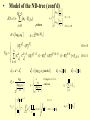Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Principles and Applications For
Supporting Similarity Queries
in Non-ordered Discrete and Continuous
Data Spaces
Gang Qian
Advisor: Dr. Sakti Pramanik
Department of Computer Science and Engineering
Michigan State University
Outline
1. Introduction
–
–
–
2.
3.
4.
5.
6.
Similarity queries and applications
Research problems
Overview of the dissertation (contributions)
Indexing NDDSs using the ND-tree
The NSP-tree: an SP Approach
Extending NDDSs into HDSs
Choosing A Distance Measure
Conclusion
Introduction
• Similarity Queries
– What: Return similar objects to a query object
• Different from traditional database queries
• E.g. find all similar genome sequences in the DB to the
query sequence
– Application: Many new application areas
• Genome Sequence Databases, Data Mining , Time Series
Databases , Artificial Intelligent, Content Based Image
Retrieval (CBIR), Audio Retrieval, etc.
– A measure of similarity needs to be defined
• Similarity Queries (cont’d)
– Two query types
• K nearest neighbor (k-NN) query
• Range query
• Models for Similarity Queries
– Vector model:
• Most popular and widely used
• Believed to be better than other models [Baeza 97]
– Other models:
• The Boolean model, the probabilistic model, etc.
• Our focus is on the vector model
• The Vector Model
– Represent/approximate each database object and
query object as a vector
• Could be non-trivial
– Similarity between objects can be calculated
• A vector is a point in a multidimensional data space
• The closer the two points, the more similar are their
representing objects
– Similarity query becomes:
• Searching a DB of vectors by calculating distance values
between the query vector and each vector in the DB
– The focus of this dissertation is on supporting
similarity queries using the vector model
• Major Research Issues
– Efficiency:
• Why:
– DB are usually very large.
– Linear search is not efficient
• Solution:
– Indexing techniques are needed
• Our main focus in this dissertation
– Effectiveness:
• Why:
– A number of different distance measures are available. E.g.,
Euclidean distance, Manhattan distance, etc.
• Open problem: how to choose a suitable distance measure
• We have made contributions for understanding the
relationship among distance measures for similarity queries
• Overview of the Dissertation
– Indexing Non-ordered Discrete Data Spaces (NDDS)
• The ND-tree and the NSP-tree are proposed
– The ND-tree is the first index structure of its kind
– A theoretical performance estimation model for the ND-tree is
developed
– The NSP-tree is particularly efficient for skewed datasets
– Indexing Hybrid Data Spaces (HDS)
• The NDh-tree is proposed
– Efficiently support similarity queries in HDSs
– Choosing a distance measure
• A theoretical model is developed
– Compare the behavior of the Euclidean distance and the cosine
angle distance measures for NN queries on random data
• Experimentally compared EUD and CAD for real, clustered
and normalized data
Outline
1. Introduction
2. Indexing NDDSs using the ND-tree
– Motivations for NDDSs
– The problem of current multidimensional index
structures
– Existing techniques to search non-ordered discrete data
– Challenges
3.
4.
5.
6.
– The ND-tree in detail
The NSP-tree: an SP Approach
Extending NDDSs into HDSs
Choosing A Distance Measure
Conclusion
• Non-ordered Discrete Data Spaces (NDDS)
– Domains that contain non-ordered discrete values are
prevalent, e.g., sex, profession, etc.
– There are many new and emerging applications that
use vectors with non-ordered values
• e.g. genomic sequences that are broken into fixed length
substrings (vectors) with the domain: {a, g, t, c}:
“aggcggtgatctgggccaatactga ” is a substring obtained
from a genome sequence. It is also a vector, e.g., the
value of the 3rd dimension of the vector is “g”
– NDDS: a d-dimensional data space that is the
Cartesian product of d non-ordered discrete domains
• NDDS (cont’d)
– Databases based on an NDDS is often quite large
• E.g., Genbank is 24GB and growing
– Multidimensional indexing methods are needed
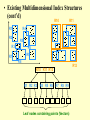
• Existing Multidimensional Index Structures
– Typical index structure: The R-tree
–
–
–
–
–
• Widely used. The basis for many later methods:
– R*-tree, SS-tree, SR-tree, X-tree, etc.
Group clusters of vectors/points into “boxes”, called Minimum
Bounding Rectangles (MBRs)
MBRs are further grouped recursively into larger MBRs
Nested MBRs are organized as a balanced tree structure
Disk-based: Each tree node resides in one disk page/block
Dynamic construction algorithms
• Similar to those of the B-tree
• Heuristics are different from those of the B-tree
• Details in R-tree [Guttman 84]
• Existing Multidimensional Index Structures
(cont’d)
R10
R11
R1
R2
R4
R5
R3
R6
R9
R7
R8
R12
R10 R11 R12
R1 R2 R3
R4 R5 R6
R7 R8 R9
Leaf nodes containing points (Vectors)
• Existing Multidimensional Indexing Methods
(cont’d)
– Must work in Continuous Data Spaces (CDS)
• Vectors are grouped using some geometrical shapes
– Inapplicable for indexing an NDDS
• Problems for Other Indexing Methods
– String indexing methods (Tries, Prefix B-tree, etc.)
• For prefix and substring search, not for similarity search
• Only deal with a single domain (alphabet)
– Metrics trees (GNAT, M-tree, etc.)
• Organizing data only by their relative distances
• Too general, not optimized for the NDDS
• Most are static
• Existing Search Techniques for Non-ordered
Discrete Data
– Bitmap index
– Genome sequence search
• Online searching algorithms – linear scan
• Indexing: Hashing or inverted file – exact match
– The signature tree (SG-tree)
• Similarity search on sets
• Indexing bitmaps
• Challenges to Index NDDS
–
–
–
–
No ordering of values on each dimension
Non-applicability of continuous distance measures
High probability of duplicate values
Limited choice of splitting points for overflow node
• The ND-tree is designed to properly address
the above challenges
–
–
–
–
Establish discrete “geometrical concepts”
Hamming distance is used.
Multiple heuristics are developed to break ties
Effective algorithms are developed to generate
candidate partitions for overlap nodes
• Discrete Geometrical Concepts for NDDSs
– A d-dimensional NDDS d : The Cartesian product
of d alphabets (domains): d = A1 A2 ... Ad.
Ai (1 i d): an alphabet consisting of a finite
number of non-ordered letters (values).
– Discrete rectangle: R = S1 S2 ... Sd
Si Ai (1 i d) is called the i-th component set of R
– Edge length on ith-dim: length(R, i) = |Si|
– area, overlap of discrete rectangles, …
• ND-Tree Structure
–
–
–
–
Similar to that of the R-tree
M and m: Max. and min. number of entries in a node
Leaf node entry: (object pointer, vector)
Non-leaf node entry: (child pointer, DMBR)
• Discrete minimum bounding rectangle (DMBR):
Recursively defined
{ag}{acgt} {tc}{acgt}
Level 1 (root):
Level 2:
{ag} {gc} {ag}{at}
Level 3 (leaf):
“at...”“ga...”
{t} {cgt} {c}{acg}
“tc...”“tt...”
•
Building the ND-tree
–
–
Keep the data well-organized in the tree (less overlap)
Insertion algorithm
1) Choose a leaf for the new vector
2) Overflow ? Split the node
–
Algorithm ChooseLeaf
•
•
–
Go top-down to a leaf node
Heuristics are used (least overlap inc., area inc., etc.)
Splitting an overflow node
•
•
Divide the M+1 entries into two disjoint sets (partition)
Algorithm SplitNode:
1) Find a set of candidate partitions
2) Choose the best partition
3) Split based on the best partition
•
Building the ND-tree (cont’d)
–
ChoosePartitionSet
•
•
Exhaustive method is infeasible
Need to decide a smaller candidate partition set
– potentially less overlap.
–
Permutation approach (for smaller alphabet)
•
•
•
•
Generate a sorted entry list for each dimension and each
permutation of the alphabet by a bucket ordering
technique
Generate partitions from the sorted entry list
Much less candidate partitions generated
Proposition: can find an overlap-free partition, if exists
•
Building the ND-tree (cont’d)
– Merge-and-sort approach (for larger alphabet)
•
•
•
Generate one sorted entry list for each dimension by a merge-and-sort
technique, then generate partitions from the list
Even less candidates are considered
Merge-and-sort technique:
–
–
•
–
Can also find an overlap-free partition, if exists
Choose the best partition
•
•
Choose the best partition from the candidate set
A set of heuristics are used
–
–
–
•
Merge entries into an auxiliary tree, sort entries using the aux. Tree
3 data fields for each node T:
i. T.sets: The set of component sets represented by the subtree
ii. T.freq: Total number of entries that are corresponding to one of the
component sets in T.sets
iii. T.letters: The set of letters that appear in any component set in T.sets
H1: Minimize overlap of the DMBRs of the two new nodes
H2: Favor splits on longer edge of the DMBR of the overflow node
……
Similarity Query Algorithm
• Example of the auxiliary tree:
– A = {a, b, c, d, e, f}, M = 10, m = 3; Right now: D = 5
– The 5th component set of the DMBRs of the 11 entries in the overflow node:
1 2
3 4
5
6
7 8
9 10 11
{c}, {ade}, {b}, {ae}, {f}, {e}, {cf}, {de}, {e}, {cf}, {a}
• Comparison with The Linear Scan
(Genomic Data d=25)
•
NDDS with Different Alphabet Sizes
–
Naive approach
•
•
•
–
Normalization approach
•
•
•
–
No change to current algorithms
Advantage: simplicity
Disadvantage: unfair comparison among dimensions
The edge length of a discrete rectangle is normalized
– norm_length(R, i) = length(R, i) / |Ai| = |Si| / |Ai|
Other concepts, e.g. area, are normalized based on the
normalized edge length
The construction algorithms use normalized geometrical
measures for their heuristics
The normalization approach is usually much better
than the naive approach
•
Even better when the difference among dims is large
•
Performance Estimation Model of the ND-tree
–
Motivation
•
–
Inputs
•
–
Estimated disk IO’s for the given Hamming distance
Assumptions
•
•
–
Dimensions, alphabet size, database size, node size,
Hamming distance
Output
•
–
Analyze the performance of the ND-tree for very large
databases with a large range of input parameters
Vectors are uniformly distributed
No correlation among dimensions
Main idea
•
•
Estimate the area of DMBRs on each level of the ND-tree
The area of a DMBR gives the probability that the
corresponding node will be accessed
•
Model of the ND-tree (cont’d)
IO 1
|V |
log 2 M
l
ni 2
log 2 ni 1
M n
2
H 1
(ni Pi, h )
i 0
H log b n0
,where
if i 0
if 1 i H
b 2log 2 M n
( Bi ) d i ( Bi) d i
if h 0
h
Pi, h
k C h k ( B ) d i k (1 B ) k ( B ) d i k h (1 B ) h k ] P
[
C
i
i
i
i
i, h 1 if h 1
d i d i
k 0
d i d d i
si
sH
log 2 ni
d
2
1
Ti, j j
C A
d i (log 2 ni ) mod d
si
sH
si log n
2 i
2 d
( A ) wi 1
wi
j 1
A
wi
j (C kj
) Ti, k )
Ck
k 1
A
Bi si A
if (log 2 ni ) / d 1
otherwise
Bi si A
A
si
j Ti, j
j 1
if j 1
A
wi
if 2 j A
wi V ni
•
Model of the ND-tree (cont’d)
–
Evaluation
Outline
1. Introduction
2. Indexing NDDSs using the ND-tree
3. The NSP-tree: an SP Approach
–
–
–
–
Motivations for an SP approach
Challenges
The NSP-tree
Experimental results
4. Extending NDDSs into HDSs
5. Choosing A Distance Measure
6. Conclusion
•
Motivations for A Space-Partitioning Approach
–
–
–
Overlap among bounding regions is a known problem
in index structures for CDS [Berchtold et al. 96]
Overlap in NDDSs also causes performance
degradation [Qian et. al. 03]
Although overlap reducing heuristics are applied, the
ND-tree may have overlap as a DP approach
•
–
When the database is very
skewed, overlap in the
ND-tree may cause noticeable
performance degradation
An SP approach can guarantee overlap-free
• Background
– Data partitioning (R-tree variants)
• Group vectors based on data distribution – the bounding
regions of the groups may overlap
• Guarantee a low bound on disk utilization
– Space partitioning (KD-tree variants)
• Partition the data space into subspaces. Vectors are
grouped based on the subspace they belong to
• Guarantee no overlap among subspaces
– Pros and cons of SP method
• Advantage: fan-out is large – only split info is stored
• Disadvantage: subspaces contains large dead spaces
– Use additional MBRs may reduce the fan-out
– CDS solution: grid-based approximation of MBR is used as
additional pruning tools
• Challenges for an SP approach in NDDSs and
the Solution of the NSP-tree
– NDDS cannot be split based on a single split point
• No ordering
• Solution: Enumerate the arrangement of each letter for a
split
– Difficult to determine an arrangement for absent
letters
• Randomly decide a side may not be good
• Solution: Only partition the current data space
– Current data space: the Cartesian product of the existing letters on
each dimension
– Let insertion algorithms handle new letters
• Challenges and Solutions of the NSP-tree (cont’d)
– Balance the fan-out and the use of DMBRs
• The use of DMBRs reduces the fan-out and vice versa
• Grid-based solution for CDSs is inapplicable for NDDSs
• Different approaches are tested
– Several nodes share one DMBR or one node have multiple DMBRs
– It is found empirically that two DMBRs per node usually leads to best
results
• Solution: Two DMBRs per node are used for the NSP-tree
– Need to enhance the space utilization
• SP approaches cannot guarantee a low bound on space
utilization
• Solution: Heuristics to balance number of entries in each tree
node are extensively applied in the NSP-tree
• Challenges and Solutions of the NSP-tree (cont’d)
|A| = 10, d = 40, key# = 100,000, rq=3
• The NSP-tree Structure
– Leaf nodes contain vectors indexed
– Each non-leaf node has an Split History Tree (SHT)
and two additional DMBRs for each child
Level 1 (root)
Level 2
Level 3 (leaf)
– SHT:
1 SHT1
2 SHT2
4
DMBR11
DMBR12
DMBR11 DMBR21
DMBR12 DMBR22
…
key1 key2
More
op1 op2 entries ...
3 SHT3
More
DMBRs ...
DMBR11
DMBR12
…
More
children ...
More leaves ...
• An auxiliary unbalanced binary tree
• Each SHT node records info of one space split that
occurred in the node
• Construction Algorithms of The NSP-tree
– ChooseLeaf:
• From root to leaf, choose the child represents the subspace to
which the new vector belongs.
• If no child found, choose the child with least entries
– Make the tree more balanced
– Split a node in the NSP-tree
• For each dim, sort vectors based on the histogram of the
alphabet
– More frequent letters are put at either end of the queue
– May yield more balanced splits: e.g. “6 1 1 6” vs. “1 6 6 1”
• Heuristics, such as largest stretch and balanced split, are applied
to choose a best split
• Construction Algorithms (cont’d)
– Adjust the DMBRs
• Issues arises as two DMBRs per node are used
– Randomly pick two DMBRs may not be the best choice
• The purpose of maintaining two DMBRs for a node is
different from node splitting
– Want two DMBRs with a combined area as small as possible,
but can be overlapped
• The quadratic algorithm of the R-tree could be adapted
– Quite expensive
• A linear algorithm is developed for the NSP-tree
– Much faster than the quadratic
– The resulting query performance is comparable to the quadratic
approach and much better than using one DMBR per node
• Comparison with the ND-tree
d = 40, |A| = 4, zipf2 and zipf3, respectively
Outline
1. Introduction
2. Indexing NDDSs using the ND-tree
3. The NSP-tree: an SP Approach
4. Extending NDDSs into HDSs
– HDS concepts
– The NDh-tree
– Experimental results
5. Choosing A Distance Measure
6. Conclusion
• Motivations
– Data with values of different properties are very
common
• A record in a relational table often consists of both continuous
and non-ordered discrete data
– Applications that conduct similarity queries on hybrid
data are also very common
• E.g. check known attack patterns in network intrusion
detection
– How to efficiently conduct similarity queries on hybrid
data is an open research area
• HDS Concepts
– A Hybrid Data Space (HDS) is
• Defined as the Cartesian product of both continuous and nonordered discrete domains
• Continuous dimensions are assumed to be normalized to [0, 1]
– A hybrid rectangle R is defined as the Cartesian product
of sets and ranges: R S1 S 2 S d
• Si can be either a set or a range depending on the dimension it
belongs to
• Sets are for non-ordered discrete dimensions, while ranges are
for continuous dimensions
– A hybrid vector can be deemed as a special case
• HDS Concepts (cont’d)
– The edge length of R:
| Si | / | Ai |
length( R, i)
maxi mini
Dimension i is non - ordered discrete
Dimension i is continuous
– Distance measure for HDSs
• No well-known distance measure
• Extended Hamming distance (EHD):
d
EHD ( , ) f ( ai , ai ), where
i 1
0
f (ai , ai)
1
if dimension i is non - ordered discrete and ai ai or
dimension i is continous and |ai ai| t
otherwise
– Area, overlap, HMBR, …
• The NDh-tree
– Support similarity queries in HDSs
– The tree structure and construction algorithms are
similar to those of the ND-tree
• Hybrid concepts such as HMBRs are used
• Heuristics are based on Hybrid concepts
• The algorithms are capable of handling continuous
dimensions
• E.g. To generate candidate partitions for an overflow node,
the split algorithm of the NDh-tree scans through all
dimensions of an HDS. For NDs, either permutation or
merge-and-sort approach is used. For CDs, the entries are
sorted based on both low and high bounds of their range
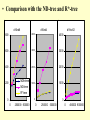
• Comparison with the ND-tree and R*-tree
d16nd8
d16nd4
d16nd12
800
4000
4000
600
3000
3000
400
2000
2000
1000
1000
0
0
NDh-tree
200
ND-tree
R*-tree
0
0
250000 500000
0
250000 500000
0
450000 900000
Outline
1.
2.
3.
4.
Introduction
Indexing NDDSs using the ND-tree
The NSP-tree: an SP Approach
Extending NDDSs into HDSs
5. Choosing A Distance Measure
–
–
–
–
Motivation and related work
Our approach
Results
Feature combination as an application
6. Conclusion
• Motivations
– A distance measure is an integral part of the vector
model
– There are a number of distance measures available
(e.g. Euclidean distance, Manhattan distance, …)
• Different distance measure yields different similarity
query results
– How to choose an appropriate distance measure is
an open research issue
• Related Work
– Performance comparison [Hampapur et al. 01]
• Based on recall and precision
• Used in image and video retrieval
– Complexity comparison [Hafner et al. 95]
• Consider computational overhead
• Prefer simplified distance measures
– Noise-distribution-based [Sebe et al. 00]
• Choose distance measure based on the noise distribution in
the data set
• Our Approach
– Establish a theoretical model to analyze the behavior
of two widely-used distance measures for NN
queries
• Euclidean distance (EUD) and cosine angle distance
(CAD)
• This model can be extended to analyze other distance
measures
– Experimentally analyze EUD and CAD for real,
normalized and clustered data
• The Theoretical Model
– Basic idea: find the expected rank of the first nearest
neighbor of EUD (NNe) by using CAD
• Similar if NNe is ranked high by CAD too
– Assume a unit hyper-cube data space and uniform
y
distribution
1
A
B
Q
Hyper-cone of NNe
NNe(Q)
O
x
1
• Theoretical and experimental results
– results based on the model
• DB = 50000 random data points
– Our empirical results show that the NN query results by
EUD and CAD are also quite similar for real, clustered
and normalized data in high-dimensional data spaces
• Discussion
– Observation: As dimension gets even higher, the EUD
and CAD get less similar eventually
– Explanation:
• Two factors: dimension and hyper-angle of the hyper-cone of
NNe
• Discussion (cont’d)
– Explanation (cont’d)
• As dimension gets higher, the hyper-angle of the hyper-cone
of the NNe keeps increasing
– Within a certain range of high dimensions, it is
reasonable to claim that the NN query results of EUD
and CAD are similar for random data
Conclusion
• To support similarity queries in NDDSs, the ND-tree and
the NSP-tree are proposed.
–
–
–
–
Very efficient for similarity queries in NDDSs compared to other
techniques. Their scalability is also very good.
The ND-tree is the first index structure of its kind.
A performance estimation model is developed for ND-tree.
The NSP-tree is an SP-approach, which is developed to further
explore the problem of overlap in NDDSs. It is shown to be
particularly efficient for skewed datasets.
• The NDh-tree is proposed to support similarity query in
HDSs. It is shown to be very efficient compared to
existing methods
• A theoretical model is proposed to analyze the behavior
of distance measures for similarity queries. Non-trivial
relationship between the EUD and CAD is revealed
using the model
Future Work
• Support more query types using the ND-tree and the
NDh-tree
–
–
Nearest neighbor queries
Queries that specify ranges on each attribute
• Study other distance measures for similarity queries in
HDSs
Thank you!