Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Lecture 10
Disjoint Set ADT
Preliminary Definitions
A set is a collection of objects.
Set A is a subset of set B if all elements of A are in B.
Subsets are sets
Union of two sets A and B is a set C which consists of all
elements in A and B
Two sets are mutually disjoint if they do not have a
common element.
A partition of a set is a collection of subsets such that
Union of all these subsets is the set itself
Any two subsets are mutually disjoint
S = {1,2,3,4}, A = {1,2}, B = {3,4}, C = {2,3,4}, D = {4}
Is A, B a partition of S?
Yes
Is A, C partition of S?
No
Is A, D partition of S?
No
Union and Find Operations
Operations on partitions.
Union
Need to form union of two different sets of a partition
Find
Need to find out which set an element belongs to
Every set in the partition has a number.
The numbers can be anything as long as different sets have
distinct numbers.
Find(a) returns the number of the set containing a.
Can two different sets contain the same element?
No, the sets in a partition are disjoint
Disjoint Set Data Structure
Every element has a number.
Elements of a set are stored in a tree (not necessarily binary)
The set is represented by the root of the tree.
The number assigned to a set is the number of the
root element.
B = {3, 4}
3
4
B is assigned number 3
Are the numbers distinct for different sets?
No two sets have the same root as they are disjoint,
thus they have distinct numbers
Find(a) returns the number of the root node of the
tree containing a.
B = {3, 4}
Find(4) returns?
3
Find(3) returns?
3
3
4
Union operation makes one tree sub-tree of another
Root of one tree becomes child of the root of another.
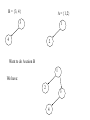
B = {3, 4}
A = {1,2}
3
1
4
2
Want to do A union B
1
We have:
2
3
4
Tree Representation
Will use an array based representation, array S
Let the elements be 1,2,….N
S[j] contains the number for the parent of j
S[j] = 0 if j is the root.
Initially all trees are singletons
Trees build up with unions.
Note that we don’t use any pointers here.
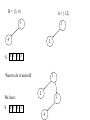
B = {3, 4}
A = {1,2}
3
1
4
2
S 0 1 0 3
Want to do A union B
We have:
S
1
2
3
0 1 1 3
4
Pseudo Code for Find
Find(a) {
If S[a] = 0, return a;
else Find(S[a]);
return;
}
Complexity?
O(N)
Pseudo-Code for Union
Union(root 1, root 2)
{
S[root2] = root1;
}
Complexity?
O(1)
More Efficient Union
Will improve the worst case find complexity to log N
When we do a union operation make the smaller tree a
subtree of the bigger one
Thus the root of the smaller subtree becomes a child
of the root of the bigger one.
A = {1,2,3} B = {4}
Root of B is root of A after union, B is subtree of A
Alternatively, union operation can be done by height as well
Tree of lesser height is made subtree of the other.
We consider only size here.
Array storage changes somewhat.
If j is a root, S[j] = - size of tree rooted at j
If j is not a root, S[j] = parent of j
Why is S[j] not equal to the size of tree j, if j is a root?
Size of tree j is an integer, if S[j]=size of tree j and
j is root, then it would look like root of j is another
element, thus j is not root
Initially, what is the content of array S?
All elements are -1
Pseudo-Code for Union
Union(root 1, root 2)
{
If S[root2] < S[root1], S[root1] = root2;
else S[root2]=root1;
}
Complexity?
O(1)
Pseudo Code for Find
Find(a) {
If S[a] < 0, return a;
else Find(S[a]);
return;
}
Complexity Analysis for Find
Operation
If the depth (distance from root) of a node A increases,
then the earlier tree consisting the node A becomes a
subtree of another.
Since only a smaller tree becomes a subtree of another,
total size of the combined tree must be at least twice
the previous one consisting A.
Each time depth of a node increases, the size of the
tree increases by at least a factor of 2.
At first every node has depth 0
Next time depth is 1, tree size is at least 2,
depth is 2, tree size is at least 4…
depth is k, tree size is at least 2k
We know that 2k <= N
Thus k <= log N
Depth of any tree is at most log N
Complexity of Find operation is O(log N)
Complexity of any M operations is O(MlogN)
Path Compression
Makes all operations almost linear in the worst case.
Whenever you do Find(j) make S[k]=Find(j) for all elements
on the path of j to the root, except the root.
All nodes on the path of j now point to the root directly
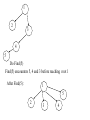
1
2
3
4
5
Do Find(5)
Find(5) encounters 5, 4 and 3 before reaching root 1
After Find(5):
1
5
2
3
4
Later Find operations will have lower costs as their depths have
been reduced.
Any Find operation reduces the cost of future ones.
Pseudo Code for New Find
Find(a) {
If S[a] < 0, return a;
else S[a]=Find(S[a]);
return;
}
Complexity Analysis
Any M operations take O(Mlog*N) if M is (N)
log*N is the number of times we take loglog….logN so as to
get a number less than or equal to 1 (log base 2, even
otherwise asymptotic order remains the same).
log*N grows very slowly with N and is less
than 4 or 5 for all practical values of N,
log*232 is less than 5
Thus the worst case complexity is linear for all practical
purposes.
Reading Assignment
Chapter 8, till section 8.61. (i.e. section 8.6.1
onwards can be omitted).