Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Neural modeling fields wikipedia , lookup
Machine learning wikipedia , lookup
Gene expression programming wikipedia , lookup
Pattern recognition wikipedia , lookup
History of artificial intelligence wikipedia , lookup
Hierarchical temporal memory wikipedia , lookup
Artificial Intelligence
Chapter 20.5: Neural Networks
Michael Scherger
Department of Computer Science
Kent State University
November 11, 2004
AI: Chapter 20.5: Neural
Networks
1
Contents
• Introduction
• Simple Neural Networks for Pattern
Classification
• Pattern Association
• Neural Networks Based on Competition
• Backpropagation Neural Network
November 11, 2004
AI: Chapter 20.5: Neural
Networks
2
Introduction
• Much of these notes come from
Fundamentals of Neural Networks:
Architectures, Algorithms, and Applications
by Laurene Fausett, Prentice Hall,
Englewood Cliffs, NJ, 1994.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
3
Introduction
• Aims
– Introduce some of the fundamental
techniques and principles of neural network
systems
– Investigate some common models and their
applications
November 11, 2004
AI: Chapter 20.5: Neural
Networks
4
What are Neural Networks?
•
Neural Networks (NNs) are networks of neurons, for example, as found
•
Artificial Neurons are crude approximations of the neurons found in
•
Artificial Neural Networks (ANNs) are networks of Artificial Neurons, and
•
From a practical point of view, an ANN is just a parallel computational
system consisting of many simple processing elements connected together
in a specific way in order to perform a particular task.
•
One should never lose sight of how crude the approximations are, and how
over-simplified our ANNs are compared to real brains.
in real (i.e. biological) brains.
brains. They may be physical devices, or purely mathematical constructs.
hence constitute crude approximations to parts of real brains. They may be
physical devices, or simulated on conventional computers.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
5
Why Study Artificial Neural
Networks?
•
They are extremely powerful computational devices (Turing equivalent,
universal computers)
•
Massive parallelism makes them very efficient
•
They can learn and generalize from training data – so there is no need for
enormous feats of programming
•
They are particularly fault tolerant – this is equivalent to the “graceful
degradation” found in biological systems
•
They are very noise tolerant – so they can cope with situations where
normal symbolic systems would have difficulty
•
In principle, they can do anything a symbolic/logic system can do, and
more. (In practice, getting them to do it can be rather difficult…)
November 11, 2004
AI: Chapter 20.5: Neural
Networks
6
What are Artificial Neural Networks
Used for?
• As with the field of AI in general, there are two
basic goals for neural network research:
– Brain modeling: The scientific goal of building
models of how real brains work
• This can potentially help us understand the nature of human
intelligence, formulate better teaching strategies, or better
remedial actions for brain damaged patients.
– Artificial System Building : The engineering goal
of building efficient systems for real world
applications.
• This may make machines more powerful, relieve humans of
tedious tasks, and may even improve upon human
performance.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
7
What are Artificial Neural Networks
Used for?
•
Brain modeling
•
Real world applications
– Models of human development – help children with developmental problems
– Simulations of adult performance – aid our understanding of how the brain
works
– Neuropsychological models – suggest remedial actions for brain damaged
patients
–
–
–
–
–
–
–
–
Financial modeling – predicting stocks, shares, currency exchange rates
Other time series prediction – climate, weather, airline marketing tactician
Computer games – intelligent agents, backgammon, first person shooters
Control systems – autonomous adaptable robots, microwave controllers
Pattern recognition – speech recognition, hand-writing recognition, sonar signals
Data analysis – data compression, data mining
Noise reduction – function approximation, ECG noise reduction
Bioinformatics – protein secondary structure, DNA sequencing
November 11, 2004
AI: Chapter 20.5: Neural
Networks
8
Learning in Neural Networks
• There are many forms of neural networks. Most
operate by passing neural ‘activations’ through a
network of connected neurons.
• One of the most powerful features of neural
networks is their ability to learn and
generalize from a set of training data. They
adapt the strengths/weights of the connections
between neurons so that the final output
activations are correct.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
9
Learning in Neural Networks
•
There are three broad types of learning:
1. Supervised Learning (i.e. learning with a
teacher)
2. Reinforcement learning (i.e. learning
with limited feedback)
3. Unsupervised learning (i.e. learning with
no help)
November 11, 2004
AI: Chapter 20.5: Neural
Networks
10
A Brief History
•
1943 McCulloch and Pitts proposed the McCulloch-Pitts neuron model
•
1949 Hebb published his book The Organization of Behavior, in which the Hebbian learning rule
was proposed.
•
1958 Rosenblatt introduced the simple single layer networks now called Perceptrons.
•
1969 Minsky and Papert’s book Perceptrons demonstrated the limitation of single layer
perceptrons, and almost the whole field went into hibernation.
•
1982 Hopfield published a series of papers on Hopfield networks.
•
1982 Kohonen developed the Self-Organizing Maps that now bear his name.
•
1986 The Back-Propagation learning algorithm for Multi-Layer Perceptrons was re-discovered and
the whole field took off again.
•
1990s The sub-field of Radial Basis Function Networks was developed.
•
2000s The power of Ensembles of Neural Networks and Support Vector Machines becomes
apparent.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
11
Overview
• Artificial Neural Networks are powerful computational systems
consisting of many simple processing elements connected together
to perform tasks analogously to biological brains.
• They are massively parallel, which makes them efficient, robust,
fault tolerant and noise tolerant.
• They can learn from training data and generalize to new situations.
• They are useful for brain modeling and real world applications
involving pattern recognition, function approximation, prediction, …
November 11, 2004
AI: Chapter 20.5: Neural
Networks
12
The Nervous System
• The human nervous system can be broken down into three stages
that may be represented in block diagram form as:
– The receptors collect information from the environment – e.g. photons
on the retina.
– The effectors generate interactions with the environment – e.g. activate
muscles.
– The flow of information/activation is represented by arrows – feed
forward and feedback.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
13
Levels of Brain Organization
•
The brain contains both large scale and small scale anatomical
structures and different functions take place at higher and lower
levels. There is a hierarchy of interwoven levels of organization:
1.
2.
3.
4.
5.
6.
7.
8.
•
Molecules and Ions
Synapses
Neuronal microcircuits
Dendritic trees
Neurons
Local circuits
Inter-regional circuits
Central nervous system
The ANNs we study in this module are crude approximations to
levels 5 and 6.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
14
Brains vs. Computers
•
There are approximately 10 billion neurons in the human cortex, compared
with 10 of thousands of processors in the most powerful parallel computers.
•
Each biological neuron is connected to several thousands of other neurons,
similar to the connectivity in powerful parallel computers.
•
Lack of processing units can be compensated by speed. The typical
operating speeds of biological neurons is measured in milliseconds (10-3 s),
while a silicon chip can operate in nanoseconds (10-9 s).
•
The human brain is extremely energy efficient, using approximately 10-16
joules per operation per second, whereas the best computers today use
around 10-6 joules per operation per second.
•
Brains have been evolving for tens of millions of years, computers have
been evolving for tens of decades.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
15
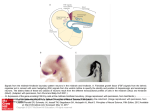
Structure of a Human Brain
November 11, 2004
AI: Chapter 20.5: Neural
Networks
16
Slice Through a Real Brain
November 11, 2004
AI: Chapter 20.5: Neural
Networks
17
Biological Neural Networks
November 11, 2004
•
The majority of neurons encode their
outputs or activations as a series of brief
electical pulses (i.e. spikes or action
potentials).
•
Dendrites are the receptive zones that
•
The cell body (soma) of the neuron’s
processes the incoming activations and
converts them into output activations.
•
4. Axons are transmission lines that send
activation to other neurons.
•
5. Synapses allow weighted transmission
of signals (using neurotransmitters)
between axons and dendrites to build up
large neural networks.
receive activation from other neurons.
AI: Chapter 20.5: Neural
Networks
18
The McCulloch-Pitts Neuron
• This vastly simplified model of real neurons is also known as a
Threshold Logic Unit :
– A set of synapses (i.e. connections) brings in activations from other
neurons.
– A processing unit sums the inputs, and then applies a non-linear
activation function (i.e. squashing/transfer/threshold function).
– An output line transmits the result to other neurons.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
19
Networks of McCulloch-Pitts
Neurons
• Artificial neurons have the same basic components as biological
neurons. The simplest ANNs consist of a set of McCulloch-Pitts
neurons labeled by indices k, i, j and activation flows between
them via synapses with strengths wki, wij:
November 11, 2004
AI: Chapter 20.5: Neural
Networks
20
Some Useful Notation
• We often need to talk about ordered sets of related numbers – we
call them vectors, e.g.
x = (x1, x2, x3, …, xn) , y = (y1, y2, y3, …, ym)
• The components xi can be added up to give a scalar (number), e.g.
s = x1 + x2 + x3 + … + xn = SUM(i, n, xi)
• Two vectors of the same length may be added to give another
vector, e.g.
z = x + y = (x1 + y1, x2 + y2, …, xn + yn)
• Two vectors of the same length may be multiplied to give a scalar,
e.g.
p = x.y = x1y1 + x2 y2 + …+ xnyn = SUM(i, N, xiyi)
November 11, 2004
AI: Chapter 20.5: Neural
Networks
21
Some Useful Functions
• Common activation functions
– Identity function
• f(x) = x
for all x
– Binary step function (with threshold ) (aka
Heaviside function or threshold function)
1 if x
f (x)
0 if x
November 11, 2004
AI: Chapter 20.5: Neural
Networks
22
Some Useful Functions
• Binary sigmoid
1
f ( x)
1 e x
• Bipolar sigmoid
2
g ( x) 2 f ( x) 1
1
x
1 e
November 11, 2004
AI: Chapter 20.5: Neural
Networks
23
The McCulloch-Pitts Neuron
Equation
• Using the above notation, we can now write down a
simple equation for the output out of a McCulloch-Pitts
neuron as a function of its n inputs ini :
November 11, 2004
AI: Chapter 20.5: Neural
Networks
24
Review
• Biological neurons, consisting of a cell body, axons,
dendrites and synapses, are able to process and transmit
neural activation
• The McCulloch-Pitts neuron model (Threshold Logic Unit)
is a crude approximation to real neurons that performs a
simple summation and thresholding function on
activation levels
• Appropriate mathematical notation facilitates the
specification and programming of artificial neurons and
networks of artificial neurons.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
25
Networks of McCulloch-Pitts
Neurons
• One neuron can’t do much on its own. Usually
we will have many neurons labeled by indices k,
i, j and activation flows between them via
synapses with strengths wki, wij:
November 11, 2004
AI: Chapter 20.5: Neural
Networks
26
The Perceptron
• We can connect any number of McCulloch-Pitts neurons
together in any way we like.
• An arrangement of one input layer of McCulloch-Pitts
neurons feeding forward to one output layer of
McCulloch-Pitts neurons is known as a Perceptron.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
27
Logic Gates with MP Neurons
•
We can use McCulloch-Pitts neurons to implement the basic logic gates.
•
All we need to do is find the appropriate connection weights and neuron
thresholds to produce the right outputs for each set of inputs.
•
We shall see explicitly how one can construct simple networks that perform
NOT, AND, and OR.
•
It is then a well known result from logic that we can construct any logical
function from these three operations.
•
The resulting networks, however, will usually have a much more complex
architecture than a simple Perceptron.
•
We generally want to avoid decomposing complex problems into simple
logic gates, by finding the weights and thresholds that work directly in a
Perceptron architecture.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
28
Implementation of Logical NOT,
AND, and OR
• Logical OR
x1
0
0
1
1
x2
0
1
0
1
November 11, 2004
y
0
1
1
1
x1
2
θ=2
y
x2
AI: Chapter 20.5: Neural
Networks
2
29
Implementation of Logical NOT,
AND, and OR
• Logical AND
x1
0
0
1
1
x2
0
1
0
1
November 11, 2004
y
0
0
0
1
x1
1
θ=2
y
x2
AI: Chapter 20.5: Neural
Networks
1
30
Implementation of Logical NOT,
AND, and OR
• Logical NOT
x1
0
1
y
1
0
x1
-1
θ=2
y
1
2
bias
November 11, 2004
AI: Chapter 20.5: Neural
Networks
31
Implementation of Logical NOT,
AND, and OR
• Logical AND NOT
x1
0
0
1
1
x2
0
1
0
1
November 11, 2004
y
0
0
1
0
x1
2
θ=2
y
x2
AI: Chapter 20.5: Neural
Networks
-1
32
Logical XOR
• Logical XOR
x1
0
0
1
1
x2
0
1
0
1
November 11, 2004
y
0
1
1
0
x1
?
y
x2
AI: Chapter 20.5: Neural
Networks
?
33
Logical XOR
• How long do we keep looking for a solution? We
need to be able to calculate appropriate
parameters rather than looking for solutions by
trial and error.
• Each training pattern produces a linear
inequality for the output in terms of the inputs
and the network parameters. These can be used
to compute the weights and thresholds.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
34
Finding the Weights Analytically
• We have two weights w1 and w2 and the
threshold q, and for each training pattern
we need to satisfy
November 11, 2004
AI: Chapter 20.5: Neural
Networks
35
Finding the Weights Analytically
• For the XOR network
– Clearly the second and third inequalities are incompatible with
the fourth, so there is in fact no solution. We need more
complex networks, e.g. that combine together many simple
networks, or use different activation/thresholding/transfer
functions.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
36
ANN Topologies
• Mathematically, ANNs can be represented as weighted directed
graphs. For our purposes, we can simply think in terms of
activation flowing between processing units via one-way
connections
– Single-Layer Feed-forward NNs One input layer and one output
layer of processing units. No feed-back connections. (For example, a
simple Perceptron.)
– Multi-Layer Feed-forward NNs One input layer, one output layer,
and one or more hidden layers of processing units. No feed-back
connections. The hidden layers sit in between the input and output
layers, and are thus hidden from the outside world. (For example, a
Multi-Layer Perceptron.)
– Recurrent NNs Any network with at least one feed-back connection. It
may, or may not, have hidden units. (For example, a Simple Recurrent
Network.)
November 11, 2004
AI: Chapter 20.5: Neural
Networks
37
ANN Topologies
November 11, 2004
AI: Chapter 20.5: Neural
Networks
38
Detecting Hot and Cold
• It is a well-known and interesting psychological
phenomenon that if a cold stimulus is applied to
a person’s skin for a short period of time, the
person will perceive heat.
• However, if the same stimulus is applied for a
longer period of time, the person will perceive
cold. The use of discrete time steps enables the
network of MP neurons to model this
phenomenon.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
39
Detecting Hot and Cold
• The desired response of the system is that “cold
is perceived if a cold stimulus is applied for two
time steps”
– y2(t) = x2(t-2) AND x2(t-1)
• It is also required that “heat be perceived if
either a hot stimulus is applied or a cold stimulus
is applied briefly (for one time step) and then
removed”
– y1(t) = {x1(t-1)} OR {x2(t-3) AND NOT x2(t-2)}
November 11, 2004
AI: Chapter 20.5: Neural
Networks
40
Detecting Heat and Cold
Heat
2
x1
-1
y1
2
z1
2
Cold
x2
2
z2
1
y2
1
November 11, 2004
AI: Chapter 20.5: Neural
Networks
41
Detecting Heat and Cold
Heat
0
Apply Cold
Cold
November 11, 2004
1
AI: Chapter 20.5: Neural
Networks
42
Detecting Heat and Cold
Heat
0
Remove Cold
Cold
November 11, 2004
0
0
1
AI: Chapter 20.5: Neural
Networks
43
Detecting Heat and Cold
Heat
0
1
Cold
November 11, 2004
0
AI: Chapter 20.5: Neural
Networks
0
44
Detecting Heat and Cold
Heat
1
Cold
0
November 11, 2004
AI: Chapter 20.5: Neural
Networks
Perceive Heat
45
Detecting Heat and Cold
Heat
0
Apply Cold
Cold
November 11, 2004
1
AI: Chapter 20.5: Neural
Networks
46
Detecting Heat and Cold
Heat
0
0
Cold
November 11, 2004
1
1
AI: Chapter 20.5: Neural
Networks
47
Detecting Heat and Cold
Heat
0
0
Cold
November 11, 2004
1
AI: Chapter 20.5: Neural
Networks
1
Perceive Cold
48
Example: Classification
• Consider the example
of classifying
airplanes given their
masses and speeds
• How do we construct
a neural network that
can classify any type
of bomber or fighter?
November 11, 2004
AI: Chapter 20.5: Neural
Networks
49
A General Procedure for Building
ANNs
•
1. Understand and specify your problem in terms of inputs and required outputs, e.g. for
classification the outputs are the classes usually represented as binary vectors.
•
2. Take the simplest form of network you think might be able to solve your problem, e.g. a
simple Perceptron.
•
3. Try to find appropriate connection weights (including neuron thresholds) so that the
network produces the right outputs for each input in its training data.
•
4. Make sure that the network works on its training data, and test its generalization by checking
its performance on new testing data.
•
5. If the network doesn’t perform well enough, go back to stage 3 and try harder.
•
6. If the network still doesn’t perform well enough, go back to stage 2 and try harder.
•
7. If the network still doesn’t perform well enough, go back to stage 1 and try harder.
•
8. Problem solved – move on to next problem.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
50
Building a NN for Our Example
• For our airplane classifier example, our inputs can be direct
encodings of the masses and speeds
• Generally we would have one output unit for each class, with
activation 1 for ‘yes’ and 0 for ‘no’
• With just two classes here, we can have just one output unit, with
activation 1 for ‘fighter’ and 0 for ‘bomber’ (or vice versa)
• The simplest network to try first is a simple Perceptron
• We can further simplify matters by replacing the threshold by using
a bias
November 11, 2004
AI: Chapter 20.5: Neural
Networks
51
Building a NN for Our Example
November 11, 2004
AI: Chapter 20.5: Neural
Networks
52
Building a NN for Our Example
November 11, 2004
AI: Chapter 20.5: Neural
Networks
53
Decision Boundaries in Two
Dimensions
• For simple logic gate problems, it is easy
to visualize what the neural network is
doing. It is forming decision
boundaries between classes. Remember,
the network output is:
• The decision boundary (between out = 0
and out = 1) is at
w1in1 + w2in2 - θ= 0
November 11, 2004
AI: Chapter 20.5: Neural
Networks
54
Decision Boundaries in Two
Dimensions
In two dimensions the decision
boundaries are always on
straight lines
November 11, 2004
AI: Chapter 20.5: Neural
Networks
55
Decision Boundaries for AND and
OR
November 11, 2004
AI: Chapter 20.5: Neural
Networks
56
Decision Boundaries for XOR
• There are two obvious
remedies:
– either change the transfer
function so that it has more
than one decision boundary
– use a more complex
network that is able to
generate more complex
decision boundaries
November 11, 2004
AI: Chapter 20.5: Neural
Networks
57
Logical XOR (Again)
• z1 = x1 AND NOT x2
• z2 = x2 AND NOT x1
x1
2
z1
2
-1
y
• y = z1 OR z2
-1
x2
November 11, 2004
AI: Chapter 20.5: Neural
Networks
2
z2
2
58
Decision Hyperplanes and Linear
Separability
• If we have two inputs, then the weights define a
decision boundary that is a one dimensional
straight line in the two dimensional input space
of possible input values
• If we have n inputs, the weights define a
decision boundary that is an n-1 dimensional
hyperplane in the n dimensional input space:
w1in1 + w2in2 + … + wninn - θ= 0
November 11, 2004
AI: Chapter 20.5: Neural
Networks
59
Decision Hyperplanes and Linear
Separability
• This hyperplane is clearly still linear (i.e.
straight/flat) and can still only divide the space
into two regions. We still need more complex
transfer functions, or more complex networks, to
deal with XOR type problems
• Problems with input patterns which can be
classified using a single hyperplane are said to
be linearly separable. Problems (such as XOR)
which cannot be classified in this way are said to
be non-linearly separable.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
60
General Decision Boundaries
• Generally, we will want to
deal with input patterns
that are not binary, and
expect our neural
networks to form complex
decision boundaries
• We may also wish to
classify inputs into many
classes (such as the three
shown here)
November 11, 2004
AI: Chapter 20.5: Neural
Networks
61
Learning and Generalization
• A network will also produce outputs for input patterns that it was
not originally set up to classify (shown with question marks), though
those classifications may be incorrect
• There are two important aspects of the network’s operation to
consider:
– Learning The network must learn decision surfaces from a set of
training patterns so that these training patterns are classified
correctly
– Generalization After training, the network must also be able to
generalize, i.e. correctly classify test patterns it has never seen before
• Usually we want our neural networks to learn well, and also to
generalize well.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
62
Learning and Generalization
• Sometimes, the training data may contain errors
(e.g. noise in the experimental determination of
the input values, or incorrect classifications)
• In this case, learning the training data perfectly
may make the generalization worse
• There is an important tradeoff between
learning and generalization that arises quite
generally
November 11, 2004
AI: Chapter 20.5: Neural
Networks
63
Generalization in Classification
• Suppose the task of our network is to learn a classification decision
boundary
• Our aim is for the network to generalize to classify new inputs
appropriately. If we know that the training data contains noise, we
don’t necessarily want the training data to be classified totally
accurately, as that is likely to reduce the generalization ability.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
64
Generalization in Function
Approximation
• Suppose we wish to recover a function for which we only have noisy
data samples
• We can expect the neural network output to give a better
representation of the underlying function if its output curve does not
pass through all the data points. Again, allowing a larger error on
the training data is likely to lead to better generalization.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
65
Training a Neural Network
• Whether our neural network is a simple Perceptron, or a
much more complicated multilayer network with special
activation functions, we need to develop a systematic
procedure for determining appropriate connection
weights.
• The general procedure is to have the network learn the
appropriate weights from a representative set of training
data
• In all but the simplest cases, however, direct
computation of the weights is intractable
November 11, 2004
AI: Chapter 20.5: Neural
Networks
66
Training a Neural Network
• Instead, we usually start off with random initial
weights and adjust them in small steps until the
required outputs are produced
• We shall now look at a brute force derivation of such an
iterative learning algorithm for simple Perceptrons.
• Later, we shall see how more powerful and general
techniques can easily lead to learning algorithms which
will work for neural networks of any specification we
could possibly dream up
November 11, 2004
AI: Chapter 20.5: Neural
Networks
67
Perceptron Learning
• For simple Perceptrons performing classification, we
have seen that the decision boundaries are hyperplanes,
and we can think of learning as the process of shifting
around the hyperplanes until each training pattern is
classified correctly
• Somehow, we need to formalize that process of “shifting
around” into a systematic algorithm that can easily be
implemented on a computer
• The “shifting around” can conveniently be split up into a
number of small steps.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
68
Perceptron Learning
• If the network weights at time t are wij(t), then
the shifting process corresponds to moving them
by an amount Dwij(t) so that at time t+1 we
have weights
wij(t+1) = wij(t) + Dwij(t)
• It is convenient to treat the thresholds as
weights, as discussed previously, so we don’t
need separate equations for them
November 11, 2004
AI: Chapter 20.5: Neural
Networks
69
Formulating the Weight Changes
• Suppose the target output of unit j is targj
and the actual output is outj = sgn(S ini
wij), where ini are the activations of the
previous layer of neurons (e.g. the
network inputs)
• Then we can just go through all the
possibilities to work out an appropriate set
of small weight changes
November 11, 2004
AI: Chapter 20.5: Neural
Networks
70
Perceptron Algorithm
• Step 0: Initialize weights and bias
– For simplicity, set weights and bias to zero
– Set learning rate a (0 <= a <= 1)
(h)
• Step 1: While stopping condition is false
do steps 2-6
• Step 2: For each training pair s:t do steps
3-5
• Step 3: Set activations of input units
xi = si
November 11, 2004
AI: Chapter 20.5: Neural
Networks
71
Perceptron Algorithm
• Step 4: Compute response of output unit:
y _ in b xi wi
i
if y_in
1
y 0 if - y_in
1
if y_in -
November 11, 2004
AI: Chapter 20.5: Neural
Networks
72
Perceptron Algorithm
• Step 5: Update weights and bias if an error
occurred for this pattern
if y != t
wi(new) = wi(old) + atxi
b(new) = b(old) + at
else
wi(new) = wi(old)
b(new) = b(old)
• Step 6: Test Stopping Condition
– If no weights changed in Step 2, stop, else, continue
November 11, 2004
AI: Chapter 20.5: Neural
Networks
73
Convergence of Perceptron
Learning
• The weight changes Dwij need to be applied
repeatedly – for each weight wij in the network,
and for each training pattern in the training set.
One pass through all the weights for the whole
training set is called one epoch of training
• Eventually, usually after many epochs, when all
the network outputs match the targets for all the
training patterns, all the Dwij will be zero and
the process of training will cease. We then say
that the training process has converged to a
solution
November 11, 2004
AI: Chapter 20.5: Neural
Networks
74
Convergence of Perceptron
Learning
• It can be shown that if there does exist a
possible set of weights for a Perceptron which
solves the given problem correctly, then the
Perceptron Learning Rule will find them in a
finite number of iterations
• Moreover, it can be shown that if a problem is
linearly separable, then the Perceptron Learning
Rule will find a set of weights in a finite number
of iterations that solves the problem correctly
November 11, 2004
AI: Chapter 20.5: Neural
Networks
75
Overview and Review
• Neural network classifiers learn decision boundaries from training
data
• Simple Perceptrons can only cope with linearly separable problems
• Trained networks are expected to generalize, i.e. deal appropriately
with input data they were not trained on
• One can train networks by iteratively updating their weights
• The Perceptron Learning Rule will find weights for linearly separable
problems in a finite number of iterations.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
76
Hebbian Learning
•
In 1949 neuropsychologist Donald Hebb postulated how biological neurons
learn:
– “When an axon of cell A is near enough to excite a cell B and repeatedly or
persistently takes part in firing it, some growth process or metabolic change
takes place on one or both cells such that A’s efficiency as one of the cells firing
B, is increased.”
•
In other words:
•
This rule is often supplemented by:
•
so that chance coincidences do not build up connection strengths.
– 1. If two neurons on either side of a synapse (connection) are activated
simultaneously (i.e. synchronously), then the strength of that synapse is
selectively increased.
– 2. If two neurons on either side of a synapse are activated asynchronously, then
that synapse is selectively weakened or eliminated.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
77
Hebbian Learning Algorithm
• Step 0: Initialize all weights
– For simplicity, set weights and bias to zero
• Step 1: For each input training vector do steps 2-4
• Step 2: Set activations of input units
xi = si
• Step 3: Set the activation for the output unit
y=t
• Step 4: Adjust weights and bias
wi(new) = wi(old) + yxi
b(new) = b(old) + y
November 11, 2004
AI: Chapter 20.5: Neural
Networks
78
Hebbian vs Perceptron Learning
• In the notation used for Perceptrons, the Hebbian
learning weight update rule is:
wij (new)= outj . ini
• There is strong physiological evidence that this type of
learning does take place in the region of the brain known
as the hippocampus.
• Recall that the Perceptron learning weight update rule
we derived was:
wij (new)= h. targj . ini
• There is some similarity, but it is clear that Hebbian
learning is not going to get our Perceptron to learn a set
of training data.
November 11, 2004
AI: Chapter 20.5: Neural
Networks
79
Adaline
• Adaline (Adaptive Linear Network) was
developed by Widrow and Hoff in 1960.
– Uses bipolar activations (-1 and 1) for its
input signals and target values
– Weight connections are adjustable
– Trained using the “delta rule” for weight
update
wij(new) = wij(old) + a(targj-outj)xi
November 11, 2004
AI: Chapter 20.5: Neural
Networks
80
Adaline Training Algorithm
• Step 0: Initialize weights and bias
– For simplicity, set weights (small random values) Set
learning rate a (0 <= a <= 1)
(h)
• Step 1: While stopping condition is false do
steps 2-6
• Step 2: For each training pair s:t do steps 3-5
• Step 3: Set activations of input units
xi = si
November 11, 2004
AI: Chapter 20.5: Neural
Networks
81
Adaline Training Algorithm
• Step 4: Compute net input to output unit
y_in = b + S xiwi
• Step 5: Update bias and weights
wi(new) = wi(old) + a(t-y_in)xi
b(new) = b(old) + a(t-y_in)
• Step 6: Test for stopping condition
November 11, 2004
AI: Chapter 20.5: Neural
Networks
82
Autoassociative Net
• The feed forward
autoassociative net has
the following diagram
• Useful for determining is
something is a part of the
test pattern or not
• Weight matrix diagonal is
usually zero…improves
generalization
• Hebbian learning if
mutually orthogonal
vectors are used
November 11, 2004
x1
y1
xi
yj
xn
ym
AI: Chapter 20.5: Neural
Networks
83
BAM Net
• Bidirectional Associative Net
November 11, 2004
AI: Chapter 20.5: Neural
Networks
84