Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
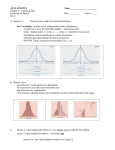
Chapter 1 Looking at Data – Distributions What is statistics? • The science of collecting, organizing, and interpreting numerical facts (data) with the goal of gaining understanding about a problem • Always relate calculations back to the problem at hand as numbers alone are not meaningful • Requires thinking and judgment about data Variables • A variable is a characteristic of an individual, or object of interest (ie. Person, plant, animal) – Variables can take on different values for different individuals – Ex. Individual Variable Person Flower Bird Age or Height Color Wingspan Distributions • The distribution of a variable tells us what values the variable takes on (for the group of individuals under consideration) and how often it takes them • Ex. Consider 10 rose bushes in a garden – What colors are represented? – How many of each color? Variables Categorial - Value falls into one of two or more groups, or categories. Ex. Blood type, hair color Quantitative -takes on numerical values -Mathematical operations (such as averaging) make sense Ex. Height, age, number of credit cards owned It makes sense to talk about the average height of the students in the class, but not the average blood type. 1.1 Displaying Distributions with Graphs • For a categorical variable, the distribution lists the categories and the count or percent of individuals who fall into each one. • How can we visually display this data? – Bar graphs • each category is represented by a bar – Pie charts • The slices must represent parts of one whole Example: Top 10 causes of death in the United States 2001 Rank Causes of death Counts % of top 10s % of total deaths 1 Heart disease 700,142 37% 29% 2 Cancer 553,768 29% 23% 3 Cerebrovascular 163,538 9% 7% 4 Chronic respiratory 123,013 6% 5% 5 Accidents 101,537 5% 4% 6 Diabetes mellitus 71,372 4% 3% 7 Flu and pneumonia 62,034 3% 3% 8 Alzheimer’s disease 53,852 3% 2% 9 Kidney disorders 39,480 2% 2% 32,238 2% 1% 10 Septicemia All other causes 629,967 26% For each individual who died in the United States in 2001, we record what was the cause of death. The table above is a summary of that information. Bar graphs Top 10 causes of deaths in the United States 2001 The number of individuals who died of an accident in 2001 is approximately 100,000. Ca nc Ce er re s br ov Ch as cu ro ni la c r re sp ira to ry Ac ci Di de ab nt s et es m el Fl litu u & s pn eu Al zh m on ei m ia er 's di se Ki as dn e ey di so rd er s Se pt ice m ia ise as es 800 700 600 500 400 300 200 100 0 He ar td Counts (x1000) Each category is represented by one bar. The bar’s height shows the count (or sometimes the percentage) for that particular category. zh ei m er 's di de nt s se as e Ac ci 800 700 600 500 400 300 200 100 0 Ca nc Ce er s re br ov Ch as cu ro la ni r c re sp ira Di to ab ry et es m el Fl litu u s & pn eu m on He ia ar td ise as Ki dn es ey di so rd er s Se pt ice m ia Al Counts (x1000) ise as es Ca nc Ce er re s br ov Ch as cu ro ni la c r re sp ira to ry Ac ci Di de ab nt s et es m el Fl litu u & s pn eu Al zh m on ei m ia er 's di se Ki as dn e ey di so rd er s Se pt ice m ia He ar td Counts (x1000) 800 700 600 500 400 300 200 100 0 Top 10 causes of deaths in the United States 2001 Bar graph sorted by rank Easy to analyze Sorted alphabetically Much less useful Pie charts Each slice represents a piece of one whole. The size of a slice depends on what percent of the whole this category represents. Percent of people dying from top 10 causes of death in the United States in 2000 Make sure your labels match the data. Make sure all percents add up to 100. Percent of deaths from top 10 causes Percent of deaths from all causes How to Chart Quantitative Variables? • Histograms – Numerical analog of bar graph – The range of values a variable can take on is divided into equal size intervals (bins) – Histogram shows number of data points (observations) that fall into each interval (bin) – Choosing the correct bin size is judgment call Histogram Student Score 1 75 2 99 3 79 4 71 5 66 6 82 7 89 8 0 9 53 10 73 number of students • Ex. Test 1 scores for 10 statistics students 10 bins test score number of students What if we change the bin size? 4 bins test score Interpreting Histograms • Look for overall pattern of data, and for any striking departures from the pattern • Look for outliers, individual values which fall outside the overall pattern of a distributions – Always watch out for outliers, and try to identify and explain them – Ex. Was the statistics test really hard, or were there unusual circumstances for student 8? Did he not show up for class, or did he cheat on his exam? Should he be included in the distribution? Stem Plots • Separate each observation into a stem (all but the final digit) and a leaf (final digit) • Write the stems in a vertical column with the smallest value at the top and draw vertical line to right of column • Write each leaf in row to right of its stem, in increasing order • Note: Some stems may have no leaves Creating a Stem Plot: Test scores of 10 students Student Score 1 75 2 99 3 79 4 71 5 66 6 82 7 89 8 0 9 53 10 73 Score 0 53 66 71 73 75 79 82 89 99 Stemplot 0|0 1| 2| 3| 4| 5| 6|6 7|1359 8|29 9|9 More on Stem Plots • Back-to-back stem plots with a common stem may be useful for comparing two related distributions • Stem plots don’t work too well for large data sets – If each stem holds a large number of leaves, you can split each stem into two: • One for leaves 0-4 • One for leaves 5-9 • If observed values have too many digits, trim numbers before making stemplot – Ex. Trim 1234 to 123, then 12 is stem and 3 is leaf. Indicate leaf unit is 10. – See example 1.8 in text Describing Distributions • Can describe the overall pattern of a distribution by its shape, center, spread and outliers • Center – For now, consider the center the midpoint – Value with approximately half the observations above it and half the observations below it • Spread – For now, describe by indicating smallest and largest values • Shape – How many peaks does the distribution have? • If one, unimodal • If several, multimodal – Is the distribution symmetric? Or skewed? • Outliers – any points that fall far outside the other points – You can use Tukey’s Rule to determine outliers of data Most common distribution shapes Symmetric distribution • A distribution is symmetric if the right and left sides of the histogram are approximately mirror images of each other. • A distribution is skewed to the right if the right side of the histogram (side with larger values) extends much farther out than the left side. It is skewed to the left if the left side of the histogram extends much farther out than the right side. Skewed distribution Complex, multimodal distribution Not all distributions have a simple overall shape, especially when there are few observations. Time Plots • A time plot of a variable plots each observation against the time at which it was measured – Time always on horizontal axis! • Look for patterns over time – A trend is a rise or fall that persists over time, despite small irregularities – A pattern that repeats itself at regular intervals of time is called seasonal variation Ex. Retail price of fresh oranges over time Time is on the horizontal, x axis. The variable of interest—here “retail price of fresh oranges”— goes on the vertical, y axis. This time plot shows a regular pattern of yearly variations. These are seasonal variations in fresh orange pricing most likely due to similar seasonal variations in the production of fresh oranges. There is also an overall upward trend in pricing over time. It could simply be reflecting inflation trends or a more fundamental change in this industry. Describing Distributions with Numbers • Recall: Distributions of variables are described by shape, center, spread and outliers • We now extend beyond inspecting stemplots and histograms to more precise definitions of center and spread • Measures of center: the mean and the median The Mean (x-bar) • To find the mean of a set of n observations, x1, x2, x3, … , xn, add their values and divide by the number of observations: x1 x2 x3 ... xn x n 1 x xi or n S (Sigma) means sum Example: Test scores on 2nd exam for 10 statistics students Exam scores: 80, 73, 92, 85, 75, 98, 93, 55, 80, 90 n = 10 x1 x2 x3 ... xn x n 80 73 92 85 75 98 93 55 80 90 x 10 821 x 82.1 10 • Note: The mean is sensitive to a few extreme observations – NOT a resistant measure of center – What if there were an 1lth student in the class who didn’t show up and received a 0 on the 2nd exam? • How would this affect the mean? 821 0 821 x 74.6 10 1 11 The Median (M) • The median is the midpoint of a distribution – • Half the observations are smaller and half the observations are larger than M To find the median: 1. Arrange data from smallest to largest 2. If the number of observations (n) is odd, M is the center observation in the ordered list, located (n+1)/2 observations up from the bottom 3. If the number of observations (n) is even, M is the mean of the two center observations in the ordered list. M is still located at the (n+1)/2 position Finding the Median • Consider again exam scores for 10 students: Exam scores: 80, 73, 92, 85, 75, 98, 93, 55, 80, 90 • Arrange data from smallest to largest: 55, 73, 75, 80, 80, 85, 90, 92, 93, 98 • n = 10, so n is even and M is the mean of the 5th and 6th observations in the ordered list. • M is located at (10+1)/2, or 5.5th position in ordered list • M = (80+85)/2 = 82.5 • What happens to M if we include the 11th student who received a 0 in the data set? Exam scores (in order): 0, 55, 73, 75, 80, 80, 85, 90, 92, 93, 98 • There are now 11 data points, so n = 11 and is odd • M is therefore center observation in ordered list, located in position (12+1)/2, or 6th position • M = 80 The median is a more resistant measure of center than the mean. Comparing the mean and the median The mean and the median are the same only if the distribution is symmetrical. The median is a measure of center that is resistant to skew and outliers. The mean is not. Mean and median for a symmetric distribution Mean Median Left skew Mean and median for skewed distributions Mean Median Mean Median Right skew Impact of skewed data Symmetric distribution… Disease X: x 3.4 M 3.4 Mean and median are the same. … and a right-skewed distribution Multiple myeloma: x 3.4 M 2.5 The mean is pulled toward the skew. Measure of spread: the quartiles The first quartile, Q1, is the value in the sample that has 25% of the data at or below it ( it is the median of the lower half of the sorted data, excluding M). M = median = 3.4 The third quartile, Q3, is the value in the sample that has 75% of the data at or below it ( it is the median of the upper half of the sorted data, excluding M). 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 1 2 3 4 5 6 7 1 2 3 4 5 1 2 3 4 5 6 7 1 2 3 4 5 0.6 1.2 1.6 1.9 1.5 2.1 2.3 2.3 2.5 2.8 2.9 3.3 3.4 3.6 3.7 3.8 3.9 4.1 4.2 4.5 4.7 4.9 5.3 5.6 6.1 Q1= first quartile = 2.2 Q3= third quartile = 4.35 Five-number summary and boxplot 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 6.1 5.6 5.3 4.9 4.7 4.5 4.2 4.1 3.9 3.8 3.7 3.6 3.4 3.3 2.9 2.8 2.5 2.3 2.3 2.1 1.5 1.9 1.6 1.2 0.6 Largest = max = 6.1 BOXPLOT 7 Q3= third quartile = 4.35 M = median = 3.4 6 Years until death 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 5 4 3 2 1 Q1= first quartile = 2.2 Smallest = min = 0.6 0 Disease X Five-number summary: min Q1 M Q3 max Boxplots for skewed data Years until death Comparing box plots for a normal and a right-skewed distribution 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 Boxplots remain true to the data and depict clearly symmetry or skew. Disease X Multiple Myeloma Suspected Outliers • Outliers are troublesome data points, and it is important to be able to identify them. • One way to raise the flag for a suspected outlier is to compare the distance from the suspicious data point to the nearest quartile (Q1 or Q3). We then compare this distance to the interquartile range (distance between Q1 and Q3). • We call an observation a suspected outlier if it falls more than 1.5 times the size of the interquartile range (IQR) above the first quartile or below the third quartile. This is called the “1.5 * IQR rule for outliers.” 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 7.9 6.1 5.3 4.9 4.7 4.5 4.2 4.1 3.9 3.8 3.7 3.6 3.4 3.3 2.9 2.8 2.5 2.3 2.3 2.1 1.5 1.9 1.6 1.2 0.6 8 7 Q3 = 4.35 Distance to Q3 7.9 − 4.35 = 3.55 6 Years until death 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 5 Interquartile range Q3 – Q 1 4.35 − 2.2 = 2.15 4 3 2 1 Q1 = 2.2 0 Disease X Individual #25 has a value of 7.9 years, which is 3.55 years above the third quartile. This is more than 3.225 years, 1.5 * IQR. Thus, individual #25 is a suspected outlier. Measure of Spread: Standard Deviation • The most common numerical description of a distribution is given by the mean to measure center and the standard deviation (s) to measure spread – Looks at how far observations are from their mean • The variance of a set of observations (s2) is the average of the squares of the deviations of the observations from their mean: • The standard deviation (s) is then given by the square root of the variance: 1 n 2 s ( x x ) i n 1 1 • The deviations xi – x are large in magnitude if observations lie far from the mean • Some deviations will be positive and some will be negative depending on if the observations are smaller or larger than the mean • The sum of the deviations of the observations from the mean will always be zero • s and s2 will be large for widely spread distributions and small if observations do not lie far from the mean Steps for finding variance and standard deviation: 1. Find the mean 2. subtract each value from the mean 3. Square each of the results 4. Add them together 5. Divide by n-1 (where n is the number of observations) *** This value is the variance 6. take the square root to get the standard deviation • Why divide by n-1? – Since the sum of the deviations are zero, the last observation/deviation can be calculated once the other n-1 are known – Thus we say there are only n-1 degrees of freedom • Why emphasize s over s2? – s has the same unit of measurement as the original observations – Natural measure of spread for Normal distribution (section 1.3) Calculations … s 1 df n ( xi x ) 2 1 Mean = 63.4 Sum of squared deviations from mean = 85.2 Degrees freedom (df) = (n − 1) = 13 s2 = variance = 85.2/13 = 6.55 inches squared s = standard deviation = √6.55 = 2.56 inches Women’s height (inches) i xi x (xi-x) (xi-x)2 1 59 63.4 -4.4 19.0 2 60 63.4 -3.4 11.3 3 61 63.4 -2.4 5.6 4 62 63.4 -1.4 1.8 5 62 63.4 -1.4 1.8 6 63 63.4 -0.4 0.1 7 63 63.4 -0.4 0.1 8 63 63.4 -0.4 0.1 9 64 63.4 0.6 0.4 10 64 63.4 0.6 0.4 11 65 63.4 1.6 2.7 12 66 63.4 2.6 7.0 13 67 63.4 3.6 13.3 14 68 63.4 4.6 21.6 Sum 0.0 Sum 85.2 Mean 63.4 Mean = 63.4 inches x s = 2.56 inches Mean ± 1 s.d. Standard Deviation in the calculator: Input the values in L1 (under STAT enter) STAT-CALC-enter-enter The Sx value is the sample standard deviation Another Standard Deviation Example Find the SD for 3, 5, 6, 6, 7, 9, 10, 10, 14 Step 1: Find the mean: (3 + 5 + 6 + 6 + 7 + 9 + 10 + 10 +14) / 9 = 7.8 Step 2: Subtract each value from the mean: (3-7.8) = -4.8 (5-7.8) = -2.8 (6-7.8) = -1.8 (6-7.8) = -1.8 (7-7.8) = -.8 (9-7.8) = 1.2 (10-7.8) = 2.2 (10-7.8) = 2.2 (14-7.8) = 6.2 Step 3: Square each value (be sure to use parenthesis!) (-4.8)²= 23.04 (-2.8)²= 7.84 (-1.8)²= 3.24 (-1.8)²= 3.24 (-.8)²= .64 (1.2)²= 1.44 (2.2)²= 4.84 (2.2)²= 4.84 (6.2)²= 38.44 Step 4: Add them all together 23.04 + 7.84 + 3.24 + 3.24 + .64 + 1.44 + 4.84 + 4.84 + 38.44 = 87.56 Step 5: Divide by n-1 (n is the number of observations) 84.32 / 8 = 10.945 (this is the variance) Step 6: Take the square root sqrt(10.54) = 3.31 Properties of the Standard Deviation • s measures spread about the mean – Only use when mean is measure of center • s = 0 only when there is NO spread – Occurs when all observations have same value – Otherwise, s > 0 • Like the mean, s is not resistant – A few outliers can make s very large – Remember, the deviation is squared! Choosing among summary statistics • Because the mean is not resistant to Height of 30 Women outliers or skew, use it to describe 69 68 symmetrical and don’t have outliers. 67 Plot the mean and use the standard deviation for error bars. • Otherwise use the median in the five Height in Inches distributions that are fairly 66 65 64 63 62 61 60 number summary which can be 59 plotted as a boxplot. 58 Box Plot Boxplot Mean +/- SD Mean ± SD What should you use, when, and why? Arithmetic mean or median? • Middletown is considering imposing an income tax on citizens. City hall wants a numerical summary of its citizens’ income to estimate the total tax base. – Mean: Although income is likely to be right-skewed, the city government wants to know about the total tax base. • In a study of standard of living of typical families in Middletown, a sociologist makes a numerical summary of family income in that city. – Median: The sociologist is interested in a “typical” family and wants to lessen the impact of extreme incomes. Changing the unit of measurement Variables can be recorded in different units of measurement. Most often, one measurement unit is a linear transformation of another measurement unit: xnew = a + bx. Temperatures can be expressed in degrees Fahrenheit or degrees Celsius. TemperatureFahrenheit = 32 + (9/5)* TemperatureCelsius a + bx. Linear transformations do not change the basic shape of a distribution (skew, symmetry, multimodal). But they do change the measures of center and spread: – Multiplying each observation by a positive number b multiplies both measures of center (mean, median) and spread (IQR, s) by b. – Adding the same number a (positive or negative) to each observation adds a to measures of center and to quartiles but it does not change measures of spread (IQR, s). Density Curves and Normal Distributions • A density curve is a mathematical idealization of a distribution of data, picturing the overall pattern of the data and ignoring minor irregularities as well as any outliers • A smooth approximation to the irregular bars of a histogram • A density curve is always on or above the horizontal axis, and has area exactly 1 beneath it • Recall, in a histogram, the areas of bars represent either counts or proportions of observations (differ in scale on y-axis) • If proportion, then total area of all bars is 1, and area of shaded bars gives proportion of test scores 6.0 or lower • Similarly, the total area under a density curve is 1, and the area under the density curve for a range of values is the proportion of all observations for that range. Histogram of a sample with the smoothed, density curve describing theoretically the population. Density curves come in any imaginable shape. Some are well known mathematically and others aren’t. Median and mean of a density curve The median of a density curve is the equal-areas point: the point that divides the area under the curve in half. The mean of a density curve is the balance point, at which the curve would balance if it were made of solid material. The median and mean are the same for a symmetric density curve. The mean of a skewed curve is pulled in the direction of the long tail. Notation • We use x and s to denote the mean and standard deviation, respectively, as computed from a set of actual observations • To distinguish an idealized distribution from a sampled distribution, we denote the mean of a density curve by m (the Greek letter mu) and the standard deviation of a density curve by s (the Greek letter sigma) Normal Distributions • Mean at center of symmetric distribution • Standard deviation natural measure of spread – Points of inflection of density curve are located distance s on either side of m (ms, ms) • Density curve notation: N(m,s) Larger s, more spread out Smaller s, less spread out Why is the Normal distribution so important? • Good description of data sets such as test scores, characteristics of biological populations, and repeated measurements of the same quantity • Good approximation to results of chance outcomes such as tossing a coin many times • Basis for many statistical inference procedures A family of density curves Here, means are the same (m = 15) while standard deviations are different (s = 2, 4, and 6). 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Here, means are different (m = 10, 15, and 20) while standard deviations are the same (s = 3) 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 The 68-95-99.7% Rule for Normal Distributions • About 68% of all observations are within 1 standard deviation Inflection point (s) of the mean (m) (for ALL Normal distributions!). • About 95% of all observations are within 2 s of the mean m. • Almost all (99.7%) observations are within 3 s of the mean. mean µ = 64.5 standard deviation s = 2.5 N(µ, s) = N(64.5, 2.5) Reminder: µ (mu) is the mean of the idealized curve, while x¯ is the mean of a sample. s (sigma) is the standard deviation of the idealized curve, while s is the s.d. of a sample. The standard Normal distribution Because all Normal distributions share the same properties, we can standardize our data to transform any Normal curve N(m,s) into the standard Normal curve N(0,1). X N(64.5, 2.5) Z N(0,1) => x z Standardized height (no units) If a variable X has any Normal distribution N(m,s) then the standardized variable Z = (X – m)/s has the standard normal distribution N(0,1). For each x we calculate a new value, z (called a z-score). Standardizing: calculating z-scores A z-score measures the number of standard deviations that a data value x is from the mean m. z (x m ) s When x is 1 standard deviation larger than the mean, then z = 1. m s m s for x m s , z 1 s s When x is 2 standard deviations smaller than the mean, then z = -2. for x m 2s , z m 2s m 2s 2 s s When x is larger than the mean, z is positive. When x is smaller than the mean, z is negative. Ex. Women heights Women’s heights follow the N(64.5”,2.5”) distribution. What percent of women are shorter than 67 inches tall (that’s 5’7”)? mean µ = 64.5" standard deviation s = 2.5" x (height) = 67" N(µ, s) = N(64.5, 2.5) Area= ??? Area = ??? m = 64.5” x = 67” z=0 z=1 We calculate z, the standardized value of x: z (x m) s (67 64.5) 2.5 , z 1 1 stand. dev. from mean 2.5 2.5 Because of the 68-95-99.7 rule, we can conclude that the percent of women shorter than 67” should be, approximately, 0.68 + half of (1 - 0.68) = 0.84 or 84%. Using the standard Normal table Table A gives the area under the standard Normal curve to the left of any z value. .0082 is the area under N(0,1) left of z = 2.40 .0080 is the area under N(0,1) left of z = -2.41 (…) 0.0069 is the area under N(0,1) left of z = -2.46 Percent of women shorter than 67” For z = 1.00, the area under the standard Normal curve to the left of z is 0.8413. N(µ, s) = N(64.5”, 2.5”) Area ≈ 0.84 Conclusion: Area ≈ 0.16 84.13% of women are shorter than 67”. By subtraction, 1 - 0.8413, or 15.87% of women are taller than 67". m = 64.5” x = 67” z=1 What percent of women are shorter than 65”? Height distributed according to: N(µ, s) = N(64.5”, 2.5”) Tips on using Table A Because the Normal distribution is symmetrical, there are 2 ways that Area = 0.9901 you can calculate the area under the standard Normal curve to the Area = 0.0099 right of a z value. z = -2.33 area right of z = area left of -z area right of z = 1 - area left of z More Tips on using Table A To calculate the area between 2 z-values, first get the area under N(0,1) to the left for each z-value from Table A. Then subtract the smaller area from the larger area. A common mistake made by students is to subtract both z values. The area between z1 and z2 is NOT the same as the area to the left of z2 – z1 = 0.8 area between z1 and z2 = area left of z1 – area left of z2 Note: The area under N(0,1) for a single value of z is zero. Finding the percentage on the TI-84 Women’s heights follow the N(64.5”,2.5”) distribution. What percent of women are shorter than 67 inches tall (that’s 5’7”)? In the calculator: 2nd VARS normalcdf(lower bound, upper bound, mean, standard deviation) OR: 2nd VARS – DRAW ShadeNorm(lower bound, upper bound, mean, standard deviation) If the image doesn’t appear, alter your WINDOW After viewing the graph, you must do 2nd PRGM ClrDraw Example 1.27. The National Collegiate Athletic Association (NCAA) requires Division I athletes to score at least 820 on the combined math and verbal SAT exam to compete in their first college year. The SAT scores of 2003 were approximately normal with mean 1026 and standard deviation 209. What proportion of all students would be NCAA qualifiers (SAT ≥ 820)? x 820 m 1026 s 209 (x m) z s (820 1026) 209 206 z 0.99 209 Table A : area under z N(0,1) to the left of z -.99 is 0.1611 or approx. 16%. area right of 820 = = ≈ 84% In the calculator: total area 1 - area left of 820 0.1611 Ex. 1.28. The NCAA defines a “partial qualifier” eligible to practice and receive an athletic scholarship, but not to compete, with a combined SAT score of at least 720. What proportion of all students who take the SAT would be partial qualifiers? That is, what proportion have scores between 720 and 820? x 720 m 1026 s 209 (x m) z s (720 1026) z 209 306 z 1.46 209 Table A : area under N(0,1) to the left of z - 1.46 is 0.0721 or approx. 7%. area between 720 and 820 ≈ 9% = = area left of 820 0.1611 - area left of 720 0.0721 About 9% of all students who take the SAT have scores between 720 and 820. Inverse normal calculations We may also want to find the observed range of values that correspond to a given proportion/ area under the curve. For that, we use Table A backward: • we first find the desired area/ proportion in the body of the table, • we then read the corresponding z-value from the left column and top row. For a left area of 1.25 % (0.0125), the z-value is -2.24 Inverse Normal Calculations Scores on the SAT verbal test in recent years follow the N(505,110) distribution. How high must a student score to place in the top 5% of all students taking the SAT? 1. To be in the top 5%, must find z value for standard normal distribution with 95% of area to the left of z – Use Table A z value closest to 0.95 is between 1.64 and 1.65. Use z = 1.645 2. Unstandardize. Transform from z back to original x scale. 3. Interpret: This is the x that lies 1.645 standard deviations above the mean on the N(505,110) curve. Scores above 685.95 are in the upper 5% of scores. z (x m) s x sz m x (110)(1.645) 505 x 685.95 Inverse Normal Calculations in the calculator Scores on the SAT verbal test in recent years follow the N(505,110) distribution. How high must a student score to place in the top 5% of all students taking the SAT? 2nd VARS 3: invNorm (percent to the left, mean, standard deviation) Since we are looking for the top 5%, the percent to the left is 95%. Normal probability plots One way to assess if a distribution is indeed approximately normal is to plot the data on a normal probability plot. The data points are ranked and the percentile ranks are converted to z-scores. The z-scores are then used for the x axis against which the data are plotted on the y axis of the normal probability plot. If the distribution is indeed normal the plot will show a straight line, indicating a good match between the data and a normal distribution. Systematic deviations from a straight line indicate a non-normal distribution. Outliers appear as points that are far away from the overall pattern of the plot. Good fit to a straight line: the distribution of rainwater pH values is close to normal. Curved pattern: the data are not normally distributed. Instead, it shows a right skew: a few individuals have particularly long survival times. Normal probability plots are complex to do by hand, but you can create them on your calculator using 2nd Y=. Choose the last option for Type.