Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
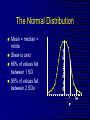
Measuring of Correlation Definition Correlation is a measure of mutual correspondence between two variables and is denoted by the coefficient of correlation. Applications and characteristics a) The simple correlation coefficient, also called the Pearson's product-moment correlation coefficient, is used to indicate the extent that two variables change with one another in a linear fashion. Applications and characteristics b) The correlation coefficient can range from - 1 to + 1 and is unites (Fig. A, B, C). Applications and characteristics c) When the correlation coefficient approaches - 1, a change in one variable is more highly, or strongly, associated with an inverse linear change (i.e., a change in the opposite direction) in the other variable. Applications and characteristics d) When the correlation coefficient equals zero, there is no association between the changes of the two variables. Applications and characteristics (e) When the correlation coefficient approaches +1, a change in one variable is more highly, or strongly, associated with a direct linear change in the other variable. Applications and characteristics A correlation coefficient can be calculated validly only when both variables are subject to random sampling and each is chosen independently. Correlation coefficient Correlation coefficient Correlation coefficient Types of correlation There are the following types of correlation (relation) between the phenomena and signs in nature: а) the reason-result connection is the connection between factors and phenomena, between factor and result signs. б) the dependence of parallel changes of a few signs on some third size. Quantitative types of connection functional one is the connection, at which the strictly defined value of the second sign answers to any value of one of the signs (for example, the certain area of the circle answers to the radius of the circle) Quantitative types of connection correlation - connection at which a few values of one sign answer to the value of every average size of another sign associated with the first one (for example, it is known that the height and mass of man’s body are linked between each other; in the group of persons with identical height there are different valuations of mass of body, however, these valuations of body mass varies in certain sizes – round their average size). Correlative connection Correlative connection foresees the dependence between the phenomena, which do not have clear functional character. Correlative connection is showed up only in the mass of supervisions that is in totality. The establishment of correlative connection foresees the exposure of the causal connection, which will confirm the dependence of one phenomenon on the other one. Correlative connection Correlative connection by the direction (the character) of connection can be direct and reverse. The coefficient of correlation, that characterizes the direct communication, is marked by the sign plus (+), and the coefficient of correlation, that characterizes the reverse one, is marked by the sign minus (-). By the force the correlative connection can be strong, middle, weak, it can be full and it can be absent. Estimation of correlation by coefficient of correlation Force of connection Complete Line (+) Reverse (-) +1 Strong From +1 to +0,7 Average from +0,7 to +0,3 from –0,7 to –0,3 Weak No connection From -1 to -0,7 from +0,3 to 0 from –0,3 to 0 0 0 Types of correlative connection By direction direct (+) – with the increasing of one sign increases the middle value of another one; reverse (-) – with the increasing of one sign decreases the middle value of another one; Types of correlative connection By character rectilinear - relatively even changes of middle values of one sign are accompanied by the equal changes of the other (arterial pressure minimal and maximal) curvilinear – at the even change of one sing there can be the increasing or decreasing middle values of the other sign. Average Values Mean: the average of the data sensitive to outlying data Median: the middle of the data not sensitive to outlying data Mode: most commonly occurring value Range: the difference between the largest observation and the smallest Interquartile range: the spread of the data commonly used for skewed data Standard deviation: a single number which measures how much the observations vary around the mean Symmetrical data: data that follows normal distribution (mean=median=mode) report mean & standard deviation & n Skewed data: not normally distributed (meanmedianmode) report median & IQ Range Average Values Limit is it is the meaning of edge variant in a variation row lim = Vmin Vmax Average Values Amplitude is the difference of edge variant of variation row Am = Vmax - Vmin Average Values Average quadratic deviation characterizes dispersion of the variants around an ordinary value (inside structure of totalities). Average quadratic deviation σ= d 2 n 1 simple arithmetical method Average quadratic deviation d=V-M genuine declination of variants from the true middle arithmetic Average quadratic deviation d σ=i n 2 p dp n method of moments 2 Average quadratic deviation is needed for: 1. Estimations of typicalness of the middle arithmetic (М is typical for this row, if σ is less than 1/3 of average) value. 2. Getting the error of average value. 3. Determination of average norm of the phenomenon, which is studied (М±1σ), sub norm (М±2σ) and edge deviations (М±3σ). 4. For construction of sigmal net at the estimation of physical development of an individual. Average quadratic deviation This dispersion a variant around of average characterizes an average quadratic deviation ( ) 2 nd n Coefficient of variation is the relative measure of variety; it is a percent correlation of standard deviation and arithmetic average. Terms Used To Describe The Quality Of Measurements Reliability is variability between subjects divided by inter-subject variability plus measurement error. Validity refers to the extent to which a test or surrogate is measuring what we think it is measuring. Measures Of Diagnostic Test Accuracy Sensitivity is defined as the ability of the test to identify correctly those who have the disease. Specificity is defined as the ability of the test to identify correctly those who do not have the disease. Predictive values are important for assessing how useful a test will be in the clinical setting at the individual patient level. The positive predictive value is the probability of disease in a patient with a positive test. Conversely, the negative predictive value is the probability that the patient does not have disease if he has a negative test result. Likelihood ratio indicates how much a given diagnostic test result will raise or lower the odds of having a disease relative to the prior probability of disease. Measures Of Diagnostic Test Accuracy Expressions Used When Making Inferences About Data Confidence Intervals - The results of any study sample are an estimate of the true value in the entire population. The true value may actually be greater or less than what is observed. Type I error (alpha) is the probability of incorrectly concluding there is a statistically significant difference in the population when none exists. Type II error (beta) is the probability of incorrectly concluding that there is no statistically significant difference in a population when one exists. Power is a measure of the ability of a study to detect a true difference. Multivariable Regression Methods Multiple linear regression is used when the outcome data is a continuous variable such as weight. For example, one could estimate the effect of a diet on weight after adjusting for the effect of confounders such as smoking status. Logistic regression is used when the outcome data is binary such as cure or no cure. Logistic regression can be used to estimate the effect of an exposure on a binary outcome after adjusting for confounders. Survival Analysis Kaplan-Meier analysis measures the ratio of surviving subjects (or those without an event) divided by the total number of subjects at risk for the event. Every time a subject has an event, the ratio is recalculated. These ratios are then used to generate a curve to graphically depict the probability of survival. Cox proportional hazards analysis is similar to the logistic regression method described above with the added advantage that it accounts for time to a binary event in the outcome variable. Thus, one can account for variation in follow-up time among subjects. Kaplan-Meier Survival Curves Why Use Statistics? Cardiovascular Mortality in Males 1.2 1 0.8 SMR 0.6 0.4 0.2 0 '35-'44 '45-'54 '55-'64 '65-'74 '75-'84 Bangor Roseto Descriptive Statistics Identifies patterns in the data Identifies outliers Guides choice of statistical test Percentage of Specimens Testing Positive for RSV (respiratory syncytial virus) Jul Aug Sep Oct Nov Dec Jan Feb Mar Apr May Jun South 2 2 5 7 20 30 15 20 15 8 4 3 North- 2 east West 2 3 5 3 12 28 22 28 22 20 10 9 2 3 3 5 8 25 27 25 22 15 12 2 2 3 2 4 12 12 12 10 19 15 8 Midwest Descriptive Statistics Percentage of Specimens Testing Postive for RSV 1998-99 35 30 25 20 15 10 5 0 South Northeast West Midwest Jul Sep Nov Jan Mar May Jul Distribution of Course Grades 14 12 10 Number of 8 Students 6 4 2 0 A A- B+ B B- C+ C Grade C- D+ D D- F Describing the Data with Numbers Measures of Dispersion • • • RANGE STANDARD DEVIATION SKEWNESS Measures of Dispersion • RANGE highest to lowest values STANDARD DEVIATION • how closely do values cluster around the mean value SKEWNESS • refers to symmetry of curve • • • Measures of Dispersion • RANGE highest to lowest values STANDARD DEVIATION • how closely do values cluster around the mean value SKEWNESS • refers to symmetry of curve • • • Measures of Dispersion • • • RANGE • highest to lowest values STANDARD DEVIATION • how closely do values cluster around the mean value SKEWNESS • refers to symmetry of curve The Normal Distribution Mean = median = mode Skew is zero 68% of values fall between 1 SD 95% of values fall between 2 SDs Mean, Median, Mode . 1 2