Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
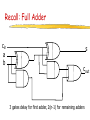
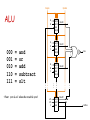
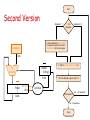
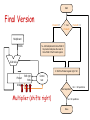
Arithmetic III CPSC 321 Andreas Klappenecker Any Questions? Today’s Menu Addition Multiplication Floating Point Numbers Recall: Full Adder cin a b s cout 3 gates delay for first adder, 2(n-1) for remaining adders Ripple Carry Adders • Each gates causes a delay • our example: 3 gates for carry generation • book has example with 2 gates • Carry might ripple through all n adders • O(n) gates causing delay • intolerable delay if n is large • Carry lookahead adders Faster Adders Why are cin a b cout cout=ab+cin(a xor b) they called 0 0 0 0 like that? =ab+acin+bcin 0 0 1 0 =ab+(a+b)cin 0 1 0 0 = g + p cin 0 1 1 1 Generate 1 0 0 0 1 0 1 1 g = ab 1 1 0 1 Propagate 1 1 1 1 p = a+b s 0 1 1 0 1 0 0 1 Fast Adders Iterate the idea, generate and propagate ci+1 = gi + pici = gi + pi(gi-1 + pi-1 ci-1) = gi + pigi-1+ pipi-1ci-1 = gi + pigi-1+ pipi-1gi-2 +…+ pipi-1 …p1g0 +pipi-1 …p1p0c0 Two level AND-OR circuit Carry is known early! A Simple ALU for MIPS • Need to support the set-on-less-than instruction (slt) • remember: slt is an arithmetic instruction • produces 1 if rs < rt and 0 otherwise • use subtraction: (a-b) < 0 implies a < b • Need to support test for equality (beq $t5, $t6, $t7) • use subtraction: (a-b) = 0 implies a = b Bnegate ALU 000 001 010 110 111 = = = = = and or add subtract slt •Note: zero is a 1 when the result is zero! Operation a0 b0 CarryIn ALU0 Less CarryOut Result0 a1 b1 0 CarryIn ALU1 Less CarryOut Result1 a2 b2 0 CarryIn ALU2 Less CarryOut Result2 a31 b31 0 CarryIn ALU31 Less Zero Result31 Set Overflow Multipliers Multiplication • More complicated than addition • accomplished via shifting and addition • Let's look at 3 versions based on the grade school algorithm 0010 (multiplicand) __ x_1011 (multiplier) 0010 x 1 00100 x 1 001000 x 0 0010000 x 1 00010110 • Shift and add if multiplier bit equals 1 Start Multiplication Multiplier0 = 1 0010 (multiplicand) __ x_1011 (multiplier) 0010 x 1 00100 x 1 001000 x 0 0010000 x 1 1. Test Multiplier0 Multiplier0 = 0 1a. Add multiplicand to product and place the result in Product register 0010110 2. Shift the Multiplicand register left 1 bit Multiplicand Shift left 64 bits 3. Shift the Multiplier register right 1 bit Multiplier Shift right 64-bit ALU 32 bits Product Write 64 bits Control test 32nd repetition? No: < 32 repetitions Yes: 32 repetitions Done Multiplication If each step took a clock cycle, this algorithm would use almost 100 clock cycles to multiply two 32-bit numbers. Requires 64-bit wide adder Multiplicand register 64-bit wide Variations on a Theme • Product register has to be 64-bit • • • • • Nothing we can do about that! Can we take advantage of that fact? Yes! Add multiplicand to 32 MSBs product = product >> 1 0010 (multiplicand) __ x_1011 (multiplier) Repeat last steps 0010 x 1 00100 x 1 001000 x 0 0010000 x 1 0010110 Start Second Version Multiplier0 = 1 1. Test Multiplier0 Multiplier0 = 0 1a. Add multiplicand to the left half of the product and place the result in the left half of the Product register Multiplicand 32 bits 2. Shift the Product register right 1 bit Multiplier Shift right 32-bit ALU 32 bits Product 64 bits Shift right Write 3. Shift the Multiplier register right 1 bit Control test 32nd repetition? No: < 32 repetitions Yes: 32 repetitions Done Version 1 versus Version 2 Multiplicand Multiplicand Shift left 64 bits 32 bits Multiplier Shift right 64-bit ALU Multiplier Shift right 32-bit ALU 32 bits 32 bits Product Product Write 64 bits Control test 64 bits Shift right Write Control test Critique • Registers needed for • multiplicand • multiplier • product • Use lower 32 bits of product register: • • • • place multiplier in lower 32 bits add multiplicand to higher 32 bits product = product >> 1 repeat Start Final Version Product0 = 1 1. Test Product0 Product0 = 0 Multiplicand 1a. Add multiplicand to the left half of the product and place the result in the left half of the Product register 32 bits 32-bit ALU 2. Shift the Product register right 1 bit Product Shift right Write Control test 64 bits 32nd repetition? Multiplier (shifts right) No: < 32 repetitions Yes: 32 repetitions Done Summary It was possible to improve upon the well-known grade school algorithm by • reducing the adder from 64 to 32 bits • keeping the multiplicand fixed • shifting the product register • omitting the multiplier register The Booth Multiplier Let’s kick it up a notch! Runs of 1’s • 011102 = 14 = 8+4+2 = 16 – 2 • Runs of 1s (current bit, bit to the right): • • • • 10 beginning of run 11 middle of a run 01 end of a run of 1s 00 middle of a run of 0s Run’s of 1’s • • • • • 0111 1111 11002 = 2044 How do you get this conversion quickly? 0111 11112 = 128 – 1 = 127 0111 1111 11112 = 2048 – 1 0111 1111 11002 = 2048 – 1 – 3 = 2048 – 4 Example 0010 0110 0000 0010 0010 0000 00001100 shift add add shift 0010 0110 0000 -0010 0000 0010 00001100 shift sub shift add Booth Multiplication Current and previous bit 00: middle of run of 0s, no action 01: end of a run of 1s, add multiplicand 10: beginning of a run of 1s, subtract mcnd 11: middle of string of 1s, no action Example: 0010 x 0110 Iteration Mcand Step Product 0 1 0010 0010 0010 Initial values 2 0010 0010 10: prod-=Mcand arith>> 1 0000 0000 0000 1110 1111 3 0010 0010 11: no op arith>> 1 1111 0001,1 1111 1000,1 4 0010 0010 01: prod+=Mcand arith>> 1 0001 1000,1 0000 1100,0 00: no op arith>> 1 0110,0 0110,0 0011,0 0011,0 0001,1 Negative numbers Booth’s multiplication works also with negative numbers: 2 x -3 = -6 00102 x 11012 = 1111 10102 Negative Numbers 0) 1) 1) 2) 2) 3) 3) 4) 4) 00102 x 11012 = Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod Mcnd 0010 Prod 1111 0000 1110 1111 0001 0000 1110 1111 1111 1111 10102 1101,0 1101,1 0110,1 0110,1 1011,0 1011,0 0101,1 0101,1 1010,1 sub >> add >> sub >> nop >> Summary • Extends the final version of the grade school algorithm • Simple change: add, subtract, or do nothing if last and previous bit respectively satisfy 0,1; 1,0 or 0,0; 1,1 • 0111 11002 = 128 – 4 = 1000 0002 – 0000 01002 Floating Point Numbers Floating Point Numbers We often use calculations based on real numbers, such as • e = 2.71828… • Pi = 3.14592… We represent approximations to such numbers by floating point numbers • 1.xxxxxxxxxx2 x 2yyyy Floating-Point Representation: float We need to distribute the 32 bits among sign, exponent, and significand • seeeeeeeexxxxxxxxxxxxxxxxxxxxxxx The general form of such a number is • (-1)s x F x 2E • s is the sign, F is derived from the significand field, and E is derived from the exponent field Floating Point Representation: double • 1 bit sign, 11 bits for exponent, 52 bits for significand • seeeeeeeeeeexxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Range of float: 2.0 x 10-38 … 2.0 x 1038 Range of double: 2.0 x 10-308 … 2.0 x 10308 IEEE 754 Floating-Point Standard • Makes leading bit of normalized binary number implicit 1 + significand • If significand is s1 s2 s3 s4 s5 s6 … then the value is (-1)s x (1 + s1/2 + s2/4 + s3/8 + … ) 2E • Design goal of IEEE 754: Integer comparisons should yield meaningful comparisons for floating point numbers IEEE 754 Standard • Negative exponents are a difficulty for sorting • Idea: most positive … most negative 1111 1111 … 0000 0000 • IEEE 754 uses a bias of 127 for single precision. • Exponent -1 is represented by -1 + 127 = 126 IEEE 754 Example Represent -0.75 in single precision format. -0.75 = -3/4 = -112 / 4 = -0.112 In scientific notation: -0.11 x 20 = -1.1 x 2-1 the latter form is normalized sc. notation Value: (-1)s x (1+ significand) x 2(Expnt – 127) Example (cont’d) • -1.1 x 2-1 = (-1)1 x (1 + .1000 0000 0000 0000 0000 000) x 2(126 – 127) The single precision representation is 1 0111 1110 1000 0000 0000 0000 0000 000 BAM! Conclusion • We learned how to multiply • Three variations on the grade school algorithm • Booth multiplication • Floating point representation a la IEEE 754 (Photo’s are courtesy of www.emerils.com, some graphs are due to Patterson and Hennessy)