Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Copland (operating system) wikipedia , lookup
Plan 9 from Bell Labs wikipedia , lookup
Spring (operating system) wikipedia , lookup
Unix security wikipedia , lookup
Burroughs MCP wikipedia , lookup
Security-focused operating system wikipedia , lookup
Process management (computing) wikipedia , lookup
Advanced
Operating Systems
Lecture 4: Process
University of Tehran
Dept. of EE and Computer Engineering
By:
Dr. Nasser Yazdani
Univ. of Tehran
Distributed Operating Systems
1
Topic
How OS handle processes
References
“Cooperative Task Management Without Manual
Stack Management”, by Atul Adya, et.al.
“Capriccio: Scalable Threads for Internet
Services”, by Ron Von Behrn, et. al.
“The Performance Implication of Thread
Management Alternative for Shared-Memory
Multiprocessors”, Thomas E. Anderson, et.al.
Univ. of Tehran
Distributed Operating Systems
2
Outline
Introduction
Processes
Process operations
Threads
What are bad about Threads?
Different Thread issues.
Univ. of Tehran
Distributed Operating Systems
3
Processes
Users want to run programs on computers
OS considers a running program as a Process?
It is an abstraction
OS needs mechanisms to start, manipulate,
suspend, scheduled and terminated processes
Process Types:
OS should provide facilities!
OS processes executing system code
User processes executing user code
Processes are executed concurrently with CPU
multiplexed
amongDistributed
themOperating Systems
Univ. of Tehran
4
So What Is A Process?
It’s one executing instance of a
“program”
It’s separate from other instances
It can start (“launch”) other processes
It can be launched by them
Univ. of Tehran
Distributed Operating Systems
5
Processes Issues
How to create, suspend and terminate
processes?
What information we need to keep for each
process?
How to select a process to run?
(multiprogramming)
How switch among processes?
How isolate, protect process from each
others?
Univ. of Tehran
Distributed Operating Systems
6
Process Creation
By system or user through command line see
clone(), fork(), vfork()
int parentpid;
int childpid;
if ((childpid = fork()) == -1) {
perror(can’t create a new process);
exit(1);
}
else if (childpid == 0) {/* child process executes */
printf(“child: childpid = %d, parentpid = %d \n”, getpid(), getppid());
exit(0);
}
else { /*parent process executes */
printf(“parent: childpid = %d, parentpid = %d \n”, childpid, getpid());
exit(0);
}
Univ. of Tehran
Distributed Operating Systems
7
Process Creation (What
we need?)
We need resources such as CPU, memory files, I/O
devices
Get resources from a parent
When creating a new process , execution
possibilities are
Parent continues concurrently with child
Parent waits until child has terminated
When creating a new process, address space
possibilities are:
Prevents many processes from overloading system
Child process is duplicate of parent process
Child process had a program loaded into it
What
other information
OS needs? (comes later)
Univ. of Tehran
Distributed Operating Systems
8
Process Termination
Normal exit, end of program (voluntary)
Ask OS to delete it, deallocate resources
Error exit (voluntary) (exit(2)) or Fatal error
(involuntary)
Killed by another process (involuntary)
Child process may return output to parent process,
and all child’s resources are de-allocated.
Other termination possibilities
Abort by parent process invoked
Child has exceeded its usage of some resources
Task assigned to child is no longer required
Parent is exiting and OS does not allow child to continue without
parent
Univ. of Tehran
Distributed Operating Systems
9
What information OS need?
Memory Management Information
Process State
process priority and pointer;
Accounting Information
index registers, stack pointers, general purpose registers;
CPU Scheduling Information
the address of the next instruction to be executed for this process;
CPU Registers
new, ready, running, waiting, halted;
Program Counter
base/limit information;
time limits, process number; owner
I/O Status Information
list of I/O devices allocated to the process;
Univ. of Tehran
Distributed Operating Systems
10
Process States
Possible process states
Running (occupy CPU)
Blocked
Ready (does not occupy CPU)
Other states: suspended, terminated
Transitions between states
Question: in a single processor machine, how
Univ. of Tehran
Distributed Operating Systems
many
processes can
be in running state?
11
Process Hierarchies
Parent creates a child process, a child
process can create its own processes
Forms a hierarchy
UNIX calls this a "process group"
Windows has no concept of process
hierarchy
all processes are created equal
Univ. of Tehran
Distributed Operating Systems
12
The Process Model
Multiprogramming of four programs
Conceptual model of 4 independent, sequential
processes
Only one program active at any instant
Real life analogy?
Univ. of Tehran
Distributed Operating Systems
A daycare teacher of
4 infants
13
Instances Of Programs
The address was always the same
The values were different
Implies that the programs aren’t seeing each
other
But they think they’re using the same address
Conclusion: addresses are not absolute
Implication: memory mapping
What’s the benefit?
Univ. of Tehran
Distributed Operating Systems
14
Remember This?
Application
Libraries
User space/level
Kernel space/level
Portable OS Layer
Machine-dependent layer
Univ. of Tehran
Distributed Operating Systems
15
Address Space
Program segments
Text
Data
Stack
Heap
0xffff….
Kernel space
Stack
Lots of flexibility
Allows stack growth
Allows heap growth
No predetermined division
Univ. of Tehran
Distributed Operating Systems
Heap
Code & Data
0x0000…
16
Process Control Block
(PCB)
Fields of a process table entry
Univ. of Tehran
Distributed Operating Systems
17
Process Scheduling
Objective of multiprogramming – maximal
CPU utilization, i.e., have always a
process running
Objective of time-sharing – switch CPU
among processes frequently enough so
that users can interact with a program
which is running
Need Context Switching
Univ. of Tehran
Distributed Operating Systems
18
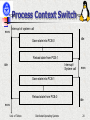
Context Switch
Switch CPU from one process to another
Performed by scheduler
Context switch is expensive(1-1000 microseconds)
save PCB state of the old process;
load PCB state of the new process;
Flush memory cache;
Change memory mapping (TLB);
No useful work is done (pure overhead)
Can become a bottleneck
Real life analogy?
Need hardware support
Univ. of Tehran
Distributed Operating Systems
19
Process Context SwitchPCB-1
PCB-0
exec
Interrupt of system call
idle
Save state into PCB-0
Reload state from PCB-1
Interrupt/
System call
idle
exec
Save state into PCB-1
Reload state from PCB-0
idle
exec
Univ. of Tehran
Distributed Operating Systems
20
Interrupt Processing
Illusion of multiple sequential processes with one CPU
and many I/O devices maintained?
Each I/O device class is associated with location, called
interrupt vector which includes
Address of interrupt service procedure
When interrupt occurs:
Save registers into process table entry for the current process
(assembly)
Info pushed onto the stack by the interrupt is removed and the
stack pointer is set to point to a temporary stack used by
process handler (assembly)
Call interrupt service (e.g., to read and buffer input), process is
done (C-language)
Scheduler decides which other process to run next (C-language)
Start to run assembly code to load registers, etc. (assembly)
Univ. of Tehran
Distributed Operating Systems
21
Process Descriptor
Process – dynamic, program in motion
Type of info in task_struct
Kernel data structures to maintain "state"
Descriptor, PCB (control block), task_struct
Larger than you think! (about 1K)
Complex struct with pointers to others
Registers, state, id, priorities, locks, files, signals,
memory maps, locks, queues, list pointers, …
Some details
Address of first few fields hard coded in asm
Careful attention to cache line layout
Univ. of Tehran
Distributed Operating Systems
22
Process State
Traditional (textbook) view
Blocked, runnable, running
Also initializing, terminating
UNIX adds "stopped" (signals, ptrace())
Linux (TASK_whatever)
Running, runnable (RUNNING)
Blocked (INTERRUPTIBLE, UNINTERRUPTIBLE)
Terminating (ZOMBIE)
Interruptible – signals bring you out of syscall block
(EINTR)
Dead but still around – "living dead" processes
Stopped (STOPPED)
Univ. of Tehran
Distributed Operating Systems
23
Process Identity
Users: pid; Kernel: address of descriptor
Pids dynamically allocated, reused
Pid to address hash
2.2: static task_array
16 bits – 32767, avoid immediate reuse
Statically limited # tasks
This limitation removed in 2.4
current->pid (macro)
Univ. of Tehran
Distributed Operating Systems
24
Descriptor
Storage/Allocation
Descriptors stored in kernel data segment
Each process gets a 2 page (8K) "kernel
stack" used while in the kernel (security)
task_struct stored here; rest for stack
Easy to derive descriptor from esp (stack ptr)
Implemented as union task_union { }
Small (16) cache of free task_unions
free_task_struct(), alloc_task_struct()
Univ. of Tehran
Distributed Operating Systems
25
Descriptor Lists, Hashes
Process list
init_task, prev_task, next_task
for_each_task(p) iterator (macro)
Runnable processes: runqueue
init_task, prev_run, next_run, nr_running
wake_up_process()
Calls schedule() if "preemption" is necessary
Pid to descriptor hash: pidhash
hash_pid(), unhash_pid()
find_hash_by_pid()
Univ. of Tehran
Distributed Operating Systems
26
Wait Queues
Blocking implementation
Change state to TASK_(UN)INTERRUPTIBLE
Add node to wait queue
All processes waiting for specific "event"
Usually just one element
Used for timing, synch, device i/o, etc.
Structure is a bit optimized
struct wait_queue usually allocated on kernel
stack
Univ. of Tehran
Distributed Operating Systems
27
sleep_on(), wake_up()
sleep_on(), sleep_on_interruptible()
See code on LXR
wake_up(), wake_up_interruptible()
See code on LXR
Process can wakeup with event not true
If multiple waiters, another may have resource
Always check availability after wakeup
Maybe wakeup was in response to signal
2.4: wake_one()
Avoids "thundering herd" problem
A lot of waiting processes wake up, fight over resource; most
then go back to sleep (losers)
Bad for performance; very bad for bus, cache on SMP machine
Univ. of Tehran
Distributed Operating Systems
28
Process Limits
Optional resource limits (accounting)
getrlimit(), setrlimit() (user control)
Root can establish rlim_min, rlim_max
Usually RLIMIT_INFINITY
Resources (RLIMIT_whatever)
CPU, FSIZE (file size), DATA (heap), STACK,
CORE, RSS (frames), NPROC (# processes),
NOFILE (# open files), MEMLOCK, AS
Univ. of Tehran
Distributed Operating Systems
29
Process Switching Context
Hardware context
Registers (including page table register)
Hardware support but Linux uses software
About the same speed currently
Software might be optimized more
Better control over validity checking
prev, next task_struct pointers
Linux TSS (thread_struct)
Base registers, floating-point, debug, etc.
I/O permissions bitmap
Intel feature to allow userland access to i/o ports!
ioperm(), iopl() (Intel-specific)
Univ. of Tehran
Distributed Operating Systems
30
Process Switching –
switch_to()
Invoked by schedule()
Very Intel-specific (mostly assembly code)
GCC magic makes for tough reading
Some highlights
Save basic registers
Switch to kernel stack of next
Save fp registers if necessary
Unlock TSS
Load ldtr, cr3 (paging)
Load debug registers (breakpoints)
Return
Univ. of Tehran
Distributed Operating Systems
31
Process Switching – FP
Registers
This is pretty weird
Pentium – on chip FPU
FP registers
Backwards compatibility, ESCAPE prefix
Not saved by default
MMX Instructions use FPU
Saved "on demand", reload "when needed" (lazily)
TS Flag set on context switch
FP instructions cause exception (device unavailable)
Kernel intervenes by loading FP regs, clearing TS
unlazy_fpu(), math_state_retstore()
Univ. of Tehran
Distributed Operating Systems
32
What are wrong with
Process?
Processes do not share resources very well, therefore
context switching cost is very high.
Process creation and deletion are expensive.
Context switching is a real bottleneck in realtime and
interactive systems.
Solutions?
Theard!.
The idea: Do not change the address space only the stack and
control block.
Extensive sharing makes CPU switching among peer threads
and creation of threads inexpensive compared to processes
Thread context switch still requires
Register set switch
But no memory management related work
Univ. of Tehran
Distributed Operating Systems
33
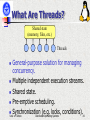
What Are Threads?
Shared state
(memory, files, etc.)
Threads
General-purpose solution for managing
concurrency.
Multiple independent execution streams.
Shared state.
Pre-emptive scheduling.
Synchronization (e.g. locks, conditions).
Univ. of Tehran
Distributed Operating Systems
34
Threads
‘threads’ share some of the resources
Thread comprises
Thread is a light-weighted process and it is the basic
unit of CPU utilization.
Thread ID
Program counter
Register set
Stack space
Thread shares
Code section
Data section
OS resources such as open files, signals belonging to the
task
Univ. of Tehran
Distributed Operating Systems
35
Threads
System
Light-weighted threads switch between
threads but not between virtual memories
Threads allow user programs to continue
after starting I/O
Threads allow parallel processing
User
Threads may reduce context switching times
by eliminating kernel overhead
Thread management allows user scheduling
of threads Distributed Operating Systems
Univ. of Tehran
36
Threads: Lightweight
Processes
Environment (resource)
execution
(a) Three processes each with one thread
(b) One process with three threads
Univ. of Tehran
Distributed Operating Systems
37
Thread Model
Threads in the same process share
resources
Each thread execute separately
Univ. of Tehran
Distributed Operating Systems
38
Thread Model: Stack
Univ. of Tehran
Distributed Operating Systems
39
Thread Model: State
Threads states are Ready, Blocked, Running
and Terminated
Threads share CPU and on single processor
machine only one thread can run at a time
Thread management can create child threads
which can block waiting for a system call to
be completed
No protection among threads!!
Univ. of Tehran
Distributed Operating Systems
40
A example program
#include ``csapp.h''
void *thread(void *vargp);
int main() {
phtread_t tid; // stores the new thread ID
Pthread_create(&tid, NULL, thread, NULL); //create a new thread
Pthread_join(tid, NULL); //main thread waits for the other thread to
terminate
exit(0); /* main thread exits */
}
void *thread(void *vargp) /*thread routing*/
{
printf(``Hello, world! \n'');
return NULL;
}
Univ. of Tehran
Distributed Operating Systems
41
Thread Usage: Web Server
Univ. of Tehran
Distributed Operating Systems
42
Web Server
Rough outline of code for previous slide
(a) Dispatcher thread
(b) Worker thread
Univ. of Tehran
Distributed Operating Systems
43
Blocking Vs. non-blocking
System Calls
Blocking system call
Usually I/O related: read(), fread(), getc(), write()
Doesn’t return until the call completes
The process/thread is switched to blocked state
When the I/O completes, the process/thread becomes ready
Simple
Real life example: attending a lecture
Using non-blocking system call for I/O
Asynchronous I/O
Complicated
The call returns once the I/O is initiated, and the caller
continue
Once the I/O completes, an interrupt is delivered to the
caller
Real
life
example: apply
forOperating
job Systems
Univ. of
Tehran
Distributed
44
Benefits of Threads
Responsiveness
Resource sharing
Sharing of memory, files and other resources of
the process to which the threads belong
Economy
Multi-threading allows applications to run even if
part of it is blocked
Much more costly and time consuming to create
and manage processes than threads
Utilization of multiprocessor architectures
Each thread can run in parallel on a different
Univ. of Tehran
Distributed Operating Systems
processor
45
Implementing Threads in User
Space (old Linux)
A user-level threads package
Univ. of Tehran
Distributed Operating Systems
46
User-level Threads
Advantages
Fast Context Switching:
User level threads are implemented using user level thread
libraries, rather than system calls, hence no call to OS and no
interrupts to kernel
One key difference with processes: when a thread is finished
running for the moment, it can call thread_yield. This
instruction (a) saves the thread information in the thread table
itself, and (b) calls the thread scheduler to pick another thread to
run.
The procedure that saves the local thread state and the scheduler
are local procedures, hence no trap to kernel, no context switch,
no memory switch, and this makes the thread scheduling very
fast.
Customized Scheduling
Univ. of Tehran
Distributed Operating Systems
47
User level Threads
Disadvantages
Blocking
If kernel is single threaded, then any user-level
thread can block the entire task executing a
single system call
No Protection
There is no protection between threads, since the
threads share memory space
Univ. of Tehran
Distributed Operating Systems
48
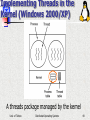
Implementing Threads in the
Kernel (Windows 2000/XP)
A threads package managed by the kernel
Univ. of Tehran
Distributed Operating Systems
49
Hybrid Implementations
(Solaris)
Multiplexing user-level threads onto
kernel- level threads
Univ. of Tehran
Distributed Operating Systems
50
Kernel Threads (Linux)
Kernel threads differ from regular
processes:
Each kernel thread executes a single specific
kernel C function
Kernel threads run only in Kernel Mode
Regular process executes kernel function only
through system calls
Regular processes run alternatively in kernel
mode and user mode
Kernel threads use smaller linear address
space than regular processes
Univ. of Tehran
Distributed Operating Systems
51
Pop-Up Threads
Creation of a new thread when message arrives
before message arrives
after message arrives
Univ. of Tehran
Distributed Operating Systems
52
Multi-threading Models
Many-to-One Model – many user threads are mapped to
one kernel thread
Advantage:
Disadvantage:
thread management is done in user space, so it is efficient
Entire process will block if a thread makes a blocking call to the kernel
Because only one thread can access kernel at a time, no parallelism on
multiprocessors is possible
One-to-One Model – one user thread maps to kernel
thread
Advantage:
more concurrency than in many-to-one model
Multiple threads can run in parallel on multi-processors
Disadvantage:
Creating a user thread requires creating the corresponding kernel
thread. There is an overhead related with creating kernel thread which
can be burden on theDistributed
performance.
Univ. of Tehran
Operating Systems
53
Multi-threading Models
Many-to-Many Model – many user
threads are multiplexed onto a smaller
or equal set of kernel threads.
Advantage:
Application can create as many user threads as
wanted
Kernel threads run in parallel on
multiprocessors
When a thread blocks, another thread can still
run
Univ. of Tehran
Distributed Operating Systems
54
A Challenge: Making Single-Threaded Code
Multithreaded
Conflicts between threads over the use of a global
variable
Univ. of Tehran
Distributed Operating Systems
55
A solution: Private Global Variables
Univ. of Tehran
Distributed Operating Systems
56
Cons and Pros of Threads
Grew up in OS world (processes).
Evolved into user-level tool.
Proposed as solution for a variety of problems.
Every programmer should be a threads
programmer?
Problem: threads are very hard to program.
Alternative: events.
Claims:
For most purposes proposed for threads, events are
better.
Threads should be used only when true CPU
Univ. of Tehran
Distributed Operating Systems
concurrency is needed.
57
What's Wrong With
Threads?
casual
wizards
all programmers
Visual Basic programmers
C programmers
C++ programmers
Threads programmers
Too hard for most programmers to use.
Even for experts, development is painful.
Univ. of Tehran
Distributed Operating Systems
58
Why Threads Are Hard
Synchronization:
Must coordinate access to shared data with
locks.
Forget a lock? Corrupted data.
Deadlock:
Circular dependencies among locks.
Each process waits for some other process:
system hangs.
thread 1
Univ. of Tehran
lock A
lock B
Distributed Operating Systems
thread 2
59
Why Threads Are Hard,
cont'd
Hard to debug: data dependencies,
timing dependencies.
Threads break abstraction: can't
design modules independently.
Callbacks don't work with locks.
T1
T2
deadlock!
Module A
T1
calls
Module A
deadlock!
Module B
Module B
callbacks
sleep
Univ. of Tehran
wakeup
Distributed Operating Systems
T2
60
Why Threads Are Hard,
cont'd
Achieving good performance is hard:
Threads not well supported:
Simple locking (e.g. monitors) yields low concurrency.
Fine-grain locking increases complexity, reduces
performance in normal case.
OSes limit performance (scheduling, context switches).
Hard to port threaded code (PCs? Macs?).
Standard libraries not thread-safe.
Kernel calls, window systems not multi-threaded.
Few debugging tools (LockLint, debuggers?).
Often don't want concurrency anyway (e.g. window
events).
Univ. of Tehran
Distributed Operating Systems
61
Event-Driven Programming
One execution stream: no
CPU concurrency.
Event
Register interest in events
Loop
(callbacks).
Event loop waits for events,
invokes handlers.
Event Handlers
No preemption of event
handlers.
Handlers generally shortlived.
Univ. of Tehran
Distributed Operating Systems
62
What Are Events Used
For?
Mostly GUIs:
One handler for each event (press button,
invoke menu entry, etc.).
Handler implements behavior (undo, delete file,
etc.).
Distributed systems:
One handler for each source of input (socket,
etc.).
Handler processes incoming request, sends
response.
of Tehran
Operating
Systems
Univ.
Event-driven
I/ODistributed
for I/O
overlap.
63
Problems With Events
Long-running handlers make application nonresponsive.
Fork off subprocesses for long-running things (e.g.
multimedia), use events to find out when done.
Break up handlers (e.g. event-driven I/O).
Periodically call event loop in handler (reentrancy adds
complexity).
Can't maintain local state across events (handler
must return).
No CPU concurrency (not suitable for scientific apps).
Event-driven I/O not always well supported (e.g.
poorUniv.write
buffering).
of Tehran
Distributed Operating Systems
64
Events vs. Threads
Events avoid concurrency as much as possible,
threads embrace:
Easy to get started with events: no concurrency, no
preemption, no synchronization, no deadlock.
Use complicated techniques only for unusual cases.
With threads, even the simplest application faces the full
complexity.
Debugging easier with events:
Timing dependencies only related to events, not to
internal scheduling.
Problems easier to track down: slow response to button
vs. corrupted memory.
Univ. of Tehran
Distributed Operating Systems
65
Events vs. Threads, cont'd
Events faster than threads on single CPU:
No locking overheads.
No context switching.
Events more portable than threads.
Threads provide true concurrency:
Can have long-running stateful handlers without
freezes.
Scalable performance on multiple CPUs.
Univ. of Tehran
Distributed Operating Systems
66
Should You Abandon
Threads?
No: important for high-end servers (e.g.
DBS).
But, avoid threads wherever possible:
Use events, not threads, for GUIs, Event-Driven Handlers
distributed systems, low-end servers.
Only use threads where true CPU
Threaded Kernel
concurrency is needed.
Where threads needed, isolate usage
in threaded application kernel: keep
most of code single-threaded.
Univ. of Tehran
Distributed Operating Systems
67
Capriccio: Threads for
internet services
Choose threads instead of event
Implement user level thread and apply it to
Apache server
Solutions for high concurrency services
Scalable, up to 105 concurrent threads.
Efficient stack management
Resource aware scheduling
Thread is a better model for concurrency
programming
Univ. of Tehran
Distributed Operating Systems
68
Capriccio: Events
Events based systems handle requests using
a pipeline of stages.
It allows:
Precise control over batch processing
State management
Admission control
Atomicity
Event drawbacks
Hide control flow
Manual stack management,
Univ. of Tehran
Distributed Operating Systems
69
Capriccio: Threads
Kernel thread: good for true concurrency
User thread: clean programming model
Active research area.
Separate for kernel, less overhead
Performance
Flexibility
Disadv. Of user level thread:
Complicated preemption
Badly interact with kernel schedular
Univ. of Tehran
Distributed Operating Systems
70
Capriccio: Threads
solution
Idea:
Decouple application from kernel
Very light overhead
Kernel level thread are more general
Low overhead for thread sync (no interupts)
No kernel crossing for lock and mutex
Efficient memory and stack management
Problem:
Blocking I/O
Not good for multiprocessor- High sync cost
Univ. of Tehran
Distributed Operating Systems
71
Capriccio: blocking
solution
Override it with non-blocking equivalence
Use epoll to implement async I/O
Scheduling like event driven.
Univ. of Tehran
Distributed Operating Systems
72
Capriccio: Stack
management
Linux allocate 2MB for thread (not scalable)
Most thread consume few KB
Solutions: allocate dynamically and on
demand
Compiler does this by inserting checkpoints
which determine if we can reach the next
checkpoint without stack overflow
Create call graph
Univ. of Tehran
Distributed Operating Systems
73
Capriccio: Scheduling
Application are sequence of stage
separated by blocking points
The same idea of event based scheduling
Solution: use blocking graph. Blocking
points are vertices and there is an edge
between them if there are consecutive
blocking point.
For scheduling: keep weighted average for
each node in the graph.
Univ. of Tehran
Distributed Operating Systems
74
Capriccio: Scheduling (2)
Keep track of resource utilization level and
its limits
Annotate each node with resource used on
its outgoing edges to predict which thread
we need to schedule from the node.
Dynamically prioritize node or threads for
scheduling
Univ. of Tehran
Distributed Operating Systems
75
Next Lecture
Interprocess communication
References
“improving IPC by Kernel Design”, by Jochen
Liedtke.
Univ. of Tehran
Distributed Operating Systems
76