Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Nonparametric tests
Dr William Simpson
Psychology, University of Plymouth
1
Hypothesis testing
2
An experiment
•Volunteers sign up to weight loss expt
•Randomly assign half to low carb diet,
•half to low fat diet
•For each subject, find weight loss at end
•Low carb (C): 10,6,7,8,14 kg
•Low fat (F): 5,1,3,9,2 kg
3
Is it “significant”?
•We have:
•C<-c(10,6,7,8,14); mean(C) is 9
•F<-c(0,1,3,9,2); mean(F) is 3
•It’s obvious that low carb works better for
these subjects
•Statistical significance comes in when we
want to talk about people in general or if we
were to repeat the expt or if we wonder if low
fat diet “really works”
4
Hypothesis testing
• A random process was involved with
these data: random assignment
• Suppose that each person would lose the
same am’t of weight regardless of diet:
• 10,6,7,8,14,0,1,3,9,2
• By chance, the big weight losers were
assigned to the low carb diet and low
ones to low fat
• How likely is this sceptical idea?
5
Argument by contradiction
1. Assume the opposite of what we
want to show (“A”)
2. Show that this assumption leads to
absurd conclusion
3. Therefore initial assumption was
wrong; conclude “not A”
6
• Guy at party asserts: “solids are denser
than liquids”
• I disagree. I want to show that liquids
can be denser
• Assume the opposite of what I want to
show: solid H2O is denser than liquid
• If ice were denser, then it would sink in
water
• Ice does not sink
• Therefore ice is less dense than water
7
Null hypothesis testing
1. Assume the opposite of what we want
to show: Pattern of weight loss just
due to random assignment
2. Show that this assumption leads to
very unlikely conclusion
3. Therefore initial assumption was
wrong; weight loss NOT just random
assignment (ie due to diet)
8
Weight loss hypo testing
• Null hypo: Pattern of weight loss just
due to random assignment
• Calculate a “test statistic”
• Find prob of getting such an extreme
test statistic if null hypo is true
• If prob is low, reject null hypo. The
difference is “statistically significant”
9
“Nonparametric” tests
•
•
Some types of statistical test make assumptions
about the data distribution (e.g. Normal)
Nonparametric tests make no such assumptions
10
When useful?
1. Interval or ratio data but don’t want to make
assumption about distribution and small sample
size
2. Ordinal (rank) data
11
Ordinal data
•Data in graded categories. E.g. Likert scale:
1.Strongly disagree
2.Disagree
3.Neither agree or disagree
4.Agree
5.Strongly Agree
12
The tests
13
1. Two independent groups, between
subjects
14
a) Permutation test
•In weight loss expt, each subject assigned randomly
to one of two groups
•Null hypo says that our data are due simply to a
fluke of random assignment
15
•Permutation test: use computer to do many
random permutations. Compute diff in means each
time. Get distrib. See how likely it is to get diff as big
as ours:
•mean(C) – mean(F) = 9-3 =6kg
16
•What mean diff C-F should we get if just random
assignment?
•Should be near zero, but will vary.
17
•C:(10,6,7,8,14)
F:(0,1,3,9,2)
•
•9 6 3 1 0
2 14
•2 6 8 10 7
14 0
•7 3 9 14 0
6 10
•14 0 1 6 9
10 8
•… 1000s of times
7
9
1
2
10 8
3 1
8 2
7 3
diff
-4.4
1.2
1.2
0.0
18
•C<-c(10,6,7,8,14)
•F<-c(0,1,3,9,2)
•x<-c(C,F)
•nsim<-5000
•d<-rep(0,nsim)
•for (i in 1:nsim)
•{
•samp<-sample(x)
•d[i]<-mean(samp[1:5])-mean(samp[6:10])
•}
19
•hist(d)
20
•P(diff>=6)=.01
•sum(d>=6)/nsim
21
•If null hypo is true, chance of getting as big a mean
diff as we found (6 kg) or bigger is about .01
•This is a “low” prob. Conventional low probs are
.05, .01, .001
22
•Reject null hypo. Diff in weight loss not just due to
random assignment. Statistically significant (p=.01)
•“Those on the low-carb diet lost significantly less
weight (permutation test, p=.01)”
23
•Why do we say “p of getting diff as big as we got or
bigger”?
•Because we would also reject null if we had diff
bigger than 6
24
Tails
25
One-tailed
•
•
If we predicted that low fat would work better,
expect mean(C) – mean(F) >0
What is chance of getting C-F=6 or more?
26
•P(diff>=6) is righthand
•tail
27
Two-tailed
•Reviewer says: “Yeah, but it could have turned out
the other way, with C-F<0. You should have tested
for both possibilities”
28
•Can test both possibilities at same time.
•Reject null either if C-F is a big negative or a big
positive diff.
•Both tails of distribution.
29
30
•One-tailed or directional test: p=.0142
•sum(d>=6)/length(d)
•Two-tailed or nondirectional test: p=.034
•sum(d>=6)/length(d) + sum(d<= -6)/length(d)
31
One- vs two-tailed
•The p-value for 2-tailed will always be about twice
as big as for 1-tailed
•Harder to get statistical signif
•More convincing to reviewers
32
Fallibility of hypo tests
• When p-value is small (<.05), we reject null hypo
• BUT 5 times in 100, null hypo will actually be true!
Type I error
33
• Also possible to get a big p-value and fail to reject
null even if a real effect exists. Type II error
• Will happen if effect is small and if sample size is
small. Low power
34
b) Mann-Whitney-Wilcoxon test
•Suppose that we lump all the scores together
•C:(10,6,7,8,14)
F:(0,1,3,9,2)
•c,c,c,c,c,f,f,f,f,f
•10,6,7,8,14,0,1,3,9,2
35
•Now rank these scores
•If the diet had no effect on weight loss, expect the
average of the ranks associated with the Fs and with
the Cs to be similar.
36
•Pretend we originally had
•0 7 10 8 2 9 3 1 6 14
•Ranks:
•1 6 9 7 3 8 4 2 5 10
•mean(0,7,10,8,2)=5.2 mean(9,3,1,6,14)=5.8
37
•If the diet had an effect, expect the mean of the
ranks assoc with F to be markedly different from the
mean of the ranks assoc with C.
38
•Pretend we originally had
•0 1 2 3 6 7 8 9 10 14
•Ranks:
•1 2 3 4 5 6 7 8 9 10
•mean(0,1,2,3,6)=2.4 mean(7,8,9,10,14)=9.6
39
•Thus, if the average (or sum*) of the ranks
associated with the Cs or Fs is too large or small, we
have evidence that the null (weight loss same in
both) should be rejected
•*mean=sum/n, so same except for scale factor
40
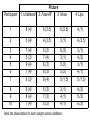
Weight loss example
•Low carb (C):
10,6,7,8, 14
•Low fat (F): 0, 1,3,9,2
Score
14
10
9
8
7
6
3
2
1
0
Rank
10
9
8
7
6
5
4
3
2
1
Group
C
C
F
C
C
C
F
F
F
F
Sum of ranks for Group C=
10 + 9 + 7 + 6 + 5 = 37
Sum of ranks for Group F =
8 + 4 + 3 + 2 + 1 = 18
41
•Using the summed ranks, calculate a statistic
(Mann-Whitney U)
•Distribution of U has been tabulated, given sample
sizes n1 and n2
•Look up p-value in table
42
•wilcox.test() Performs one- and two-sample Wilcoxon
tests on vectors of data; the latter is also known as
‘Mann-Whitney’ test.
•wilcox.test(C,F,alternative="greater")
•
Wilcoxon rank sum test
•data: C and F
•W = 22, p-value = 0.02778
•alternative hypothesis: true location shift is greater than
0
43
•wilcox.test(C,F,alternative="two.sided")
•
Wilcoxon rank sum test
•data: C and F
•W = 22, p-value = 0.05556
•alternative hypothesis: true location shift is not equal to 0
44
Note: different tests
•Not all tests give the same answers
•The permutation test gave smaller p-value (p=.034)
than the U test (p=0.056)
•Which one to believe? Use judgement
45
2. Paired groups, repeated measures,
within subjects
46
Repeated measures design
•Repeated measures: each subject participates in
conditions in random order
•Each subject serves as own control
•Data to be used: differences between each pair of
scores.
47
a) Permutation test
•Use computer to re-assign order many times. Each
time find mean of the diffs. Distribution of these
gives prob of getting mean diff as big as we observe
48
•Null hypo: each person has a pair of scores,
emitting one the first time tested and the other the
2nd time tested. These scores not related to
treatment (C or F)
49
•Randomly shuffle the scores. Find mean diff each
time.
•At end, have distrib of mean diffs
50
•If diff between diets just due to random assignment
of order, expect our mean of diffs to be near zero.
We had:
•C-F = (10,6,7,8, 14)- (0, 1,3,9,2)
•= 10, 5, 4, -1, 12; mean=6
51
•C<-c(10,6,7,8,14)
•F<-c(0,1,3,9,2)
•nsim<-5000
•d<-rep(0,nsim)
•for (i in 1:nsim)
•{
• ord<-(runif(5)>.5)*2-1 #flip sign of difference randomly
• samp<- (C-F)*ord
• d[i]<-mean(samp)
•}
52
hist(d)
53
•One-tailed or directional
test: p=.06
•sum(d>=6)/nsim
54
•Two-tailed or nondirectional
test: p=.12
•sum(d>=6)/nsim + sum(d<=
-6)/nsim
55
b) Wilcoxon signed-ranks test
•Repeated measures uses diffs
•C-F = (10,6,7,8, 14)- (0, 1,3,9,2)
•= 10, 5, 4, -1, 12
56
•Basic idea: if random order is all that determined
scores, expect diffs below and above 0 to balance
out
•Use signed ranks rather than raw scores
57
•Original diffs: 10, 5, 4, -1, 12
•Ranked by abs size: 4, 3, 2, 1, 5
•Then give any rank a minus sign if the original diff
had minus sign:
•Signed ranks: 4, 3, 2, -1, 5
58
•Find sum of the pos ranks
•Find |sum| of the neg ranks
•[under null hypo, expect them to be about equal]
•sum(4, 3, 2, 5)=14 |sum(-1)|= 1
59
•W= smaller of the 2 sums*
•sum(4, 3, 2, 5)=14 |sum(-1)|= 1
•W = 1
•Use table to get p-value
•*different methods of calculating W exist
60
•W=1, n=5
•1-tail, p=.05, need W=0
•Not signif
61
•C<-c(10,6,7,8,14)
•F<-c(0,1,3,9,2)
•wilcox.test(C,F,alternative="greater",paired=T)
•
Wilcoxon signed rank test
•data: C and F
•V = 14, p-value = 0.0625
•alternative hypothesis: true location shift is greater than
0
62
•C<-c(10,6,7,8,14)
•F<-c(0,1,3,9,2)
•> wilcox.test(C,F,alternative="two.sided",paired=T)
•
Wilcoxon signed rank test
•data: C and F
•V = 14, p-value = 0.125
•alternative hypothesis: true location shift is not equal to
0
63
Panic study
• Efficacy of internet therapy for panic disorder.
Journal of Behavior Therapy and Experimental
Psychiatry 37 (2006) 213–238
64
• Agoraphobic Cognitions Questionnaire: 14-item
self-report questionnaire. Rate how often each
thought occurs during a period of anxiety from 0
(never) to 4 (always).
65
66
67
68
69
3. Independent, more than 2 groups:
Kruskal-Wallace
70
ANOVA
•A significance test can be done with more than 2
groups
•It tests null hypo: “all groups are equal”
71
•Kruskal-Wallace is nonparametric version of ANOVA
•ANalysis Of VAriance
72
Total deviation
of point around
grand mean
=
Total variance
=
Deviation of point
around group mean
Within group
variance
+
+
Deviation of group
mean around
grand mean
Between group
variance
73
•ANOVA computes the ratio:
•variance between groups
•variance within groups
•a big ratio happens when not all groups are the
same (ie the treatment has an effect)
74
Kruskal-Wallace
•Kruskal-Wallace is like indep groups ANOVA except
calculation uses ranks
75
•Basic idea: if random order is all that determined
scores, expect all groups to have about same
average rank
76
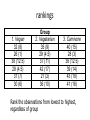
example
•Attitude towards the use of preservatives in food: 6
vegans, 6 vegetarians, and 6 meat eaters. The data
were collected using a 50-point rating scale. A higher
score represents a more positive attitude.
77
1. Vegan
32
26
38
29
31
30
Group
2. Vegetarian
35
29
37
42
27
36
3. Carnivore
40
28
38
39
43
41
78
rankings
1. Vegan
32 (8)
26 (1)
38 (12.5)
29 (4.5)
31 (7)
30 (6)
Group
2. Vegetarian
35 (9)
29 (4.5)
37 (11)
42 (17)
27 (2)
36 (10)
3. Carnivore
40 (15)
28 (3)
38 (12.5)
39 (14)
43 (18)
41 (16)
Rank the observations from lowest to highest,
regardless of group
79
Test statistic
Essentially calculates variability of group mean
ranks about grand mean
If it is big, reject null (groups equal)
80
•x <- c(32,26,38,29,31,30) # vegan
•y <- c(35,29,37,42,27,36) # vegetarian
•z <- c(40,28,38,39,43,41) # carnivore
•kruskal.test(list(x, y, z))
•
Kruskal-Wallis rank sum test
•data: list(x, y, z)
•Kruskal-Wallis chi-squared = 4.6792, df = 2,
p-value = 0.09636
81
4. Repeated measures, more than 2
groups: Friedman
82
Friedman test (cf repeated measures
ANOVA)
•Friedman is like repeated measures ANOVA except
calculation uses ranks
83
•Ranking is now for indiv subject across conditions.
This takes account of repeated measures
•For indep grps, ranking was across all subjects
84
example
•10 participants rated attractiveness
(10 pt scale) of Photoshopped images
of the same person. Picture 1 was
unaltered. Picture 2 simulated a facelift, Picture 3 a nose job, and Picture 4
a collagen implant. Did the
manipulations affect attractiveness?
85
Participant
1. Unaltered
Picture
2. Face-lift
3. Nose
4. Lips
1
8 (4)
6 (2.5)
6 (2.5)
4 (1)
2
5 (4)
4 (2.5)
3 (1)
4 (2.5)
3
4
5
6
7
7 (4)
5 (3)
9 (4)
7 (4)
6 (3)
5 (2)
7 (4)
6 (3)
6 (3)
8 (4)
6 (3)
3 (1)
5 (2)
5 (2)
5 (1.5)
3 (1)
4 (2)
3 (1)
4 (1)
5 (1.5)
8
9
10
6 (4)
8 (4)
7 (4)
5 (3)
7 (3)
5 (2)
3 (1)
4 (1)
4 (1)
4 (2)
5 (2)
6 (3)
Rank the observations for each subject across conditions
86
Test statistic
Essentially calculates variability of group mean
ranks about grand mean
If it is big, reject null (groups equal)
87
•x1<-c(8,5,7,5,9,7,6,6,8,7) # unaltered
•x2<-c(6,4,5,7,6,6,8,5,7,5) # face-lift
•x3<-c(6,3,6,3,5,5,5,3,4,4) # nose
•x4<-c(4,4,3,4,3,4,5,4,5,6) # lips
•m<-cbind(x1,x2,x3,x4)
•friedman.test(m)
•
Friedman rank sum test
•Friedman chi-squared = 20.4124, df = 3, p-value
= 0.0001394
88
•“The Photoshop manipulation of the face images
produced a significant effect on attractiveness
ratings (Friedman chi-squared = 20.41, df = 3, pvalue = 0.00014).”
89
Big issues
90
Sample size
•If using nonparametric approach, do when sample
size is small
•Why small?
•Nonparametric statistics are used when don’t want
to make assumptions about data distrib
91
•When the sample is large (rule of thumb: 25 or
more), don’t need to make assumptions anyway
•Due to central limit theorem
92
•Parametric versions of the tests use calculations
involving and inferences about sums of data
•Central limit theorem says that the distribution of a
sum approaches the normal as sample size increases
•http://onlinestatbook.com/stat_sim/sampling_dist/index.html
93
Robustness
•Parametric tests (t-test, ANOVA) can be quite
robust to violations of assumptions underlying them
•http://www.ruf.rice.edu/~lane/stat_sim/robustness/index.html
94
Summary
•
•
•
logic of hypo testing: null hypo, test statistic,
reject null, p-value
Type I , Type II errors
power, effect size, sample size
95
Nonparametric and parametric tests
•Permutation tests possible for every scenario
Nonparametric
parametric
•Mann-Whitney
indep groups t-test
•Wilcoxon
repeated measures t-test
•Kruskal-Wallace indep groups ANOVA
•Friedman
repeated measures
ANOVA
96