Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
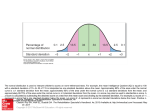
Chapter 3, part C III. Uses of means and standard deviations Of course we don’t just calculate measures of location and dispersion just because we can, they have very important uses. A. Z-scores • A z-score measures the relative location of an item in the data set. • It also measures the number of standard deviations an observation lies from the mean. xi x zi s For example, the airline price of $175 has a z-score=(175-219)/45.47 = -.97. This means that a price of $175 falls almost one standard deviation below the mean. B. Chebyshev’s Theorem Chebyshev’s: At least (1-1/k2) of the items in a data set must be within k standard deviations from the mean, where k is any value greater than 1. In other words, the theorem tells us the % of items that must be within a specified number of standard deviations from the mean. Implications If k=2, at least 75% of the data lie within s=2 of the mean. How? (1-1/4)=.75 or 75%. If k=3, this fraction rises to 89% of the data. If k=4, this fraction rises to 94% of the data. Example: A microeconomics exam has a mean of 72 with a standard deviation of 4. What % of the class falls between 64 and 80 on their exam? Calculate the z-scores for both 64 and 80 to find k and then use Chebyshev’s theorem to answer the question. C. The Empirical Rule If the data are distributed normally (bell-shaped), the empirical rule tells us that: • Approximately 68% of the data will be within s=1 of the mean. • 95% of the data will be within s=2 of the mean. • all of the data will be within s=3 of the mean. D. Detecting Outliers • The empirical rule says that almost all observations will fall within s=3 of the mean. • Thus, if an observation has a z-score of greater than 3 (in absolute value), it may be considered an outlier. • What to do about an outlier? If it’s a case of an erroneous value (i.e. a typo), try to correct it. If it’s valid data, arguments can be made (for and against) dropping it from the sample.