0 upper lim f ( x)dx 1 lower lim (cumulative) Distribution Function The cumulative distribution function of a continuous random variable is a F ( a ) P( X a ) f ( x)dx lower limit Where f(x) is the probability density function of x. b P(a x b) P(a x b) f ( x)dx a F (b) F (a) Relation between f(x) and F(x) x F ( x) f (t )dt dF ( x) f ( x) dx Mean and Variance upper lim xf ( x)dx lower lim upper lim 2 (x ) 2 f ( x)dx lower lim 2 upper lim 2 x f ( x ) dx lower lim 2 Exercise 5.2 To find the value of k 1 3 kx 1 0 1 4 x 1 L.H .S . k x 3 k[ ]10 k[ ] 1 4 4 0 k 4 Thus f(x) = 4x3 for 0<x<1 3/ 4 3 4 x P(1/4<x<3/4) = dx = 1/ 4 1 3 4 x P(x>2/3) = dx = 2/3 Exercise 5.7 P( x 3) F (3) 1 4 / 9 5 / 9 P(4 x 5) F (5) F (4) Exercise 5.13 1 1 1 x * 4 x dx 4 x dx 4 x dx 3 4 0 4 0 0 1 1 x * 4 x dx 4 x dx 2 2 0 3 2 5 0 2 Probability and density curves • P (a<Y<b): P(100<Y<150)=0.42 Useful link: http://people.hofstra.edu/faculty/Stefan_Waner/RealWorld/cprob/cprob2.html Normal Distribution X = normal random variate with parameters µ and σ if its probability density function is given by 1 2 2 f ( x) e ( x ) / 2 x 2 µ and σ are called parameters of the normal distribution http://www.willamette.edu/~mjaneba/help/normalcu rve.html Standard Normal Distribution The distribution of a normal random variable with mean 0 and variance 1 is called a standard normal distribution. -4 -3 -2 -1 0 1 2 3 4 Standard Normal Distribution • The letter Z is traditionally used to represent a standard normal random variable. • z is used to represent a particular value of Z. • The standard normal distribution has been tabularized. Standard Normal Distribution Given a standard normal distribution, find the area under the curve (a) to the left of z = -1.85 (b) to the left of z = 2.01 (c) to the right of z = –0.99 (d) to right of z = 1.50 (e) between z = -1.66 and z = 0.58 Standard Normal Distribution Given a standard normal distribution, find the value of k such that (a) P(Z < k) = .1271 (b) P(Z < k) = .9495 (c) P(Z > k) = .8186 (d) P(Z > k) = .0073 (e) P( 0.90 < Z < k) = .1806 (f) P( k < Z < 1.02) = .1464 Normal Distribution • Any normal random variable, X, can be converted to a standard normal random variable: z = (x – μx)/x Useful link: (pictures of normal curves borrowed from: http://www.stat.sc.edu/~lynch/509Spring03/25 Normal Distribution Given a random Variable X having a normal distribution with μx = 10 and x = 2, find the probability that X < 8. z -4 x -3 -2 -1 0 1 2 3 4 6 8 10 12 14 16 4 Relationship between the Normal and Binomial Distributions • The normal distribution is often a good approximation to a discrete distribution when the discrete distribution takes on a symmetric bell shape. • Some distributions converge to the normal as their parameters approach certain limits. • Theorem 6.2: If X is a binomial random variable with mean μ = np and variance 2 = npq, then the limiting form of the distribution of Z = (X – np)/(npq).5 as n , is the standard normal distribution, n(z;0,1). Exercise 5.19 -4 -3 -2 -1 0 1 2 3 4 1.5 P( x 1.5) e 1 / 2 t 2 dt Uniform distribution The uniform distribution with parameters α and β has the density function 1 f ( x) for x 0 elsewhere Exponential Distribution: Basic Facts • Density e x , x 0 f x , 0 0, x 0 • CDF 1 e x , x 0 F x 0, x 0 1 • Mean E X • Variance Var X 1 2 Key Property: Memorylessness P X s t X t P X s for all s, t 0 • Reliability: Amount of time a component has been in service has no effect on the amount of time until it fails • Inter-event times: Amount of time since the last event contains no information about the amount of time until the next event • Service times: Amount of remaining service time is independent of the amount of service time elapsed so far Exponential Distribution The exponential distribution is a very commonly used distribution in reliability engineering. Due to its simplicity, it has been widely employed even in cases to which it does not apply. The exponential distribution is used to describe units that have a constant failure rate. The single-parameter exponential pdf is given by: where: ·λ · · · = constant failure rate, in failures per unit of measurement, e.g. failures per hour, per cycle, etc. λ = .1/m m = mean time between failures, or to a failure. T = operating time, life or age, in hours, cycles, miles, actuations, etc. This distribution requires the estimation of only one parameter, , for its application. Joint probabilities For discrete joint probability density function (joint pdf) of a k-dimensional discrete random variable X = (X1, X2, …,Xk) is defined to be f(x1,x2,…,xk) = P(X1 = x1, X2 = x2 , …,Xk = xk) for all possible values x = (x1,x2,…,xk) in X. Let (X, Y) have the joint probability function specified in the following table x/y 0 2 1/24 3 3/24 4 1/24 5 1/24 6/24 1 2/24 2/24 6/24 2/24 12/24 2 2/24 1/24 2/24 1/24 6/24 5/24 6/24 9/24 4/24 24/24 Joint distribution Consider f (0,2) 1 / 24 .042 P( x 1, y 2) 1 24 2 24 P( x 2, y 3) 5 P( x 1, y 4) 2 f (1,4) 6 / 24 0.25 24 2 P( x 0, y 2) 2 6 24 24 24 24 6 2 P( y 4 | x 2) 2 12 P( y 4 | x 1) 6 12 P( y 2 | x 1) 2 12 24 11 24 24 12 P( y 3 | x 1) 2 3 10 4 24 24 24 Joint probability distribution Joint Probability Distribution Function f(x,y) > 0 f ( x, y) 1 x y P[( X , Y ) A] f ( x, y) ( x , y )A Marginal pdf of x & y f X ( x ) f ( x, y ) y fY ( y) f ( x, y) here is an example x f ( x, y ) x y 21 x =1, 2, 3 y = 1, 2 Marginal pdf of x & y Consider the following example x y y 1 21 2 f X ( x) f ( x, y) P( X x) y x 1 x 2 2x 3 21 21 21 fY ( y ) x x = 1,2,3 x y f ( x, y ) P(Y y ) x 1 21 3 1 y 2 y 3 y 6 3y 21 21 21 21 y = 1,2 Independent Random Variables If P( X x Y y ) P( X x) P(Y y ) independen t f ( x, y) f X ( x) fY ( y) f1 (0) * f 2 (5) f1 (0) * f 2 (2) 6 5 24 24 1 1 * 1 24 4 6 30 576 .052 dependent Properties of expectations for a discrete pdf, f(x), The expected value of the function u(x), E[u(X)] = xS u ( x) f ( x) Mean = = E[X] = xS x f ( x) Variance = Var(X) = 2 = x2=E[(X-)2] = E[X2] - 2 For a continuous pdf, f(x) E(X) = Mean of X = x f ( x)dx S E[(X-)2] = E(X2) -[E(X)]2 = Variance of X = (x ) 2 S f ( x)dx Properties of expectations E(aX+b) = aE(X) + b Var (aX+b) = a2var(X) Mean and variance of Z Z Z x x E(Z) = 0 and var(Z) = 1 Is called standardized variable x ax b 1 Linear combination of two independent variables Let x1 and x2 be two Independent random variables then their linear combination y = ax1+bx2 is a random variable. E(y) = aE(x1)+bE(x2) Var(y) = a2var(x1)+b2var(x2) Mean and variance of the sample mean x1, x2,…xn are independent identically distributed random variables (i.e. a sample coming from a population) with common mean µ and common variance σ2 The sample mean is a linear combination of these i.i.d. variables and hence itself is a random variable x1 x2 ... xn 1 1 1 x x1 x2 ... xn n n n n E ( x ) denoted by x var( x ) 2 n