Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Capelli's identity wikipedia , lookup
Euclidean vector wikipedia , lookup
Tensor operator wikipedia , lookup
Rotation matrix wikipedia , lookup
Quadratic form wikipedia , lookup
System of linear equations wikipedia , lookup
Bra–ket notation wikipedia , lookup
Basis (linear algebra) wikipedia , lookup
Symmetry in quantum mechanics wikipedia , lookup
Jordan normal form wikipedia , lookup
Eigenvalues and eigenvectors wikipedia , lookup
Linear algebra wikipedia , lookup
Cartesian tensor wikipedia , lookup
Matrix (mathematics) wikipedia , lookup
Determinant wikipedia , lookup
Non-negative matrix factorization wikipedia , lookup
Four-vector wikipedia , lookup
Perron–Frobenius theorem wikipedia , lookup
Singular-value decomposition wikipedia , lookup
Cayley–Hamilton theorem wikipedia , lookup
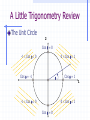
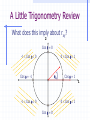
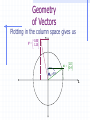
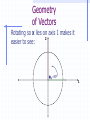
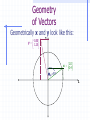
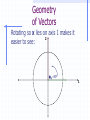
A Little Necessary Matrix Algebra for Doctoral Studies in Business Administration James J. Cochran Department of Computer Information Systems & Analysis Louisiana Tech University [email protected] Matrix Algebra Matrix algebra is a means of efficiently expressing large numbers of calculations to be made upon ordered sets of numbers Often referred to as Linear Algebra Why use it? Matrix algebra is used primarily to facilitate mathematical expression. Many equations would be completely intractable if scalar mathematics had to be used. It is also important to note that the scalar algebra is under there somewhere. Definitions - Scalars scalar - a single value (i.e., a number) Definitions - Vectors Vector - a single row or column of numbers Each individual entry is called an element denoted with bold small letters row vector a 1 2 3 4 column vector 1 2 a 3 4 Definitions - Matrices A matrix is a rectangular array of numbers (called elements) arranged in orderly rows and columns a A 11 a21 a12 a22 a13 a32 Subscripts denote row (i=1,…,n) and column (j=1,…,m) location of an element Definitions - Matrices Matrices are denoted with bold Capital letters All matrices (and vectors) have an order or dimensions - that is the number of rows x the number of columns. Thus A is referred to as a two by three matrix. Often a matrix A of dimension n x m is denoted Anxm Often a vector a of dimension n (or m) is denoted An (or Am) Definitions - Matrices Null matrix – a matrix for which all elements are zero, i.e., aij = 0 i,j Square Matrix – a matrix for which the number of rows equals the number of columns (n = m) Symmetric Matrix – a matrix for which aij = aji i,j Definitions - Matrices Diagonal Elements – Elements of a Square Matrix for which the row and column locations are equal, i.e., aij i = j Upper Triangular Matrix – a matrix for which all elements below the diagonal are zero, i.e., aij = 0 i,j i < j Lower Triangular Matrix – a matrix for which all elements above the diagonal are zero, i.e., aij = 0 i,j i > j Matrix Equality Thus two matrices are equal iff (if and only if) all of their elements are identical Note that statistical data sets are matrices (usually with observations in the rows and variables in the columns) Variable 1 Variable 2 Observation 1 a11 a12 Observation 2 a21 a22 Observation n an1 an2 Variable m a1m a2m anm Basic Matrix Operations Transpositions Sums and Differences Products Inversions The Transpose of a Matrix The transpose A’ of a matrix A is the matrix such that the ith row of A is the jth column of A’, i.e., B is the transpose of A iff bij = aji i,j This is equivalent to fixing the upper left and lower right corners then rotating the matrix 180 degrees Transpose of a Matrix An Example If we have then i.e., 1 4 A 2 5 3 6 A ' 1 2 3 4 5 6 1 4 A 2 5 A ' 1 2 3 4 5 6 3 6 More on the Transpose of a Matrix (A’)’ = A (think about it!) If A = A', then A is symmetric Sums and Differences of Matrices Two matrices may be added (subtracted) iff they are the same order Simply add (subtract) elements from corresponding locations where a11 a21 a31 a12 b11 b12 c11 a22 + b21 b22 = c 21 a32 b31 b32 c 31 a11 + b11 = c11 , a12 + b12 = c12 , a21 + b21 = c 21 , a22 + b22 = c 22 , a31 + b31 = c 31 , a32 + b32 = c 32 c12 c 22 c 32 Sums and Differences An Example If we have 1 2 A 3 4 5 6 and 7 10 B = 8 11 9 12 then we can calculate C = A + B by 1 2 7 10 8 12 C A + B = 3 4 + 8 11 = 11 15 5 6 9 12 14 18 Sums and Differences An Example Similarly, if we have 1 2 A 3 4 5 6 and 7 10 B = 8 11 9 12 then we can calculate C = A - B by 1 2 7 10 -6 -8 C A - B = 3 4 - 8 11 = -5 -7 5 6 9 12 -4 -6 Some Properties of Matrix Addition/Subtraction Note that The transpose of a sum = sum of transposes (A+B+C)’ = A’+B’+C’ A+B = B+A (i.e., matrix addition is commutative) Matrix addition can be extended beyond two matrices matrix addition is associative, i.e., A+(B+C) = (A+B)+C Products of Scalars and Matrices To multiply a scalar times a matrix, simply multiply each element of the matrix by the scalar quantity a11 b a21 a12 ba11 ba12 = a22 ba21 ba22 Products of Scalars & Matrices An Example If we have 1 2 A 3 4 5 6 and b = 3.5 then we can calculate bA by 1 2 3.5 7.0 bA 3.5 3 4 = 10.5 14.0 5 6 17.5 21.0 Note that bA = Ab if b is a scalar Some Properties of Scalar x Matrix Multiplication Note that if b is a scalar then bA = Ab (i.e., scalar x matrix multiplication is commutative) Scalar x Matrix multiplication can be extended beyond two scalars Scalar x Matrix multiplication is associative, i.e., ab(C) = a(bC) Scalar x Matrix multiplication leads to removal of a common factor, i.e., if ba11 ba12 a11 C ba21 ba22 then C bA where A = a21 ba31 ba32 a31 a12 a22 a32 Products of Matrices We write the multiplication of two matrices A and B as AB This is referred to either as pre-multiplying B by A or post-multiplying A by B So for matrix multiplication AB, A is referred to as the premultiplier and B is referred to as the postmultiplier Products of Matrices In order to multiply matrices, they must be conformable (the number of columns in the premultiplier must equal the number of rows in postmultiplier) Note that an (m x n) x (n x p) = (m x p) an (m x n) x (p x n) = cannot be done a (1 x n) x (n x 1) = a scalar (1 x 1) Products of Matrices If we have A(3x2) and B(2x3) then a11 a12 a 13 b11 b12 c11 c12 AB a21 a22 a23 x b21 b22 = c 21 c 22 C a31 a32 a33 b31 b32 c 31 c 32 where c11 = a11b11 + a12b21 + a13b31 c12 = a11b12 + a12b22 + a13b32 c 21 = a21b11 + a22b21 + a23b31 c 22 = a21b12 + a22b22 + a23b32 c 31 = a31b11 + a32b21 + a33b31 c 32 = a31b12 + a32b22 + a33b32 Products of Matrices If we have A(3x2) and B(2x3) then b11 b12 a11 a12 a 13 BA b21 b22 x a21 a22 a23 = undefined b31 b32 a31 a32 a33 i.e., matrix multiplication is not commutative (why?) Matrix Multiplication An Example If we have then 1 4 7 1 4 A 2 5 8 and B = 2 5 3 6 9 3 6 1 4 7 1 4 c11 c12 30 66 AB 2 5 8 x 2 5 = c 21 c 22 = 36 81 3 6 9 3 6 c 31 c 32 42 96 where c11 = a11b11 + a12b21 + a13b31 = 1 1 + 4 2 + 7 3 = 30 c12 = a11b12 + a12b22 + a13b32 = 1 4 + 4 5 + 7 6 = 66 c 21 = a21b11 + a22b21 + a23b31 = 2 1 + 5 2 + 8 3 = 36 c 22 = a21b12 + a22b22 + a23b32 = 2 4 + 5 5 + 8 6 = 81 c 31 = a31b11 + a32b21 + a33b31 = 3 1 + 6 2 + 9 3 = 42 c 32 = a31b12 + a32b22 + a33b32 = 3 4 + 6 5 + 9 6 = 96 Some Properties of Matrix Multiplication Note that Even if conformable, AB does not necessarily equal BA (i.e., matrix multiplication is not commutative) Matrix multiplication can be extended beyond two matrices matrix multiplication is associative, i.e., A(BC) = (AB)C Some Properties of Matrix Multiplication Also note that The transpose of a product is equal to the product of the transposes in reverse order (ABC)’ = C’B’A’ If AA’ = A then A' is idempotent (and A' = A) Special Uses for Matrix Multiplication Sum Row Elements of a Matrix Premultiply a matrix A by a conformable row vector of 1s – If 1 4 7 A 2 5 8 3 6 9 then premultiplication by 1 1 1 1 will yield the column totals for A, i.e. 1 4 7 A1 1 1 1 2 5 8 = 6 15 24 3 6 9 Special Uses for Matrix Multiplication Sum Column Elements of a Matrix Postmultiply a matrix A by a conformable column vector of 1s – If 1 4 7 A 2 5 8 3 6 9 then postmultiplication by 1 1 1 1 will yield the column totals for A, i.e. 1 4 7 1 12 A1 2 5 8 1 = 15 3 6 9 1 18 Special Uses for Matrix Multiplication The Dot (or Inner) Product of two Vectors Premultiplication of a column vector a by conformable row vector b yields a single value called the dot product or inner product - If a 3 4 6 then ab gives us and 5 b 2 8 5 ab 3 4 6 2 = 3 5 + 4 2 + 6 8 = 71 8 which is the sum of products of elements in similar positions for the two vectors Special Uses for Matrix Multiplication The Outer Product of two Vectors Postmultiplication of a column vector a by conformable row vector b yields a matrix containing the products of each pair of elements from the two matrices (called the outer product) - If a 3 4 6 then ba gives us and 5 b 2 8 5 15 20 30 ba 2 3 4 6 = 6 8 12 8 24 32 48 Special Uses for Matrix Multiplication Sum the Squared Elements of a Vector Premultiply a column vector a by its transpose – If 5 a 2 8 then premultiplication by a row vector a’ a' 5 2 8 will yield the sum of the squared values of elements for a, i.e. 5 a'a 5 2 8 2 = 52 + 22 + 82 = 93 8 Special Uses for Matrix Multiplication Postmultiply a row vector a by its transpose – If a 7 10 1 then postmultiplication by a column vector a’ 7 a' 10 1 will yield the sum of the squared values of elements for a, i.e. 7 aa' 7 10 1 10 = 72 +102 +12 = 150 1 Special Uses for Matrix Multiplication Determining if two vectors are Orthogonal – Two conformable vectors a and b are orthogonal iff a’b = 0 Example: Suppose we have a 7 10 1 then and b 1 0.5 2 1 ab' 7 10 -1 0.5 = -7 1 +10 0.5 - 1 -2 = 0 2 Special Uses for Matrix Multiplication Representing Systems of Simultaneous Equations – Suppose we have the following system of simultaneous equations: px1 + qx2 + rx3 = M dx1 + ex2 + fx3 = N If we let x1 p q r A , x = x 2 , and b = M d e f N x3 then we can represent the system (in matrix notation) as Ax = b (why?) Special Uses for Matrix Multiplication Linear Independence – any subset of columns (or rows) of a matrix A are said to be linearly independent if no column (row) in the subset can be expressed as a linear combination of other columns (rows) in the subset. If such a combination exists, then the columns (rows) are said to be linearly dependent. Special Uses for Matrix Multiplication The Rank of a matrix is defined to be the number of linearly independent columns (or rows) of the matrix. Nonsingular (Full Rank) Matrix – Any matrix that has no linear dependencies among its columns (rows). For a square matrix A this implies that Ax = 0 iff x = 0. Singular (Not of Full Rank) Matrix – Any matrix that has at least one linear dependency among its columns (rows). Special Uses for Matrix Multiplication Example - The following matrix A 1 2 3 A 3 4 9 6 5 12 is singular (not of full rank) because the third column is equal to three times the first column. This result implies there is either i) no unique solution or ii) no existing solution to the system of equations Ax = 0 (why?). Special Uses for Matrix Multiplication Example - The following matrix A 1 2 5 A 3 4 11 6 5 16 is singular (not of full rank) because the third column is equal to the first column plus two times the second column. Note that the number of linearly independent rows in a matrix will always equal the number of linearly independent columns in the matrix. Geometry of Vectors Vectors have geometric properties of length and direction – for a vector x x x1 2 we have 2 x2 length of x L x x x1 x2 x1 1 x12 x 22 x12 x 22 x'x Why? x p2 Geometry of Vectors Recall the Pythagorean Theorem: in any right triangle, the lengths of the hypotenuse and the other two sides are related by the simple formula. 2 length of hypotenuse L h side a 1 side b L2a L2b x12 x 22 x'x Geometry of Vectors Vector addition – for the vectors we have x y x x1 , y y1 2 2 x1 y1 x 2 y 2 2 y y1 y2 x x1 x2 q 1 x y x + y x 1 y1 2 2 Geometry of Vectors Scalar multiplication changes only the vector length – for the vector we have 2 x x x1 2 length of cx L cx cx c x1 x2 c 2 x12 x 22 c 2 x12 x 22 c x'x 1 x p2 Geometry of Vectors Vector multiplication have angles between them – for the vectors we have x y x x1 , y y1 2 2 xy xy q arccos cos q L L L xL y x y y y1 y2 x x1 x2 2 q 1 xy x'x y'y A Little Trigonometry Review The Unit Circle 2 Cos q = 0 -1 Cos q 0 0 Cos q 1 Cos q = -1 q -1 Cos q 0 Cos q = 1 1 0 Cos q 1 Cos q = 0 A Little Trigonometry Review Suppose we rotate x any y so x lies on 2 axis 1: y y1 y2 x x1 x2 qxy 1 A Little Trigonometry Review What does this imply about rxy? 2 Cos q = 0 -1 Cos q 0 0 Cos q 1 qxy Cos q = -1 Cos q = 1 1 -1 Cos q 0 0 Cos q 1 Cos q = 0 Geometry of Vectors What is the correlation between the 2 vectors x and y? 1.0 -0.5 x 0.6 , y -0.3 Plotting in the column space gives us x 1 y Geometry of Vectors Rotating so x lies on axis 1 makes it 2 easier to see: Qxy=1800 1 Geometry of Vectors What is the correlation between the vectors x and y? 1.0 -0.5 x 0.6 , y -0.3 xy cosq L xL y xy x'x y'y 1.0 -0.5 + 0.6 -0.3 1.0 1.0 0.6 0.6 -0.5 -0.5 -0.3 -0.3 -0.68 = -1.00 1.36 0.34 Geometry of Vectors Of course, we can see this by plotting the these values in the x,y (row) space: 1.0 -0.5 x 0.6 , y -0.3 Y X 0.6, -0.3 1.0, -0.5 Geometry of Vectors What is the correlation between the vectors x and y? 1.0 -0.50 x ,y 0.4 1.25 xy cosq L xL y xy x'x y'y 1.0 -0.50 + 0.4 1.25 1.0 1.0 0.4 0.4 -0.50 -0.50 1.25 1.25 0.00 = 0.00 1.16 1.8125 Geometry of Vectors Plotting in the column space gives us -0.50 y 1.25 2 Qxy=900 1.0 x 0.4 1 Geometry of Vectors Rotating so x lies on axis 1 makes it 2 easier to see: Qxy=900 1 Geometry of Vectors The space of all real m-tuples, with scalar multiplication and vector addition as we have defined, is called vector space. The vector y a1x1 a2x2 ak xk is a linear combination of the vectors x1, x2,…, xk. The set of all linear combinations of the vectors x1, x2,…, xk is called their linear span. Geometry of Vectors Here is the column space plot for some vectors x1 and x2: 3 -0.50 x2 0.50 1.50 1.00 x1 0.40 0.20 1 2 Geometry of Vectors Here is the linear span for some vectors x1 and x2: 3 1 2 Geometry of Vectors A set of vectors x1, x2,…, xk is said to be linearly dependent if there exist k numbers a1, a2,…, ak, at least one of which is nonzero, such that a1x1 a2x2 ak xk 0 Otherwise the set of vectors x1, x2,…, xk is said to be linearly independent Geometry of Vectors Are the vectors 1.0 -0.5 x 0.6 , y -0.3 linearly independent? Take a1 = 0.5 and a2 = 1.0. Then we have 1.0 -0.5 0.0 a1x a2y 0.5 0.6 1.0 -0.3 0.0 The vectors x and y are dependent. Geometry of Vectors Geometrically x and y look like this: 2 1.0 x 0.6 1 -0.5 y -0.3 Geometry of Vectors Rotating so x lies on axis 1 makes it 2 easier to see: Qxy=1800 1 Geometry of Vectors Are the vectors 1.0 -0.50 x ,y 0.4 1.25 linearly independent? There are no real values a1, a2 such that 1.0 -0.50 0.0 a1x a2y a1 a2 0.4 1.25 0.0 so the vectors x and y are independent. Geometry of Vectors Geometrically x and y look like this: -0.50 y 1.25 2 Qxy=900 1.0 x 0.4 1 Geometry of Vectors Rotating so x lies on axis 1 makes it 2 easier to see: Qxy=900 1 Geometry of Vectors Here x and y are called perpendicular (or orthogonal) – this is written x y. Some properties of orthogonal vectors: x’y = 0 x y z is perpendicular to every vector iff z = 0 If z is perpendicular to each vector x1, x2, …, xk, then z is perpendicular their linear span. Geometry of Vectors Here vectors x1 and x2 (plotted in the column space) are orthogonal 3 -0.50 x2 0.50 1.50 1.00 x1 0.40 0.20 1 2 Geometry of Vectors Recall that the linear span for vectors x1 and x2 is: 3 1 2 Geometry of Vectors Vector z looks like this: 3 0.10 z -0.32 0.14 0.10 z -0.32 0.14 1 2 Geometry of Vectors The vector z is perpendicular to the linear span for vectors x1 and x2: 3 0.10 z -0.32 0.14 Check each of the dot products! 1 2 Geometry of Vectors Here vectors x1, x2, and z from our previous problem are orthogonal 3 -0.50 x2 0.50 1.50 0.10 z -0.32 0.14 1.00 x1 0.40 0.20 2 x1 and z are perpendicular 1 Geometry of Vectors Here vectors x1, x2, and z from our previous problem are orthogonal 3 -0.50 x2 0.50 1.50 0.10 z -0.32 0.14 1.00 x1 0.40 0.20 2 x2 and z are perpendicular 1 Geometry of Vectors Here vectors x1, x2, and z from our previous problem are orthogonal 3 -0.50 x2 0.50 1.50 x1 and x2 are perpendicular 0.10 z -0.32 0.14 1.00 x1 0.40 0.20 2 1 Note we could rotate x1, x2, and z until they lied on our three axes! Geometry of Vectors The projection (or shadow) of a vector x on a vector y is given by: x'y y 2 Ly If y has unit length (i.e., Ly = 1), the projection (or shadow) of a vector x on a vector y simplifies to (x’y)y Geometry of Vectors For the vectors 0.6 0.8 x ,y 1.0 0.3 the projection (or shadow) of x on y is: 0.8 0.6 1.0 0.3 x'y y = 2 0.8 Ly 0.8 0.3 0.3 0.8 = 1.0685 0.3 = 0.8 = 0.78 0.8 0.3 0.73 0.3 0.8548 0.3205 Geometry of Vectors Geometrically the projection of x on y 2 looks like this: projection of x on y 0.6 x 1.0 0.8 y 0.3 Perpendicular wrt y 1 Geometry of Vectors Rotating so y lies on axis 1 makes it 2 easier to see: 1 Geometry of Vectors Note that we write the length of the projection of x on y like this: x'y Ly = Lx x'y L x cosq xy L xL y For our previous example, the length of the length of the projection of x on y is: 0.8 0.6 1.0 0.3 x'y = 0.912921 Ly 0.8 0.8 0.3 0.3 The Gram-Schmidt (Orthogonalization) Process For linearly independent vectors x1, x2,…, xk, there exist mutually perpendicular vectors u1, u2,…, uk with the same linear span. These may be constructed by setting: u1 x1 u2 x 2' u1 x2 ' u1 u1u1 uk x k x 2' u1 ' u1 x1 u1u1 x k' uk -1 ' uk -1 uk -1uk -1 The Gram-Schmidt (Orthogonalization) Process We can normalize (convert to vectors z of unit length) the vectors u by setting zj uj u'ju j Finally, note that we can project a vector xk onto the linear span of vectors x1, x2,…, xk-1: k -1 j=1 x'k z j The Gram-Schmidt (Orthogonalization) Process Here are vectors x1, x2, and z from our previous problem: 3 -0.50 x2 0.50 1.50 0.10 z -0.32 0.14 1.00 x1 0.40 0.20 1 2 The Gram-Schmidt (Orthogonalization) Process Let’s construct mutually perpendicular vectors u1, u2, u3 with the same linear span – we’ll arbitrarily select the first axis as u1: 0.00 u1 0.00 1.00 The Gram-Schmidt (Orthogonalization) Process Now we construct a vector u2 perpendicular with vector u1 (and in the linear span of x1, x2, z): u2 1.50 0.00 1.50 0.50 -0.50 0.00 0.50 -0.50 1.00 0.00 0.00 1.00 0.00 0.00 0.00 1.50 1.00 0.50 0.00 -0.50 -0.50 0.50 1.50 0.00 1.00 0.00 0.00 1.00 The Gram-Schmidt (Orthogonalization) Process Finally, we construct a vector u3 perpendicular with vectors u1 and u2 (and in the linear span of x1, x2, z): The Gram-Schmidt (Orthogonalization) Process 0.14 0.00 1.50 0.1025 -0.32 0.10 0.00 0.25 0.50 -0.3325 0.10 1.00 0.00 0.0000 1.50 0.00 0.50 1.50 0.50 0.00 1.50 1.50 0.50 0.10 -0.32 0.14 0.50 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.14 1.00 0.00 u1' u1 u2' u2 0.00 u3 z u1 x1 u2 -0.32 1 2 z' u z' u 0.00 1.00 0.10 0.10 -0.32 0.14 0.00 1.00 The Gram-Schmidt (Orthogonalization) Process Here are our orthogonal vectors u1, u2, and u3: 3 0.00 u2 0.50 1.50 0.0000 u3 -0.3325 0.1025 1.00 u1 0.00 0.00 2 1 The Gram-Schmidt (Orthogonalization) Process If we normalized our vectors u1, u2, and u3, we get: z1 u1 u1' u1 1.0000 0.0000 0.0000 1.0000 1.0000 0.0000 0.0000 0.0000 0.0000 1.0 1.0 1.0000 1.0000 0.0000 0.0000 0.0000 0.0000 The Gram-Schmidt (Orthogonalization) Process and: z2 u2 u2' u2 0.0000 0.5000 1.5000 0.0000 0.0000 0.5000 1.5000 0.5000 1.5000 1.0 2.5 0.0000 0.0000 0.5000 0.3162 1.5000 0.9487 The Gram-Schmidt (Orthogonalization) Process and: z3 u3 u'3u3 0.0000 -0.3325 0.1025 0.0000 0.0000 -0.3325 0.1025 -0.3325 0.1025 1.0 0.1211 0.0000 0.0000 -0.3325 -0.9556 0.1025 0.2946 The Gram-Schmidt (Orthogonalization) Process The normalized vectors z1, z2, and z3 look like this: 3 0.0000 z2 0.3162 0.9487 0.0000 z3 -0.9556 0.2946 1.00 z1 0.00 0.00 2 1 Special Matrices There are a number of special matrices. These include Diagonal Matrices Identity Matrices Null Matrices Commutative Matrices Anti-Commutative Matrices Periodic Matrices Idempotent Matices Nilpodent Matrices Orthogonal Matrices Diagonal Matrices A diagonal matrix is a square matrix that has values on the diagonal with all off-diagonal entities being zero. a11 0 0 0 0 a22 0 0 0 0 a33 0 0 0 0 a44 Identity Matrices An identity matrix is a diagonal matrix where the diagonal elements all equal 1 1 I 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 When used as a premultiplier or postmultiplier of any conformable matrix A, the Identity Matrix will return the original matrix A, i.e., IA = AI = A Why? Null Matrices A square matrix whose elements all equal 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Usually arises as the difference between two equal square matrices, i.e., a–b=0a=b Commutative Matrices Any two square matrices A and B such that AB = BA are said to commute. Note that it is easy to show that any square matrix A commutes with both itself and with a conformable identity matrix I. Anti-Commutative Matrices Any two square matrices A and B such that AB = -BA are said to anticommute. Periodic Matrices Any matrix A such that Ak+1 = A is said to be of period k. Of course any matrix that commutes with itself of period k for any integer value of k (why?). Idempotent Matrices Any matrix A such that A2 = A is said to be of idempotent. Thus an idempotent matrix commutes with itself if of period k for any integer value of k. Nilpotent Matrices Any matrix A such that Ap = 0 where p is a positive integer is said to be of nilpotent. Note that if p is the least positive integer such that Ap = 0, then A is said to be nilpotent of index p. Orthogonal Matrices Any square matrix A with rows (considered as vectors) are mutually perpendicular and have unit lengths, i.e., A’A = I Note that A is orthogonal iff A-1 = A’. The Determinant of a Matrix The determinant of a matrix A is commonly denoted by |A| or det A. Determinants exist only for square matrices. They are a matrix characteristic (that can be somewhat tedious to compute). The Determinant for a 2x2 Matrix If we have a matrix A such that then A a11 a21 a12 a22 A = a11a22 - a12 a21 For example, the determinant of is A 1 2 3 4 A = 1 2 = a11a22 - a12a21 1 4 - 2 3 = -2 3 4 Determinants for 2x2 matrices are easy! The Determinant for a 3x3 Matrix If we have a matrix A such that a11 A a21 a31 a12 a22 a32 a13 a23 a33 Then the determinant is det A = A = a11 a22 a32 a23 a - a12 21 a33 a31 a23 a + a13 21 a31 a33 a22 a32 which can be expanded and rewritten as det A = A = a11a22a33 - a11a23a32 + a12a23a31 - a12 a21a33 + a13 a21a32 - a13 a22 a31 (Why?) The Determinant for a 3x3 Matrix If we rewrite the determinants for each of the 2x2 submatrices in det A = A = a11 as a22 a32 a23 a - a12 21 a33 a31 a23 a + a13 21 a31 a33 a22 a32 a23 =a22 a33 - a23a32 , a33 a21 a31 a23 =a21a33 - a23a31 , and a33 a21 a31 a22 =a21a32 - a22 a31 a32 a22 a32 by substitution we have A = a11a22a33 - a11a23a32 + a12a23a31 - a12a21a33 + a13a21a32 - a13a22a31 The Determinant for a 3x3 Matrix Note that if we have a matrix A such that a11 A a21 a31 a12 a22 a32 a13 a23 a33 Then |A| can also be written as det A = A = a11 a22 a32 a23 a - a12 21 a33 a31 det A = A = -a21 a12 a32 a13 a + a22 11 a33 a31 det A = A = a31 a12 a22 a13 a - a32 11 a23 a21 or or a23 a + a13 21 a31 a33 a22 a32 a23 a - a23 11 a31 a33 a12 a32 a13 a + a33 11 a23 a21 a12 a22 The Determinant for a 3x3 Matrix To do so first create a matrix of the same dimensions as A consisting only of alternating signs (+,-,+,…) + - + - + - + - + The Determinant for a 3x3 Matrix Then expand on any row or column (i.e., multiply each element in the selected row/column by the corresponding sign, then multiply each of these results by the determinant of the submatrix that results from elimination of the row and column to which the element belongs For example, let’s expand on the second column a a a 11 A a21 a31 12 a22 a32 13 a23 a33 The Determinant for a 3x3 Matrix The three elements on which our expansion is based will be a12, a22, and a32. The corresponding signs are -, +, -. + - + - + - + - + The Determinant for a 3x3 Matrix So for the first term of our expansion we will multiply -a12 by the determinant of the matrix formed when row 1 and column 2 are eliminated from A (called the minor and often denoted Arc where r and c are the deleted rows and columns): a11 A a21 a31 a12 a22 a32 which gives us a13 a a23 so A12 21 a31 a33 -a12 a21 a31 a23 a33 a23 a33 This product is called a cofactor. The Determinant for a 3x3 Matrix For the second term of our expansion we will multiply a22 by the determinant of the matrix formed when row 2 and column 2 are eliminated from A: a11 A a21 a31 a12 a22 a32 a13 a a23 so A 22 11 a31 a33 which gives us a22 a11 a31 a13 a33 a13 a33 The Determinant for a 3x3 Matrix Finally, for the third term of our expansion we will multiply -a32 by the determinant of the matrix formed when row 3 and column 2 are eliminated from A: a11 A a21 a31 a12 a22 a32 a13 a a23 so A 22 11 a21 a33 which gives us -a32 a11 a21 a13 a23 a13 a23 The Determinant for a 3x3 Matrix Putting this all together yields det A = A = -a12 a21 a31 a23 a + a22 11 a33 a31 a13 a - a32 11 a33 a21 a13 a23 So there are nine distinct ways to calculate the determinant of a 3x3 matrix! These can be expressed as m det A = A = aij -1 j=1 i+j n Aij = aij -1 i=1 i+j Aij Note that this is referred to as the method of cofactors and can be used to find the determinant of any square matrix. The Determinant for a 3x3 Matrix – An Example Suppose we have the following matrix A: 1 2 3 A = 2 5 4 1 -3 -2 Using row 1 (i.e., i=1), the determinant is: m det A = A = a1j -1 j=1 1+j A1j 1(2) 2(8) 3(11) 15 Note that this is the same result we would achieve using any other row or column! Some Properties of Determinants Determinants have several mathematical properties useful in matrix manipulations: |A|=|A'| If each element of a row (or column) of A is 0, then |A|= 0 If every value in a row is multiplied by k, then |A| = k|A| If two rows (or columns) are interchanged the sign, but not value, of |A| changes If two rows (or columns) of A are identical, |A| = 0 Some Properties of Determinants |A| remains unchanged if each element of a row is multiplied by a constant and added to any other row If A is nonsingular, then |A|=1/|A-1|, i.e., |A||A-1|=1 |AB|= |A||B| (i.e., the determinant of a product = product of the determinants) For any scalar c, |cA| = ck|A| where k is the order of A Determinant of a diagonal matrix is simply the product of the diagonal elements Why are Determinants Important? Consider the small system of equations: a11x1 + a12x2 = b1 a21x1 + a22x2 = b2 Which can be represented by: Ax = b where A = a11 a12 , x = x1 , and b = b1 a21 a22 x 2 b 2 Why are Determinants Important? If we were to solve this system of equations simultaneously for x2 we would have: a21(a11x1 + a12x2 = b1) -a11(a21x1 + a22x2 = b2) Which yields (through cancellation & rearranging): a21a11x1 + a21a12x2 - a11a21x1 - a11a22x2 = a21b1 - a11b2 Why are Determinants Important? or (a11a2 - a21a12)x2 = a11b2 - a21b1 which implies a11b2 a21b1 x2= a11a22 - a12a21 Notice that the denominator is: A = a11a22 - a12 a21 Thus iff |A|= 0 there is either i) no unique solution or ii) no existing solution to the system of equations Ax = b! Why are Determinants Important? This result holds true: if we solve the system for x1 as well; or for a square matrix A of any order. Thus we can use determinants in conjunction with the A matrix (coefficient matrix in a system of simultaneous equations) to see if the system has a unique solution. Traces of Matrices The trace of a square matrix A is the sum of the diagonal elements Denoted tr(A) We have n m tr A = aii = ajj i=1 j=1 For example, the trace of is n A 1 2 3 4 tr A = aii = 1 + 4 = 5 i=1 Some Properties of Traces Traces have several mathematical properties useful in matrix manipulations: For any scalar c, tr(cA) = c[tr(A)] tr(A B) = tr(A) tr(B) tr(AB) = tr(BA) tr(B-1AB) = tr(A) n m tr AA' = aij2 i=1 j=1 The Inverse of a Matrix The inverse of a matrix A is commonly denoted by A-1 or inv A. The inverse of an n x n matrix A is the matrix A-1 such that AA-1 = I = A-1A The matrix inverse is analogous to a scalar reciprocal A matrix which has an inverse is called nonsingular The Inverse of a Matrix For some n x n matrix A an inverse matrix A-1 may not exist. A matrix which does not have an inverse is singular. An inverse of n x n matrix A exists iff |A|0 Inverse by Simultaneous Equations Pre or postmultiply your square matrix A by a dummy matrix of the same dimensions, i.e., AA 1 a11 a21 a31 a12 a22 a32 a13 a b c a23 d e f a33 g h i Set the result equal to an identity matrix of the same dimensions as your square matrix A, i.e., AA 1 a11 a21 a31 a12 a22 a32 a13 a b c 1 0 0 a23 d e f 0 1 0 a33 g h i 0 0 1 Inverse by Simultaneous Equations Recognize that the resulting expression implies a set of n2 simultaneous equations that must be satisfied if A-1 exists: a11(a) + a12(d) + a13(g) = 1, a11(c) + a12(f) + a13(i) = 0; a11(b) + a12(e) + a13(h) = 0, a21(a) + a22(d) + a23(g) = 0, a21(c) + a22(f) + a23(i) = 0; a21(b) + a22(e) + a23(h) = 1, a31(a) + a32(d) + a33(g) = 0, a31(c) + a32(f) + a33(i) = 1. a31(b) + a32(e) + a33(h) = 0, or or Solving this set of n2 equations simultaneously yields A-1. Inverse by Simultaneous Equations – An Example If we have 1 2 3 A = 2 5 4 1 -3 -2 Then the postmultiplied matrix would be AA 1 1 2 3 a b c 2 5 4 d e f 1 -3 -2 g h i We now set this equal to a 3x3 identity matrix 1 2 3 a b c 1 0 0 2 5 4 d e f 0 1 0 1 -3 -2 g h i 0 0 1 Inverse by Simultaneous Equations – An Example Recognize that the resulting expression implies the following n2 simultaneous equations: 1a + 2d + 3g = 1, 1b + 2e + 3h = 0, 1c + 2f + 3i = 0; or 2a + 5d + 4g = 0, 2b + 5e + 4h = 1, 2c + 5f + 4i = 0; or 1a - 3d - 2g = 0, 1b - 3e - 2h = 0, 1c - 3f - 2i = 1. This system can be satisfied iff A-1 exists. Inverse by Simultaneous Equations – An Example Solving the set of n2 equations simultaneously yields: a = -2/15, b = 1/3, c = 7/3, d = -8/15, e = 1/3, f = -2/3’ g = 11/15, h =-1/3, i = -1/15 so we have that A-1 -2 1 7 15 3 15 1 -2 A -1 = -8 1115 -13 -115 15 3 15 Inverse by Simultaneous Equations – An Example ALWAYS check your answer. How? Use the fact that AA-1= A-1A =I and do a little matrix multiplication! -2 1 7 3 15 1 0 0 1 2 3 15 1 -2 0 1 0 I 3x3 AA -1 = 2 5 4 -8 1 -3 -2 1115 -13 -115 0 0 1 15 3 15 So we have found A-1! Inverse by the Gauss-Jordan Algorithm Augment your matrix A with an identity matrix of the same dimensions, i.e., a11 a12 A | I a21 a22 a 31 a32 a13 1 0 0 a23 0 1 0 a33 0 0 1 Now we use valid Row Operations necessary to convert A to I (and so A|I to I|A-1) Inverse by the Gauss-Jordan Algorithm Valid Row Operations on A|I You may interchange rows You may multiply a row by a scalar You may replace a row with the sum of that row and another row multiplied by a scalar (which is often negative) Every operation performed on A must be performed on I Use valid Row Operations on A|I to convert A to I (and so A|I to I|A-1) Inverse by the Gauss-Jordan Algorithm – An Example If we have 1 2 3 A = 2 5 4 1 -3 -2 Then the augmented matrix A|I is 1 2 3 1 0 0 A | I 2 5 4 0 1 0 1 -3 -2 0 0 1 We now wish to use valid row operations to convert the A side of this augmented matrix to I Inverse by the Gauss-Jordan Algorithm – An Example Step 1: Subtract 2·Row 1 from Row 2 2 5 4 0 - 2 1 2 3 1 1 0 0 0 0 1 -2 -2 -1 0 And substitute the result for Row 2 in A|I 1 2 3 1 0 0 0 1 -2 -2 1 0 1 -3 -2 0 0 1 Inverse by the Gauss-Jordan Algorithm – An Example Step 2: Subtract Row 3 from Row 1 1 2 31 0 - 1 -3 -2 0 0 0 5 0 1 5 1 0 -1 Divide the result by 5 and substitute for Row 3 in the matrix derived in the previous step 1 2 3 1 0 0 0 1 -2 -2 1 0 0 1 1 1 5 0 -1 5 Inverse by the Gauss-Jordan Algorithm – An Example Step 3: Subtract Row 2 from Row 3 0 1 1 1 5 0 1 -2 - 2 0 0 3 11 0 -1 5 1 0 -1 -1 5 5 Divide the result by 3 and substitute for Row 3 in the matrix derived in the previous step 1 2 3 1 0 0 0 1 -2 -2 1 0 0 0 1 1115 -1 3 -115 Inverse by the Gauss-Jordan Algorithm – An Example Step 4: Subtract 2·Row 2 from Row 1 1 2 3 1 2 0 1 -2 - 2 1 0 0 0 1 0 7 5 -2 0 Substitute the result for Row 1 in the matrix derived in the previous step 1 0 7 5 -2 0 0 1 -2 -2 1 0 0 0 1 1115 -1 3 -115 Inverse by the Gauss-Jordan Algorithm – An Example Step 5: Subtract 7·Row 3 from Row 1 1 0 7 0 0 1 0 0 7 5 -2 1 11 15 -1 -1 3 15 0 -2 1 7 15 3 15 Substitute the result for Row 1 in the matrix derived in the previous step -2 1 7 1 0 0 15 3 15 1 0 0 1 -2 -2 0 0 1 1115 -1 3 -115 Inverse by the Gauss-Jordan Algorithm – An Example Step 6: Add 2·Row 3 to Row 2 0 1 -2 - 2 2 0 0 1 11 15 0 1 0 -8 15 0 1 -1 1 -1 3 15 3 -2 15 Substitute the result for Row 2 in the matrix derived in the previous step -2 1 7 3 15 1 0 0 15 0 1 0 -8 15 1 3 -215 0 0 1 11 -1 -1 15 3 15 Inverse by the Gauss-Jordan Algorithm – An Example Now that the left side of the augmented matrix is an identity matrix I, the right side of the augmented matrix is the inverse of the matrix A (A-1), i.e., A 1 1 7 -2 3 15 15 1 -2 -8 15 3 15 11 -1 -1 15 3 15 Inverse by the Gauss-Jordan Algorithm – An Example To check our work, let’s see if our result yields AA-1 = I: AA 1 1 7 -2 3 15 1 0 0 1 2 3 15 1 -2 0 1 0 2 5 4 -8 1 -3 -2 1115 -13 -115 0 0 1 15 3 15 So our work checks out! Inverse by Determinants Replace each element aij in a matrix A with an element calculated as follows: Find the determinant of the submatrix that results when the ith row and jth column are eliminated from A (i.e., Aij) Attach the sign that you identified in the Method of Cofactors Divide by the determinant of A After all elements have been replaced, transpose the resulting matrix Inverse by Determinants – An Example Again suppose we have some matrix A: 1 2 3 A 2 5 4 1 -3 -2 We have calculated the determinant of A to be –15, so we replace element 1,1 with 11 1 A11 1 2 15 215 A Similarly, we replace element 1,2 with 1 2 1 A12 1 8 15 815 A Inverse by Determinants – An Example After using this approach to replace each of the nine elements of A, The eventual result will be 1 7 -2 3 15 15 -8 15 1 3 -215 11 -1 -1 15 3 15 which is A-1! Eigenvalues and Eigenvectors For a square matrix A, let I be a conformable identity matrix. Then the scalars satisfying the polynomial equation |A - lI| = 0 are called the eigenvalues (or characteristic roots) of A. The equation |A - lI| = 0 is called the characteristic equation or the determinantal equation. Eigenvalues and Eigenvectors For example, if we have a matrix A: A 2 4 4 -4 then A lI 2 4 l 1 0 4 -4 0 1 4 2 l 4 l 16 0 2-l 4 -4 - l or l 2 2l 24 0 which implies there are two roots or eigenvalues -- l=-6 and l=4. Eigenvalues and Eigenvectors For a matrix A with eigenvectors l, a nonzero vector x such that Ax = lx is called an eigenvector (or characteristic vector) of A associated with l. Eigenvalues and Eigenvectors For example, if we have a matrix A: A 2 4 4 -4 with eigenvalues l = -6 and l = 4, the eigenvector of A associated with l = -6 is x1 2 4 x1 Ax lx 6 4 -4 x 2 x 2 2x 1 4x 2 6x 1 8x 1 4x 2 0 and 4x 1 4x 2 6x 2 4x 1 2x 2 0 Fixing x1=1 yields a solution for x2 of –2. Eigenvalues and Eigenvectors Note that eigenvectors are usually normalized so they have unit length, i.e., e x x'x For our previous example we have: e x x'x 1 -2 1 1 -2 5 -2 5 1 1 -2 5 -2 Thus our arbitrary choice to fix x1=1 has no impact on the eigenvector associated with l = -6. Eigenvalues and Eigenvectors For matrix A and eigenvalue l = 4, we have Ax lx 2 4 x1 4 x1 4 -4 x 2 x 2 2x 1 4x 2 4x 1 2x 1 4x 2 0 and 4x 1 4x 2 4x 2 4x 1 8x 2 0 We again arbitrarily fix x1=1, which now yields a solution for x2 of 1/2. Eigenvalues and Eigenvectors Normalization to unit length yields e x x'x 1 1 2 1 1 1 1 2 2 2 5 1 5 5 1 1 1 1 5 4 2 2 2 Again our arbitrary choice to fix x1=1 has no impact on the eigenvector associated with l = 4. Quadratic Forms A Quadratic From is a function Q(x) = x’Ax in k variables x1,…,xk where x1 x2 x xk and A is a k x k symmetric matrix. Quadratic Forms Note that a quadratic form has only squared terms and crossproducts, and so can be written k k Q x aij x i x j Suppose we have then i1 j1 x x 1 and A 1 4 0 2 x 2 Q(x) = x'Ax = x12 + 4x1 x 2 - 2x 22 Spectral Decomposition and Quadratic Forms Any k x k symmetric matrix can be expressed in terms of its k eigenvalueeigenvector pairs (li, ei) as k A l ie ie i1 ' i This is referred to as the spectral decomposition of A. Spectral Decomposition and Quadratic Forms For our previous example on eigenvalues and eigenvectors we showed that 2 4 A 4 4 has eigenvalues l1 = -6 and l2 = -4, with corresponding (normalized) eigenvectors 1 2 5 5 e1 ,e , -2 2 1 5 5 Spectral Decomposition and Quadratic Forms Can we reconstruct A? k A l ie ie i1 ' i 1 2 1 2 5 5 -2 6 +4 -2 1 5 5 5 5 5 1 -2 4 2 6 5 5 4 5 5 2 4 A -2 5 4 5 2 5 1 5 4 4 1 5 Spectral Decomposition and Quadratic Forms Spectral decomposition can be used to develop/illustrate many statistical results/ concepts. We start with a few basic concepts: - Nonnegative Definite Matrix – when any k x k matrix A such that 0 x’Ax x’ =[x1, x2, …, xk] the matrix A and the quadratic form are said to be nonnegative definite. Spectral Decomposition and Quadratic Forms - Positive Definite Matrix – when any k x k matrix A such that 0 < x’Ax x’ =[x1, x2, …, xk] [0, 0, …, 0] the matrix A and the quadratic form are said to be positive definite. Spectral Decomposition and Quadratic Forms Example - Show that the following quadratic form is positive definite: 6x12 + 4x 22 - 4 2x1x 2 We first rewrite the quadratic form in matrix notation: Q( x) = x1 6 x1 -2 2 x 2 = x ' Ax x 2 -2 2 4 Spectral Decomposition and Quadratic Forms Now identify the eigenvalues of the resulting matrix A (they are l1 = 2 and l2 = 8). 6 1 0 -2 2 A lI l 0 1 -2 2 4 6 - l -2 2 6 l 4 l -2 2 -2 2 0 -2 2 4 - l or l 2 10l 16 l 2 l 8 0 Spectral Decomposition and Quadratic Forms Next, using spectral decomposition we can write: k A l ieiei' l1e1e1' l 2 e 2 e 2' 2e1e1' 8e 2 e 2' i1 where again, the vectors ei are the normalized and orthogonal eigenvectors associated with the eigenvalues l1 = 2 and l2 = 8. Spectral Decomposition and Quadratic Forms Sidebar - Note again that we can recreate the original matrix A from the spectral decomposition: k A l ie ie i' i1 1 1 3 2 2 3 3 1 2 3 2 3 2 3 2 2 +8 -1 3 3 3 2 2 3 8 3 3 2 2 1 3 3 3 2 -1 3 6 2 2 2 4 2 A Spectral Decomposition and Quadratic Forms Because l1 and l2 are scalars, premultiplication and postmultiplication by x’ and x, respectively, yield: ' ' ' 1 ' ' 2 2 1 2 2 x Ax 2x e1e x 8x e2e x 2y + 8y 0 where ' ' 1 ' ' 2 y1 x e1 e x1 and y 2 x e2 e x 2 At this point it is obvious that x’Ax is at least nonnegative definite! Spectral Decomposition and Quadratic Forms We now show that x’Ax is positive definite, i.e. x ' Ax 2y12 + 8y 22 0 From our definitions of y1 and y2 we have ' y1 e1 x1 or y Ex ' y 2 e2 x 2 Spectral Decomposition and Quadratic Forms Since E is an orthogonal matrix, E’ exists. Thus, ' x Ey But 0 x = E’y implies y 0 . At this point it is obvious that x’Ax is positive definite! Spectral Decomposition and Quadratic Forms This suggests rules for determining if a k x k symmetric matrix A (or equivalently, its quadratic form x’Ax) is nonegative definite or positive definite: - A is a nonegative definite matrix iff li 0, i = 1,…,rank(A) - A is a positive definite matrix iff li > 0, i = 1,…,rank(A) Measuring Distance Euclidean (straight line) distance – The Euclidean distance between two points x and y (whose coordinates are represented by the elements of the corresponding vectors) in p-space is given by d(x , y) x y1 + 2 1 + xp yp 2 Measuring Distance For a previous example 3 0.0000 z2 0.3162 0.9487 0.0000 z3 -0.9556 0.2946 1.00 z1 0.00 0.00 1 2 the Euclidean (straight line) distances are Measuring Distance d(z1 , z 2 ) d(z1 , z 3 ) d(z 2 , z 3 ) 1.00 0.00 + 0.00 0.3162 + 0.00 0.9487 1.00 0.00 + 0.00 0.9556 + 0.00 0.2946 2 2 2 1.414 2 2 2 1.414 0.00 0.00 + 0.3162 0.9556 + 0.9487 0.2946 1.430 2 2 2 3 0.0000 z2 0.3162 0.9487 1.430 0.0000 z3 -0.9556 0.2946 1.414 1.414 2 1.00 z1 0.00 0.00 1 Measuring Distance Notice that the lengths of the vectors are their distances from the origin: d(0, P) x 0 + 2 1 x12 + + xp 0 2 + x p2 This is yet another place where the Pythagorean Theorem rears its head! Measuring Distance Notice also that if we connect all points equidistant from some given point z, the result is a hypersphere with its center at z and area of pr2: 2 In p=2 dimensions this yields a circle z r 1 Measuring Distance In p = 2 dimensions, we actually talk about area. In p 3 dimensions, we talk about volume - which is 4/3pr3 for this n n2 problem or, more generally r p 3 In p=3 dimensions we have a sphere z n 1 2 r 1 2 Measuring Distance Problem – What if the coordinates of a point x (i.e., the elements of vector x) are random variables with differing variances? Suppose - we have n pairs of measurements on two variables X1 and X2, each having a mean of zero - X1 is more variable than X2 - X1 and X2 vary independently Measuring Distance A scatter diagram of these data might look like this: Which point really lies further from the origin in statistical terms (i.e., which point is less likely to have occurred randomly)? 2 1 Euclidean distance does not account for differences in variation of X1 and X2! Measuring Distance Notice that a circle does not efficiently inscribe the data: 2 r2 The area of the ellipse is pr1r2. r1 1 An ellipse does so much more efficiently! Measuring Distance How do we take the relative dispersions on the two axes into consideration? 2 1 We standardize each value of Xi by dividing by its standard deviation. Measuring Distance Note that the problem can extend beyond two dimensions. 3 The area of the ellipsoid is (4/3)pr1r2r3 or more generally 1 n n2 r p i1 n 1 2 2 Measuring Distance If we are looking at distances from the origin D(0,P), we could divide coordinate i by its sample standard deviation sii: * i x = xi s ii Measuring Distance The resulting measure is called Statistical Distance or Mahalanobis Distance: d(0, P) x * 1 2 x 1 s11 x1 has a relative 1 weight of k 1 s11 2 1 x + s11 + + x 2 2 x + p s pp + + * p x 2 p s pp 2 x p has a relative 1 weight of k p s pp Measuring Distance Note that if we plot all points a constant squared distance c2 from the origin: c s 22 2 c s11 c s11 1 The area of this ellipse is p c s11 c s 22 c s 22 all points that satisfy 2 2 x x d2 0, P 1 + + p =c 2 s11 s pp Measuring Distance What if the scatter diagram of these data looked like this: 2 1 X1 and X2 now have an obvious positive correlation! Measuring Distance We can plot a rotated coordinate system ~ ~ on axes x1 and x2: 2 Q 1 This suggests that we calculate distance ~ ~ based on the rotated axes x1 and x2. Measuring Distance The relation between the original coordinates (x1, x2) and the rotated ~ ~ coordinates (x1, x2) is provided by: x1=x1 cos q x 2 sin q x 2 =-x1 sin q x 2 cos q Measuring Distance Now we can write the distance from P = ~ ~ (x1, x2) to the origin in terms of the original coordinates x1 and x2 of P as 2 11 1 d(0, P) a x + 2a12 x1x 2 + a22 x where a11 2 2 cos 2 q cos 2 q s11 2 sin q cos q s12 sin2 q s 22 sin2 q cos 2 q s 22 2 sin q cos q s12 sin2 q s 11 Measuring Distance a22 sin2 q cos q s11 2 sin q cos q s12 sin q s 22 2 2 cos q 2 cos 2 q s 22 2 sin q cos q s12 sin2 q s 11 and a12 cos q sin q cos q s11 2 sin q cos q s12 sin q s 22 2 2 sin q cos q cos 2 q s 22 2 sin q cos q s12 sin2 q s 11 Measuring Distance Note that the distance from P = (x1, x2) to the origin for uncorrelated coordinates x1 and x2 is d(0, P) a11x12 + 2a12 x1x 2 + a22 x 22 for weights 1 aij s ij Measuring Distance What if we wish to measure distance from some fixed point Q = (y1, y2)? 2 Q=(y1, y2) 1 _ _ In this diagram, Q = (y1, y2) = (x1, x2) is called the centroid of the data. Measuring Distance The distance from any point p to some fixed point Q = (y1, y2) is 2 P=(x1, x2) Q=(y1, y2) Q 1 d(P, Q) a11 x1 y1 + 2a12 x1 y1 x 2 y 2 + a22 x 2 y 2 2 2 Measuring Distance Suppose we have the following ten bivariate observations (coordinate sets of (x1, x2)): Obs # x x 1 2 3 4 5 6 7 8 9 10 xi 1 2 -3 -2 -1 -2 -3 -1 -3 -3 0 -2 -2.0 3 6 4 4 6 6 2 5 7 7 5.0 Measuring Distance The plot of these points would look like this: 2 Centroid (-2, 5) 1 The data suggest a positive correlation between x1, and x2. Measuring Distance The inscribing ellipse (and major and minor axes) look like this: 2 Q450 1 Measuring Distance The rotational weights are: a11 45 1.11 2 sin 45 cos 45 0.8 sin 45 2.89 cos 2 450 cos 2 0 0 0 sin2 q 2 0 cos 2 450 2.89 2 sin 450 cos 450 0.8 sin2 450 1.11 0.6429 Measuring Distance and: a22 cos 45 1.11 2 sin 45 cos 45 0.8 sin 45 2.89 sin2 450 2 0 0 0 cos 2 q 2 0 cos 2 450 2.89 2 sin 450 cos 450 0.8 sin2 450 1.11 0.6429 Measuring Distance and: a12 cos 45 1.11 2 sin 45 cos 45 0.8 sin 45 2.89 cos q sin 45 cos 45 2.89 2 sin 45 cos 45 0.8 sin 45 1.11 sin 450 cos 450 2 0 0 0 2 0 2 0 0 2 0 0.3571 0 0 Measuring Distance So the distances of the observed points from their centroid Q = (-2.0, 5.0) are: Obs # x1 x2 x1 x2 ~ Euclidean D(P,Q) 1 2 3 4 5 6 7 8 9 10 xi -3 -2 -1 -2 -3 -1 -3 -3 0 -2 -2.0 3 6 4 4 6 6 2 5 7 7 5.0 0.0000 2.8284 2.1213 1.4142 2.1213 3.5355 -0.7071 1.4142 4.9497 3.5355 4.2426 5.6569 3.5355 4.2426 6.3640 4.9497 3.5355 5.6569 4.9497 6.3640 2.2361 1.0000 1.4142 1.0000 1.4142 1.4142 3.1623 1.0000 2.8284 2.0000 ~ Mahalanobis D(P,Q) 1.3363 0.8018 1.4142 0.8018 1.4142 0.7559 2.0702 0.8018 1.5119 1.6036 Measuring Distance Mahalonobis distance can easily be generalized to p dimensions: d(P, Q) p a x i1 ii j-1 i p y i + 2 aij x i y i x j y j 2 i1 j 2 and all points satisfying p j-1 p 2 a x y + 2 a x y x y c ii i i ij i i j j i1 2 i1 j2 form a hyperellipsoid with centroid Q. Measuring Distance Now let’s backtrack – the Mahalonobis distance of a random p dimensional point P from the origin is given by d(0, P) p j-1 p 2 a x ii i + 2 aij x i x j i1 i1 j 2 so we can say p j-1 p d (0, P) aii x + 2 aij x i x j 2 i1 2 i i1 j2 provided that d2 > 0 x 0. Measuring Distance Recognizing that aij = aji, i j, i = 1,…,p, j = 1,…,p, we have 0<d2 (0, P) x1 x 2 for x 0. a11 a12 a21 a22 x p a a p1 p2 a1p x1 a2p x 2 x'Ax app x p Measuring Distance Thus, p x p symmetric matrix A is positive definite, i.e., distance is determined from a positive definite quadratic form x’Ax! We can also conclude from this result that a positive definite quadratic form can be interpreted as a squared distance! Finally, if the square of the distance from point x to the origin is given by x’Ax, then the square of the distance from point x to some arbitrary fixed point m is given by (x-m)’A (x-m). Measuring Distance Expressing distance as the square root of a positive definite quadratic form yields an interesting geometric interpretation based on the eigenvalues and eigenvectors of A. For example, in p = 2 two dimensions all points x x1 x 2 that are constant distance c from the origin must satisfy x ' Ax a11 x12 + 2a12 x1x 2 + a22 x 22 c Measuring Distance By the spectral decomposition we have k A l ieie l1e1e l 2 e 2 e ' i i1 ' 1 ' 2 so by substitution we now have ' ' x Ax l1 x e1 2 ' l 2 x e2 2 c2 and A is positive definite, so l1 > 0 and l2 >0, which means 2 ' c l1 x e1 is an ellipse. 2 ' l 2 x e2 2 Measuring Distance Finally, a little algebra can be used to show that x satisfies c l1 e1 2 c ' ' 2 x Ax l1 e1e1 c l1 Measuring Distance Similarly, a little algebra can be used to show that x satisfies c l2 e2 2 c ' ' 2 x Ax l 2 e2e2 c l2 Measuring Distance So the points at a distance c lie on an ellipse whose axes are given by the eigenvectors of A with lengths proportional to the reciprocals of the square roots of the corresponding eigenvalues (with constant of proportionality c) x c 2 e2 This generalizes to p dimensions l1 c l2 e1 x1 Square Root Matrices Because spectral decomposition allows us to express the inverse of a square matrix in terms of its eigenvalues and eigenvectors, it enables us to conveniently create a square root matrix. Let A be a p x p positive definite matrix with the spectral decomposition k A l ie ie i' i1 Square Root Matrices Also let P be a matrix whose columns are the normalized eigenvectors e1, e2, …, ep of A, i.e., Then P e 2 e p e2 k A l ie ie i' P ' P i1 where P’P = PP’ = I and l1 0 0 0 l2 0 0 0 0 l p Square Root Matrices Now since (P-1P’)PP’=PP’(P-1P’)=PP’=I we have 1 A P P eiei' i1 l i -1 Next let l1 1 2 0 0 1 ' 0 l2 0 k 0 0 lp Square Root Matrices The matrix 1 2 k P P ' l i eiei' A i1 is called the square root of A. 1 2 Square Root Matrices The square root of A has the following properties: A 1 2 1 2 ' 1 A 2 1 2 A A A -1 2 1 2 -1 2 -1 2 1 2 A A A A A A A 1 -1 2 I where A -1 2 A 1 2 -1 Square Root Matrices Next let -1 denote the matrix matrix whose columns are the normalized eigenvectors e1, e2, …, ep of A, i.e., Then P e 2 e p e2 k A l ie ie i' P ' P i1 where P’P = PP’ = I and l1 0 0 0 l2 0 0 0 0 l p Singular Value Decomposition We can extend the operations of spectral decomposition for a rectangular matrix by using the eigenvalues and eigenvectors from the square matrix A’A or (AA’). Suppose A is an m x k real matrix. There exists an m x m orthogonal matrix U and a k x k orthogonal matrix V such that singular values of A A = UV’ where has ith diagonal element li 0 for i = 1, 2,…, min (m,k) and 0 for all other elements. Singular Value Decomposition Singular Value decomposition can also be expressed as a matrix expansion that depends on the rank r of A. There exist r - positive constants l1, l2,…, lr, - orthogonal m x 1 unit vectors u1, u2, …, ur, - orthogonal k x 1 unit vectors v1, v2, …, vr, such that k A l iui v i' Ur r Vr' i1 Singular Value Decomposition k A l iui v Ur r V i1 ' i ' r where - Ur = [u1, u2, …, ur] - Vr = [v1, v2, …, vr] - is an r x r with diagonal entries l1, l2,…, lr and off diagonal entries 0 Singular Value Decomposition We can show that AA’ has eigenvalueeigenvector pairs (li, ui), so 2 i AA'ui l ui iui with li>0, i=1,...,r and li=0, i=r+1,...,m (for m>k) then 1 i v i l A'ui Singular Value Decomposition Alternatively, we can show that A’A has eigenvalue-eigenvector pairs (li, vi), so 2 i A'Av i l v i i v i with li>0, i=1,...,r and li=0, i=r+1,...,k (for k>m) then 1 i ui l Av i i Av i Singular Value Decomposition Suppose we have a rectangular matrix then 2 1 1 A 1 2 2 2 1 2 1 1 6 2 ' AA 1 2 1 2 2 1 2 2 9 Singular Value Decomposition and AA’ has eigenvalues of 1=5 and 2=10 with corresponding normalized eigenvectors 2 -1 5 , u 5 u1 2 1 2 5 5 Singular Value Decomposition Similarly for our rectangular matrix then 2 1 1 A 1 2 2 2 1 5 0 0 2 1 1 ' A A 1 2 0 5 5 1 2 1 2 2 0 5 5 Singular Value Decomposition and A’A also has eigenvalues of 1=0, 2=5 and 3=10 with corresponding normalized eigenvectors 0 0 1 v 1 1 , v 2 0 , v 3 1 2 2 0 1 -1 2 2 Singular Value Decomposition Now taking l1 = 1 = 0, l 2 = 2 = 5, l 3 = 3 = 10 we find that the singular value decomposition of A is 2 5 1 0 0 A 2 1 1 5 1 2 2 1 5 -1 5 1 10 0 2 2 5 1 2 Singular Value Decomposition The singular value decomposition is closely connected to the approximation of a rectangular matrix by a lower-dimension matrix [Eckart and Young, 1936]: First note that if a m x k matrix A is approximated by B of same dimension but lower rank, m k a i1 j1 ij - bij 2 ' = tr A - B A - B Singular Value Decomposition Eckart and Young used this fact to show that, for a m x k real matrix A with m k and singular value decomposition UV’, s B l iui v i1 ' i is the rank-s least squares approximation to A (where s < k = rank (A)). Singular Value Decomposition This matrix B minimizes m k a i1 j1 ij - bij 2 ' = tr A - B A - B over all m x k matrices of rank no greater than s! It can also be shown that the error of this approximation is k 2 l i i s 1 Random Vectors and Matrices Random Vector – vector whose individual elements are random variables Random Matrix – matrix whose individual elements are random variables Random Vectors and Matrices The expected value of a random vector or matrix is the matrix containing the expected values of the individual elements, i.e., E x11 E x12 E x E x 21 22 E X E x n1 E x n2 E x1p E x 2p E x np Random Vectors and Matrices where x ijpij x ij all x ij E x ij x ij fij x ij dx ij Random Vectors and Matrices Note that for random matrices X and Y of the same dimension, conformable matrices of constants A and B, and scalar c E(cX) = cE(X) E(X+Y) = E(X) + E(Y) E(AXB)= AE(X)B Random Vectors and Matrices Mean Vector – random vector whose elements are the means of the corresponding random variables, i.e., x ipi x i all x i E x i m i x i fi x i dx i Random Vectors and Matrices In matrix notation we can write the mean vector as E x1 m 1 E x 2 m 2 E X m E x mp p Random Vectors and Matrices For the bivariate probability distribution X1 X2 -4 1 3 p1(x 1) 1 2 0.15 0.10 0.20 0.25 0.05 0.25 0.40 0.60 p2(x 2) 0.25 0.45 0.30 1.00 the mean vector is x 1p1 x 1 E x 1 m all x 1 1 m E X E x 2 m 2 x 2p 2 x 2 all x 2 0.4(1) 0.6(2) 1.60 0.1(4) 0.25(1) 0.25(3) 0.35 Random Vectors and Matrices Covariance Matrix – random symmetric vector whose diagonal elements are variances of the corresponding random variables, i.e., 2 x i m i pi x i all x i 2 E x i mi i2 x m 2 f x dx i i i i i Random Vectors and Matrices and whose off-diagonal elements are covariances of the corresponding random variable pairs, i.e., x i mi x k mk pik x i , x k all x i all x k E x i mi x k mk ik x i mi x k mk fik x i , x k dx idx k notice that if we this expression, when i = k, returns the variance, i.e., ii 2 i Random Vectors and Matrices In matrix notation we can write the covariance matrix as x1 m1 x m ' 2 2 E X - m X - m E x 1 m1 x p m p x 2 m2 x m 2 E E x1 m1 x 2 m 2 1 1 x m 2 E x 2 m 2 x1 m1 E 2 2 E x m x m E x m x m p 1 1 p 2 2 p p x p mp E x 1 m1 x p m p 11 12 E x 2 m 2 x p m p 21 22 p1 p2 2 E x p mp 1p 2p pp Random Vectors and Matrices For the bivariate probability distribution we used earlier X1 X2 -4 1 3 p1(x 1) 1 2 0.15 0.10 0.20 0.25 0.05 0.25 0.40 0.60 p2(x 2) 0.25 0.45 0.30 1.00 the covariance matrix is x m 2 x1 m1 x 2 m 2 E E 1 1 ' E X - m X - m 2 E x 2 m 2 x1 m1 E x 2 m2 2 x m 1 1 p1 x1 all x1 x 2 m 2 x1 m1 p 21 x 2 , x1 all x 2 all x1 x all x1 all x 2 m1 x 2 m 2 p12 x 1 , x 2 12 11 2 22 21 x 2 m2 p2 x 2 all x 2 1 Random Vectors and Matrices which can be computed as 2 x m p1 x1 x1 m1 x 2 m2 p12 x1 , x 2 1 1 ' all x1 all x1 all x 2 E X - m X - m 2 x 2 m2 p2 x 2 x 2 m2 x1 m1 p21 x 2 , x1 all x 2 all x1 all x 2 1 1.6 4 0.35 0.15 1 1.6 1 0.35 0.2 2 2 1 1.6 3 0.35 0.05 2 1.6 4 0.35 0.1 1 1.6 0.4 2 1.6 0.6 2 1.6 1 0.35 0.25 2 1.6 3 0.35 0.25 4 0.35 1 1.6 0.15 4 0.35 2 1.6 0.1 2 2 2 4 0.35 0.25 1 0.35 0.45 3 0.35 0.3 1 0.35 1 1.6 0.2 1 0.35 2 1.6 0.25 3 0.35 1 1.6 0.05 3 0.35 2 1.6 0.25 0.24 0.39 11 12 0.39 7.0275 21 22 Random Vectors and Matrices Thus the population represented by the bivariate probability distribution X1 X2 -4 1 3 p1(x 1) 1 2 0.15 0.10 0.20 0.25 0.05 0.25 0.40 0.60 p2(x 2) 0.25 0.45 0.30 1.00 Have population mean vector and variance-covariance matrix 1.60 m and 0.35 0.24 0.39 0.39 7.0275 Random Vectors and Matrices We can use the population variancecovariance matrix S to calculate the population correlation matrix r. Individual population correlation coefficients are defined as rik ik ii kk Random Vectors and Matrices In matrix notation we can write the correlation matrix as 11 11 11 21 r 22 11 p1 pp 11 12 11 22 22 22 22 p2 pp 22 1p 11 pp r11 r12 2p r rik ik 22 pp rp1 rp2 pp pp pp r1p r2p rpp Random Vectors and Matrices We can easily show that V1 2rV1 2 where V 12 11 0 0 which implies r V 12 0 0 pp 0 22 0 V 12 Random Vectors and Matrices For the bivariate probability distribution we used earlier X1 X2 -4 1 3 p1(x 1) 1 2 0.15 0.10 0.20 0.25 0.05 0.25 0.40 0.60 p2(x 2) 0.25 0.45 0.30 1.00 the variance matrix is V 12 11 0 0 0.24 22 0 0.48989 0 0 2.65094 7.0275 0 Random Vectors and Matrices so the population correlation matrix is r V 12 V 12 2.04124 0 0.24 0.39 2.04124 0 0 0.37739 0.39 7.0275 0 0.37739 1.00 0.30 0.30 1.00 Random Vectors and Matrices We often deal with variables that naturally fall into groups. In the simplest case, we have two groups of size q and p – q of variables. Under such circumstances, it may be convenient to partition the matrices and vectors. Random Vectors and Matrices Here we have a mean vector and variance-covariance matrix: 11 m1 q1 mq m m ___ ___ , m q1 q1,1 m m p1 p 1p 1,q1 qq q,q1 q1,q q1,q1 pq p,q1 1p qp 11 q1,p 21 pp 12 22 Random Vectors and Matrices Rules for Mean Vectors and Covariance Matrices for Linear Combinations of Random Variables: The linear combination of real constants c and random variables X x1 c'X c1 c2 has mean vector p x 2 c p c j X j j1 x p E c'X c'E X c'm Random Vectors and Matrices The linear combination of real constants c and random variables X c'X c1 c2 x1 p x 2 c p c j X j j1 x p also has variance Var c'X c' c Random Vectors and Matrices Suppose, for example, we have random vector X1 X= X2 and we want to find the mean vector and covariance matrix for the linear combinations: Z1 = X1 - X 2 , Z 2 = X1 + X 2 Z1 1 1 X1 i.e., Z= CX Z 2 1 1 X 2 Random Vectors and Matrices We have mean vector 1 1 m1 m1 m 2 m Z = E Z = Cm X 1 1 m2 m1 m2 and covariance matrix Note what happens if 11=22 – the off diagonal terms vanish (i.e., the sum and difference of two random variables with identical variances are uncorrelated) 1 1 11 12 Z = Cov Z = C X C 1 1 21 22 11 212 22 11 22 2 11 22 11 12 22 ' Matrix Inequalities and Maximization These results will be useful in later applications: - Cauchy-Schwartz Inequality – Let b and d be any two p x 1 vectors. Then (b’d)2 (b’b)(d’d) with equality iff b=cd or (or d=cb) for some constant c. Matrix Inequalities and Maximization - Extended Cauchy-Schwartz Inequality – Let b and d be any two p x 1 vectors and B be a p x p positive definite matrix. Then (b’d)2 (b’Bb)(d’B-1d) with equality iff b=cB-1d or (or d=cB -1d) for some constant c. Matrix Inequalities and Maximization - Maximization Lemma – let d be a given p x 1 vector and B be a p x p positive definite matrix. Then for an arbitrary nonzero vector x max x 0 x ' d 2 x ' Bx d ' B 1d with the maximum attained when x = cB-1d for any constant c. Matrix Inequalities and Maximization - Maximization of Quadratic Forms for Points on the Unit Sphere – let B be a p x p positive definite matrix with eigenvalues l1 l2 lp and associated eigenvectors e1, e2, ,ep. Then x ' Bx l1 (attained when x=e1 ) max x 0 x'x x ' Bx l p (attained when x=e p ) min x 0 x ' x Matrix Inequalities and Maximization and x ' Bx l k+1 (attained when x ek+1 , k 1,2, max x e1 , ek x ' x ,p-1) Summary There are MANY other Matrix Algebra results that will be important to our study of statistical modeling. This site will be updated occasionally to reflect these results as they become necessary.