Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Go (programming language) wikipedia , lookup
Flow-based programming wikipedia , lookup
Operational transformation wikipedia , lookup
Buffer overflow wikipedia , lookup
Buffer overflow protection wikipedia , lookup
Virtual synchrony wikipedia , lookup
Join-pattern wikipedia , lookup
Algorithmic skeleton wikipedia , lookup
Application Interface Specification wikipedia , lookup
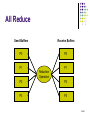
MPI Programming Hamid Reza Tajozzakerin Sharif University of technology 1/44 Introduction Massage-Passing interface (MPI) A library of functions and macros Objectives: define an international long-term standard API for portable parallel applications and get all hardware vendors involved in implementations of this standard; define a target system for parallelizing compilers Can be used in C,C++,FORTRAN The MPI Forum (http://www.mpi-forum.org/) brings together all contributing parties 2/44 The User’s View Processor Processor Process Process Process Communication System (MPI) Process Processor Processor Process Process Process Process 3/44 Programming with MPI General MPI Programs Include the lib file mpi.h (or however called) into the source code Initialize the MPI environment: MPI_Init (&argc, &argv) Must be called and only once before any other MPI functions At the end of the program: MPI_Finalize( ); Cleans up any unfinished business left by MPI 4/44 Programming with MPI (cont.) Get your own process ID (rank): MPI_Comm_rank (MPI_Comm comm, int rank) First argument is a communicator Communicator: a collection of processes send message to each other Get the number of processes (including oneself): MPI_Comm_size (MPI_comm comm, int size) Size: number of processes in comm 5/44 What is message? Message: Data + Envelope Envelope: Additional information to message be communicated successfully Envelop contains: Rank of sender (who send the message) Rank of receiver (who received the message) No wildcard for dest A tag: Can be a wildcard: MPI_ANY_SOURCE used to distinguish messages received from a single process Can be a wildcard: MPI_ANY_TAG Communicator 6/44 Point-to-Point Communication a send command can be Blocking: continuation possible after passing to communication system has been completed (buffer can be re-used) non-blocking: immediate continuation possible (check buffer whether message has been sent and buffer can be re-used) 7/44 Point-to-Point Communication (Cont.) Four types of point-to-point send operations, each of them available in a blocking and a non-blocking variant Standard (regular) send: MPI_SEND or MPI_ISEND Buffered send: MPI_BSEND or MPI_IBSEND Asynchronous; the system decides whether or not to buffer messages to be sent Successful completion may depend on matching receive Asynchronous, but buffering of messages to be sent by the system is enforced Synchronous send: MPI_SSEND or MPI_ISSEND Synchronous, i.e. the send operation is not completed before the receiver has started to receive the message 8/44 Point-to-Point Communication (Cont.) Ready send: MPI_RSEND or MPI_IRSEND Send may started only if matching receive has been posted: if no corresponding receive operation is available, the result is undefined Could be replaced by standard send with no effect other than performance Meaning of blocking or non-blocking (variants with ‘I’): Blocking: send operation is not completed before the send buffer can be reused Non-blocking: immediate continuation, and the user has to make sure that the buffer won’t be corrupted 9/44 Point-to-Point Communication (cont.) one receive function: Blocking MPI_Recv : Non-blocking MPI_IRecv : Receive operation is completed when the message has been completely written into the receive buffer Continuation immediately after the receiving has begun Can be combined with four send modes 10/44 Point-to-Point Communication (Cont.) Syntax: MPI_SEND(buf, count, datatype, dest, tag, comm) MPI_RECV(buf, count, datatype, source, tag, comm, status) where Void *buf pointer to the buffer’s begin int count number of data objects int source process ID of the sending process int dest process ID of the destination process int tag ID of the message MPI_Datatype data type of the data objects MPI_Comm comm communicator (see later) MPI_Status *status object containing message information In the non-blocking versions, there’s one additional argument complete (request) for checking the completion of the 11/44 communication. Test Message Arrived MPI_Buffer_attach(...): MPI_Probe(...)/ MPI_Iprobe(...): checks whether a send or receive operation is completed MPI_Wait(...): Blocking/ non-blocking test whether a message has arrived without actually receive them MPI_Test(...): lets MPI provide a buffer causes the process to wait until a send or receive operation has been completed MPI_Get_count(...): provides the length of a message received 12/44 Data Types Standard MPI data types: MPI_CHAR MPI_SHORT MPI_INT MPI_LONG MPI_UNSIGNED MPI_FLOAT MPI_DOUBLE MPI_LONG_DOUBLE MPI_BYTE(8-binary digit) MPI_PACKED 13/44 Grouping Data Why? The fewer messages sent, better overall performance Three mechanisms: Count Parameter: group data having the same basic type as an array Derived Types Pack/Unpack 14/44 Building Derived Types Specify types of members of the derived type Number of elements of each type Calculate addresses of members Calculate displacements: Relative location Create the derived type MPI_Type_Struct(…) Commit it MPI_Type_commit(…) 15/44 Other Derived Data type constructors MPI_Type_contiguous(...): MPI_Type_vector(...): Constructs an array consisting of count elements of type old type belong to contiguous memory constructs an MPI array with element-to-element distance stride MPI_Type_ indexed(...): constructs an MPI array with different block lenghts 16/44 Packing and Unpacking Elements of a complex data structure can be packed, sent, and unpacked again element by element: expensive and error-prone Pack: store noncontiguous data in contiguous memory location Unpack: copy data from a contiguous buffer into noncontiguous memory locations MPI functions for explicit packing and unpacking: MPI_Pack(...): Packs data into a buffer MPI_Unpack(...): unpacks data from the buffer 17/44 Collective Communication Why? Many applications require not only a point-to-point communication, but also collective communication operations Collective communication: Broadcast Gather Scatter All-to-All Reduce 18/44 Broadcast Send Buffers Receive Buffers P0 P0 P1 P1 P2 P2 P3 P3 19/44 Gather Send Buffers Receive Buffers P0 P0 P1 P1 P2 P2 P3 P3 20/44 Scatter Send Buffers Receive Buffers P0 P0 P1 P1 P2 P2 P3 P3 21/44 All to All Send Buffers Receive Buffers A B A B C D C D 22/44 Reduce Send Buffers Receive Buffers P0 P0 P1 P1 Reduction Operation P2 P2 P3 P3 23/44 All Reduce Send Buffers Receive Buffers P0 P0 P1 P1 Reduction Operation P2 P2 P3 P3 24/44 Collective Communication (Cont.) Important application scenario: distribute the elements of vectors or matrices among several processors Some functions offered by MPI MPI_Barrier(...): synchronization barrier: process waits for the other group members; when all of them have reached the barrier, they can continue MPI_Bcast(...): sends the data to all members of the group given by a communicator (hence more a multicast than a broadcast) MPI_Gather(...): collects data from the group members 25/44 Collective Communication (Cont.) MPI_Allgather(...): gather-to-all: data are collected from all processes, and all get the collection MPI_Scatter(...): classical scatter operation: distribution of data among processes MPI_Reduce(...): executes a reduce operation MPI_Allreduce(...): executes a reduce operation where all processes get its result MPI_Op_create(...) and MPI_Op_free(...): defines a new reduce operation or removes it, respectively Note that all of the functions above are with respect to a communicator (hence not necessarily a global communication) 26/44 Process Groups and Communicators Messages are tagged for identification – message tag is message ID! Again: process groups for restricted message exchange and restricted collective communication Process groups are ordered sets of processes Each process is locally uniquely identified via its local (group-related) process ID or rank Ordering starts with zero, successive numbering Global identification of a process via the pair (process group, rank) 27/44 Process Groups and Communicators MPI communicators: concept for working with contexts Communicator = process group + message context MPI offers intra-communicators for collective communication within a process group and intercommunicators for (point-to-point) communication between two process groups Default (including all processes): MPI_COMM_WORLD MPI provides a lot of functions for working with process groups and communicators 28/44 Working with communicator To create new communicator Make a list of the processes in new communicator Get a group of processor in the list MPI_Comm_Group(…) Create new group MPI_Group_incl(…) Create actual communicator MPI_Comm_create(…) Note: To create several communicator simultaneously MPI_Comm_split(…) 29/44 Process Topologies Provide a convenient naming mechanism for processes of a group Assist the runtime system in mapping onto hardware Only for intra-communicator virtual topology: Set of process represented by a graph Most common topologies: mesh ,tori 30/44 Some useful functions MPI_Comm_rank(…) MPI_Comm_size Returns size of the group MPI_Comm_dup(..) Indicates rank of the process call it Cerates a new communicator with the same attributes of input communicator MPI_Comm_free(MPI_Comm *comm) set the handle to MPI_COMM_NULL 31/44 An example of Cartesian graph Upper number is rank lower pair is (row,col) coordinates 32/44 Cartesian Topology Functions MPI_Cart_create(…) Returns a handle to a new communicator to which the Cartesian topology information is attached MPI_Dimes_create(…) To select a balanced distribution of process MPI_Cartdim_get(…) Returns numbers of dimensions MPI_Cart_get(…) Returns information on topology MPI_Cart_sub(…) Partition Cartesian topology into a Cartesian of lower dimension MPI_Cart_coords(..), MPI_Cart_rank(…) 33/44 DCT Parallelism 34 Preliminary DCT: Discrete Cosine Transform 2D DCT: applied a 1D DCT twice 2D-DCT Equation Y C XC T X: N*N Matrix C: N*N matrix defined as: c mn k n cos [ (2m 1)n ] where k n 2N 1 / N when n 0 2 / N otherwise Y contains DCT coefficients Main operation is matrix mult 35/44 FOX’s Algorithm Multiply two square matrices Assume two matrices: A = (aij) and B = (bij) Matrices are from order n Assume number of processes are p: perfect square so: p=q2 n_bar = n/q: an integer Each process has a block of A and B as a matrices from order n/q 36/44 FOX’s Algorithm (Cont.) For example: p=9 and n=6 37/44 FOX’s Algorithm (Cont.) 38/44 FOX’s Algorithm (Cont.) The chosen submatrix in the r’th row is Ar,u where u= (r+step) mode q Example: at step=0 these multiplication done r=0: A00B00,A00B01,A00B02 r=1:A11B10,A11B11,A11B12 r=1:A22B20,A22B21,A22B22 Other mults done in other steps Processes communicate to each other so the mult of two matrices results 39/44 Implementation of algorithm Assume each row of processes as a communicator Assume each column of processes as a communicator MPI_Cart_sub(Com, var_coor, row_com); MPI_Cart_sub(grid->Com, var_coor,col_com)); Can use other functions: (more general communicator cunstruction functions) MPI_Comm_incl(com,q,rank,row_comm) MPI_Comm_create(comm,row_com,&row_com) 40/44 Implementation of MPI An MPI implementation consists of MPICH a subroutine library with all MPI functions include files for the calling application program some startup script (usually called mpirun, but not standardized) Support both operating systems: linux and Microsaft Windows Other implementation of MPI: Many different MPI implementation are available i.e: LAM Support MPI programming on networks of unix workstation See other implementation and their features: http://www.lam-mpi.org/mpi/implementations/fulllist.php 41/44 Implementation of MPI (Cont.) IMPI: Interoperable MPI A protocol specification to allow multiple MPI implementations to cooperate on a single MPI job. Any correct MPI program will run correctly under IMPI Divided into four parts: Startup/shutdown protocols Data transfer protocol Collective algorithm A centralized IMPI conformance testing methodology 42/44 Extensions to MPI External Interfaces One-sided Communication Dynamic Resource Management Extended Collective Bindings Real Time Some of these features are still subject to change 43/44 Question? 44/44