Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
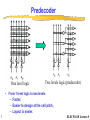
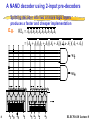
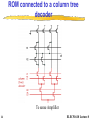
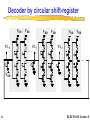
ELEC 516 VLSI System Design and Design Automation Spring 2010 Lecture 8 - Memory Periphery Design Reading Assignment: Chapter 10 of Rabaey Chapter 8.3 of Weste Note: some of the figures in this slide set are adapted from the slide set of “ Digital Integrated Circuits” by Rabaey, Copyright UCB 2002 1 ELEC516/10 Lecture 8 Why peripheral circuitry? • To achieve high very high density memories, area is of premier importance. • If compared to FF & latches, the memory cells trades performance and reliability for reduced area. • Memory design relies on the peripheral circuitry to recover both speed and electrical integrity. • A good designer can make an important difference when designing reliably the peripheral circuitry. • Peripheral circuitry includes: Address decoders, IO drivers/buffers, sensing amplifiers, and memory timing and control. 2 ELEC516/10 Lecture 8 Architecture of a memory • Good example of mixed analog-digital system design • In addition to the decoders, and sensing amplifiers, control circuitry is required for timing, multiplexing etc… • Memory also require some analog building blocks such as voltage regulator circuit, charge pump, etc… 3 ELEC516/10 Lecture 8 Periphery • Address Decoders – row address - row decoder to enable one memory row out of 2M row – column address - column decoder: a 2K -input multiplexers – When designing the address decoder, it is important to keep the global memory in perspective. The decoder’s dimension has to be matched with that of the core memory cell (pitch matching). Failing to do so leads to a dramatic wiring overhead with its associated delay and power dissipation. • Sense Amplifiers • Input/Output Buffers • Control / Timing Circuitry 4 ELEC516/10 Lecture 8 Row Decoders • Collection of 2M complex logic gates • Organized in regular and dense fashion • Each row address is enabled by a signal WL which is a logic function of the input address signal. (E.g. for 10 address signal) WL0 A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 (( n)and _ decoder ) A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 (( n)or _ decoder ) WL511 A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 (( n)and _ decoder ) A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 (( n)or _ decoder ) 5 ELEC516/10 Lecture 8 Row Decoders (II) • First method - using standard gate implementation •Useful for up to 5-6 inputs, otherwise the speed will be too slow. •Often, speed requirements or size restrict the use of singlelevel decoding. The alternative is a predecoding scheme. 6 ELEC516/10 Lecture 8 Predecoder One level logic Two levels logic (predecoder) • From 1 level logic to two levels – Faster, – Easier to design at the cell pitch, – Layout is easier. 7 ELEC516/10 Lecture 8 A NAND decoder using 2-input pre-decoders Splitting decoder into two or more logic layers produces a faster and cheaper implementation E.g. WL0 A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 ( A0 A1 )( A2 A3 )( A4 A5 )( A6 A7 )( A8 A9 ) WL1 WL0 8 A0A1 A0A1 A0A1 A0A1 A2A3 A2A3 A2A3 A2A3 A1 A0 A0 A3 A2 A1 A2 A3 ELEC516/10 Lecture 8 Dynamic Row Decoders Propagation delay is primary concern Precharge devicesGND GND VDD WL3 VDD WL2 VDD WL1 VDD WL0 VDDf A0 A0 A1 A1 Dynamic 2-to-4 NOR decoder WL3 WL2 WL1 WL0 A0 A0 A1 A1 f 2-to-4 MOS dynamic NAND Decoder • NOR option: Only one line stays high, all other lines pulled low (power). • NOR decoders are substantially faster but they consume more area than their NAND counterparts and more power. 9 ELEC516/10 Lecture 8 Column Decoder • Responsible for selecting 2k out of 2m bits of the accessed row. • Column-decoding is one of the last actions to be performed in the read-sequence, so that the decoding can be executed in parallel with other operations such as memory access and sensing. Consequently, its propagation delay does not add to the overall memory access time. Slower decoders might even be acceptable. • Two ways of implementations: – pass transistor mux-based – tree-based 10 ELEC516/10 Lecture 8 Pass transistor mux type column decoder 2 input NOR decoder • Control signals of the pass-transistors are generated using a K-to-2K pre-decoder. • Main advantage is its speed, since only a single passtransistor is inserted in the signal path,what introduces only a minimal extra resistance • Disadvantage - large BL0 BL1 BL2 BL3 transistor count: (K+1)2K+ 2K devices are needed for a 2K-input S0 A0 decoder. e.g. a 1024-to1 column decoder S1 requires 12,288 transistors. S2 • Also the capacitance A1 and thus the transient S3 response at node D is proportional to the number of input of the multiplexer. ELEC516/10 Lecture 8 11 D Tree based column decoder •Number of devices drastically reduced •Delay depends on number of pass transistors in series, increases quadratically with # of sections; prohibitive for large decoders •Solutions: •Buffers •Progress sizing •Combination of tree and pass transistor approaches BL0 BL1 BL2 BL3 A0 A0 A1 A1 12 D ELEC516/10 Lecture 8 Tree based column decoder • uses a binary reduction. No pre-decoder is required. For 2K-input decoder, it needs (1024-1 decoder: 2046 devices) N tree 2 2 K BL0 BL1 BL2 A0 A0 A1 A1 D 13 K 1 BL3 4 2 2 (2 1) K • Disadvantages:Delay depends on number of pass transistors in series, increases quadratically with # of sections; prohibitive for large decoders • Solutions: – Buffers – Progress sizing – Combination of tree and pass transistor approaches ELEC516/10 Lecture 8 ROM connected to a column tree decoder To sense Amplifier 14 ELEC516/10 Lecture 8 Hybrid pass-transistor and tree-based • A fraction of the address word is pre-decoded (the msb-side), while the remaining bits are tree-decoded. This can reduce both the transistor count and the propagation delay. • E.g. Consider a 1024-to-1 decoder, pre-decoding 5 bits results in the following transistor tally N dec N pre N pass Ntree (6 25 210 2 (25 1)) 1278 • The number of series-connected pass-transistors is reduced to six 15 ELEC516/10 Lecture 8 Decoder by circular shift-register VDD VDD WL0 VDD VDD WL1 f f VDD VDD WL2 f f f f ... R f f R f f R f f VDD 16 ELEC516/10 Lecture 8 Sense Amplifiers • functions: – Amplification - essential for 1T DRAM, where the signal swing would otherwise be restricted to approximately 250 mV – performance speed-up - compensates for the restricted fan-out driving capability of the memory cell by accelerating the bit line transition – power reduction - reducing signal swing on the bit lines can eliminate a substantial part of the power dissipation related to charging and discharging the bit lines. 17 ELEC516/10 Lecture 8 Sense Amplifier t C DV = ---------------p Iav large make D V as small as possible small Idea: Use Sense Amplifer small transition s.a. input 18 output ELEC516/10 Lecture 8 Differential Voltage sensing Amplifiers • Differential approach presents numerous advantages: – Common mode rejection: ability to reject noise that is equally injected to both inputs and amplifies the difference. – Noise such as cross-talk between WL & BL can be suppressed. – Effectiveness of this property is called common mode rejection ratio (CMRR). – Spikes at the supply voltage are also suppressed (effectiveness: power supply rejection ratio PSRR). • Basic diff amplifier is based on the current mirroring concept: Inputs are fed to the differential input device M1 and M2, M3 and M4 act as active current mirror load V DD M M 3 4 y Output M bit 1 M 2 Bit’ SE 19 ELEC516/10 Lecture 8 Two stage approach Vdd Vdd - D Vdd Vdd - D D Vdd - D Vdd D D One stage 2D Two stages • Fully differential two stage sensing approach along with SRAM bit line structure can be used. 20 ELEC516/10 Lecture 8 Differential Sensing - SRAM VDD VDD BL PC VDD EQ VDD y M3 BL M1 x SE WLi M4 M2 y x x x M5 SE (b) Doubled-ended Current Mirror Amplifier VDD Limits the bit line swing and speed up the Next prechar SRAM cell i y Diff. x Sense x Amp y y D D (a) SRAM sensing scheme. y x x SE (c) Cross-Coupled Amplifier 1. PC is pulled low, PMOS is ON: Equalization. 2. Read operation is started by disabling the precharge & equal, and one of BL is pulled low 3. Sense ampl is ON: ELEC516/10 Lecture 8 21 SE is turned ON one a sufficient signal is built-up . 2 stage differential amplifier V M y V DD M 3 M x SE M 1 M 2 Vdd Vdd - D DD Vdd - D Vdd 2y 4 2x 2x x 5 D SE D SE 2D V DD • By pulsing the SE control signal to be active for short evaluation period, static power is reduced. Output y SE (b) two stage differential amplifier 22 ELEC516/10 Lecture 8 Latch-Based Sense Amplifier • Initialized in its meta-stable point with EQ • Once adequate voltage gap created, sense amp enabled with SE • Positive feedback quickly forces output to a stable operating point. EQ BL BL V DD SE SE 23 ELEC516/10 Lecture 8 Latch-Based Sense Amplifier • Simple and fast implementation. • Inputs and outputs are merged, so a full rail to rail transition is enforced on the bit lines. • This is exactly what’s needed for 1T DRAM, where a restoration of the signal levels on the bit lines is necessary for the refresh of the cell contents. • Cross coupled cell is universally used in DRAM designs. • Issue: We need to turn a single ended memory structure such as DRAM into a differential one. 24 ELEC516/10 Lecture 8 Charge-Redistribution Amplifier • The idea is to explore the imbalance between a large capacitance Clarge and a much smaller cap Csmall • The two capacitors are isolated by the pass transistor M1. • Initial voltages on L and S are Vref –Vtn and VDD. • When pull-down turns ON (ex:M2), Node discharge slowly (Clarge). • As long as VL >= Vref –Vtn, M1 is off. • When the threshold is crossed, M1 is ON and Vs is discharged very rapidly • Slow discharge on Clarge generate fast discharge on Csmall Can be used for sensing. 25 Vref Concept VL M2 M3 M1 VS Csmall Clarge Transient Response ELEC516/10 Lecture 8 Charge-Redistribution Amplifier―EPROM V DD SE • Disadvantage: The circuit operates with very small noise margin: A small variation on node L due to noise or leakage may cause erroneous discharge of S. Load M4 Out V casc M3 Cascode device Cout Ccol WLC Column decoder M2 BL WL 26 M1 CBL EPROM array ELEC516/10 Lecture 8 Single-to-Differential Conversion • A differential sensing amplifier is connected to a single-ended bit line on one side and a reference voltage on the other side. WL BL x Diff. cell x + _ S.A. y Vref y How to make good Vref? • Depending on the bit line BL, the amplifier toggles in one or the other direction. • Having good Vref is a key problem: not easy across a large chip. 27 ELEC516/10 Lecture 8 Open bitline architecture with Dummy cell EQ L1 R L0 R0 R1 L VDD dummy cell CS SE BLL ... CS BLR CS SE CS ... CS dummy cell CS • • • • • • • The memory array is divided in two halves, Dif Amp in middle Dummy cells are used as a reference. EQ is raised, both BLL and BLR are precharged to Vdd/2. During read, one word line is enabled (ex: L0), voltage change on BLL. L is raised on the other half to create the voltage reference, BLR=vdd/2 The sense latch will toggle. Matching is very important: capacitive coupling can be eliminated as turning both L0 and L at the same time creates a common-mode signal. • Advantage: dividing bit lines into two halves reduces the BL cap. 28 ELEC516/10 Lecture 8 DRAM Read Process with Dummy Cell 3 3 2 2 BL precharge V 1 0 0 BL V BL 1 2 3 1 0 BL 0 1 2 t (ns) 3 t (ns) reading 0 reading 1 3 • Control Sequence: – Equalize, V – Precharge, – Read (Enable WL) – Once a good dV is built we sense the voltage (Enable SE) 29 EQ WL 2 SE 1 0 0 1 2 3 t (ns) control signals ELEC516/10 Lecture 8 RAM timing budget • Critical path: clock to address delay time-> row address driver time-> row decode time -> bit-line sense time -> the setup time to any data register. • The column decode is usually not in the critical path because the decoder is usually smaller and the decoder has the row access time and the bit-line sense time to operate. • The write operation is usually faster than the read cycle because the bit lines are being actively driven by larger transistors than the memory cell transistors. However the bit lines may have to be allowed to recover to their quiescent values before any more access cycles take place. • In the static load RAM, this speed depends on the size of the static pull-up. • Apart from carefully sizing transistors, the RAM speed may be increased by pipelining the row decode signal. 30 ELEC516/10 Lecture 8 Voltage Regulator Equivalent Model VDD Mdrive VDL VREF Vbias VREF + Mdrive VDL • Many regulated voltage levels can be required in memory circuitry: – Boosted word line voltages (to avoid Vt drop ex: 1T DRAM). – Half Vdd (DRAM bit lines are precharged to Vdd/2). – Reduced internal supply: internal voltage regulators are required. – Negative supply bias: An effective way to control the threshold voltages within a memory 31 ELEC516/10 Lecture 8 Charge Pump • Word line boosting and well biasing often require voltage sources that exceed the supply voltage. – Can be obtained using charge pump circuits – CLK high, VB charged to Vdd-Vt, however when CLK goes low, A is raised to Vdd, B will rise in concert effectively shutting off M1, once B is one threshold above Vload, M2 is ON and charge transferred to Vload. 32 ELEC516/10 Lecture 8 Address Transition Detection • ATD circuit plays an essential role in SRAM and PROM modules. • It automatically generates the internal signals (ex: SE) upon detection of a change in the external environment. V DD A0 DELAY td A1 DELAY td A N2 1 DELAY td ATD ATD … • A transition of any of the input signal causes ATD to go low for a time td. • The resulting pulse acts as the main timing reference: large fan-in requiring proper buffering. 33 ELEC516/10 Lecture 8 Reliability and Yield 34 ELEC516/10 Lecture 8 Sensing Parameters in DRAM • Signal quality degrades gradually 1000 with an increase in density: C D(1F) V smax (mv) – DRAM cell capacitance degraded from 70fF to 30fF (16K) Q S(1C) – Voltage levels have decreased 100 C S(1F) (below 1V is being the norm). smax V – Conseq: The , signal charge stored on the capa has dropped. DD 10 ,Stime, higher – At the sameV integration C more noise. ,generates V DD (V) S – Word to bit Q coupling was Q S = C S V DD / 2 ,line D already an C issue in 80s: closer V smax = Q S / (C S + C D ) line spacing…… 4K 64K 1M 16M 256M 4G 64G – Also higher speed: increased switching noise for every new Memory Capacity (bits / chip) generation CD Vsmax, Qs and Cs are: bit line cap, From [Itoh01] Sense signal, cell charge and cell cap ELEC516/10 Lecture 8 35 Noise Sources in 1T DRam • Source of noises: – Word-line-to bit-line coupling: When wl selected, charge is injected into the bit line due to Cwbl – Bit-line-to-bit line coupling: BL run side by side. – Leakage: cause voltage drop due to p-n junction and subthreshold. – Soft errors caused by alpha particle and substrate Adjacent BL BL • Solutions: CWBL a -particles – Smart design turning noise into a common WL mode signal, – Design Techniques for leakage reduced leakage. CS – Errors corrected through electrode redundancy and error correction encoding + protection against alpha Ccross radiation 36 ELEC516/10 Lecture 8 Open Bit-line Architecture —Cross Coupling EQ WL 1 WL 0 WL C WBL D C WBL WL D WL 1 WL 0 BL BL C BL C C C Sense Amplifier C BL C C C • When word line is driven high (WL0), the presence of a coupling capacitor CWBL will cause charge redistribution to occur with amplitude: DWL CWBL /(CWBL CBL ) • If both sides of the memory array were completely symmetrical, the injected bit line noise would appear as a common mode signal to the sense ampli. • Unfortunately this is not the case because both coupling and bit line capacitance can vary substantially over the array 37 ELEC516/10 Lecture 8 Folded-Bitline Architecture WL 1 WL 0 C WBL WL 0 WL D WL D CBL BL … BL WL 1 C x C C C C C Sense EQ Amplifier x CBL y y CWBL • Folded architecture: Placing the sense amplifier at the end of the array and having BL and BL’ routed next to each other ensures a much closer matching between: parasitic and bit line cap. • WL0 and WLD, cross both bit lines and at close ranges. • Cross coupling noise appears as a common mode signal to the sense ampl. • Drawback: Longer bit line, and hence increased capacitance. 38 ELEC516/10 Lecture 8 Bit-Line to Bit-Line Coupling • The impact of interwire cross coupling increases with reduced dimensions. • Noise sensitive lines run side by side for long distances. • Both BL and BL’ are coupled to adjacent lines through Cross. • In the worst case, the signal swing observed at the sense amplifier can be reduced by: DVcross 2 Ccross Vswing Ccross C BL • Up to ¼ of the already weak signal can be lost to this interference. • The question is: Can we turn this noise into a common mode signal? In other words can we make this disturbance affect equally BL and BL’? • Answer: Yes, by dividing the bit lines into segments that are connected in a cross coupled fashion: Transposed bit line architecture ../.. 39 ELEC516/10 Lecture 8 Transposed-Bitline Architecture Ccross BL 9 BL SA BL BL 99 (a) Straightforward bit-line routing Ccross BL 9 BL SA BL BL 99 (b) Transposed bit-line architecture 40 ELEC516/10 Lecture 8 Alpha particles (or Neutrons) • Early memory designers were puzzled by the occurrence of soft errors (non-recurrent and non permanent errors). • Not explained by either supply noise, leakage or cross coupling (can cause a computer system to crash). • May and woods (May97) identified the source as being alpha particles: – Alpha particles (two protons, two neutrons) are emitted for radioactive elements. Traces of such elements are found in device packaging materials. – Alpha particles can travel up to 10 um deep in the silicon generating roughly 2M e-hole pairs in the structure. – Soft error occur when the trajectory of one of these particles strikes the storage node of the memory. 41 ELEC516/10 Lecture 8 Alpha-particles (or Neutrons) WL a -particle V DD BL n1 SiO 2 2 1 2 1 1 2 2 1 2 1 1 2 1 Particle ~ 1 Million Carriers • Electrons and holes generated by a striking particle diffuse through the substrate. • Electrons that reach the edge of the depletion region before recombining are swept into the storage node by electrical field. • If enough electrons are collected a “1” stored can change to “0” 42 ELEC516/10 Lecture 8 Alpha particles • The occurrence of soft errors can be reduced by keeping the cell charge larger that a critical charge Qc. • Ex: Cap of 50fF charged to a voltage to 3.5V holds 1.1Me. A single Alpha particle with a collection efficiency of 55% can erase the complete charge. • That’s the reason why the cell capacitance of even the densest memory is kept to 30fF. • Chip coating and purification of materials is also used to purify the materials in order to reduce the number of alpha particles. • Memory die can also be covered by polymide to protect against alpha radiation. 43 ELEC516/10 Lecture 8 Yield • With increasing die size and integration density, a reduction in yield is to be expected. • Memory designers use two techniques to combat low yield: – Redundancy – Error correction Yield curves at different stages of process maturity (from [Veendrick92]) 44 ELEC516/10 Lecture 8 Redundancy Row Address Redundant rows : Fuse Bank Redundant columns Memory Array Column Decoder Column Address Row Decoder • As the structure is regular, redundant hardware is easily realized • Defective bit lines in a memory can therefore be replaced by redundant ones, and the same hold for the word lines. • Can be achieved by programming a fuse bank once defaults have been detected. 45 ELEC516/10 Lecture 8 Error-Correcting Codes Example: Hamming Codes e.g. B3 Wrong with 1 1 =3 0 • Adding for example a parity bit to a data word can allow to detect an error (but cannot correct it). • Using hamming code can allow to detect and correct the error: B are the stored bits and P are the parity bits. 46 ELEC516/10 Lecture 8 Redundancy and Error Correction With over 1000 failing cells a yield of 100 % is still achievable. • Error correction not only combats technology related faults but is also effective in dealing with soft errors. • Error correction and redundancy address different angles of memory yield. • Combining the two gives very good results [Kalter90] 47 ELEC516/10 Lecture 8 Sources of Power Dissipation in Memories V DD Dynamic Current I DD= Sum C iD V if+Sum I DCP CHIP nC DE V INT f mi act I DCP m.iact + m.(n-1).ihld n ROW DEC PERIPHERY IDD= Iarray + Idecode +Iperiphery m selected C PT V INT f m(n - 1)i hld non-selected ARRAY mC DE V INT f COLUMN DEC V SS 48 DC Current From [Itoh00] [(n+m).CDE .V.f] [CPT .V. f + IDCP] • Power dominated by array • Power is proportional to memory size (n,m). • Dividing the memory into subarrays with n,m small will reduce power. ELEC516/10 Lecture 8 Reducing power in Memories • Partitioning the memory: Memory units in stand-by mode only consumes power necessary for data retention. • Partitioning is achieved by dividing the word line into subword lines that are enabled only when necessary. • Partitioning can also be applied to the bit line in order to reduce the capacitance switched. • Reduce the voltage swing as much as possible typ 0.1-0.3V • Current flow through the BL as long as WL is ON. Reduce the time during which WL is ON. • Self-timing strategy can help in reducing the ON time. • For write operation a full swing is applied on BL (the only solution is to reduce Vdd). • Reducing supply can affect the speed: reducing Vth might be more suitable if the leakage is appropriately dealt with 49 ELEC516/10 Lecture 8 Data Retention in SRAM • In theory, an SRAM should not have any static power dissipation (ihold) yet leakage current of the cell is becoming a major issue 1.30u 1.10u 0.13 m m CMOS Ileakage 900n 700n (A)500n Factor 7 300n 0.18 m m CMOS 100n 0.00 .600 1.20 1.80 VDD SRAM leakage increases with technology scaling 50 ELEC516/10 Lecture 8 Suppressing Leakage in SRAM As low as 100 mV V DD V DD low-threshold transistor V DDL sleep V DD,int sleep V DD,int SRAM cell SRAM cell sleep SRAM cell SRAM cell SRAM cell V SS,int Inserting Extra Resistance 51 SRAM cell Reducing the supply voltage during data retention mode (refer to previous slide) ELEC516/10 Lecture 8 Data Retention in DRAM Active current Data retention current Considerably increasing (smaller cell and lower Power frequent refresh Is required for newer gen). 52 From [Itoh00] DRAM have to be refreshed continuously in data retention mode. Standby current is the a function of refreshment freq. ELEC516/10 Lecture 8 Register Files • Register files are generally fast RAMs with multiple read and write ports. Conventional RAM cells may be made multiported by adding pass transistors 53 ELEC516/10 Lecture 8 FIFOs • A First In First Out (FIFO) is useful for buffering data between two asynchronous data streams 54 ELEC516/10 Lecture 8 FIFOs • The simplest implementation of a FIFO uses a dual port RAM or register file with a read and write counter 55 ELEC516/10 Lecture 8 LIFOs • Last In First Out (LIFO) memory, or push down stack, is of use in such applications as subroutine stacks in microcontrollers. • Like FIFO, regular RAMs or register files may be used or special distributed row decoders may be designed as the address pointer moves sequentially from row to row. 56 ELEC516/10 Lecture 8 SIPOs • Serial In Parallel Output (SIPO) is of use to convert serial data to a parallel form. Mostly used in signalprocessing applications. • An example of the memory cell used in this type of memory is shown below 57 •Data is shifted in at a high rate via the complementary clock clk and -clk, which should be non-overlapping to prevent data feedthrough. Data may be read in parallel through access transistor N1 with an appropriately timed clock pulse. ELEC516/10 Lecture 8 Serial-Access Memory • Serial-access memories (shift registers) are also of use in signal-processing applications for storage and delaying signals. A serial-access memory may be simulated by a RAM, and probably for most applications this provides the smallest implementation because the CMOS static RAM cell is a very area efficient structure • However, RAM has a lot overhead: row and column decoders, sense amplifier and in the case of serial access memory, a counter. Therefore, sometimes a dedicated shift register memory may be appropriate. • The following shows how a 64-byte tapped delay line that might be used in a video processing system is implemented 58 ELEC516/10 Lecture 8 • Blocks of byte-wide shift registers are delayed by 32, 16, 8,4,2 and 1 cycles, and multiplexers control the passaround of the delay blocks to yield the appropriate delay amount. Each memory is a shift register. 59 ELEC516/10 Lecture 8 Case Studies • SRAM • Flash Memory 60 ELEC516/10 Lecture 8 4 Mbit SRAM Hierarchical Word-line Architecture 61 ELEC516/10 Lecture 8 4 Mbit SRAM Hierarchical Word-line Architecture Hierarchical word decoding scheme: Instead of broadcasting the decoded X address to all blocks in polysilicon, it is distributed in metal and called the global word line. The local word line is confined to a single block and is only activated when that particular block is selected by using the block address. Only 16 sense amplifiers are used per block of 128 columns. 62 ELEC516/10 Lecture 8 Bit-line Circuitry Block select Bit-line load Limits the bit line swing and speed up the Next prechar ATD BEQ Local WL Memory cell B /T B /T CD CD CD I/O I/O line I/O Sense amplifier CD: Column decoder address. Memory cell is a 4T cell realized using multi-poly process, R=10TΩ The process starts by an equalization pulse. All timing is generated through an ATD circuit. ELEC516/10 Lecture 8 63 Sense Amplifier (and Waveforms) I /O I /O Address SEQ Block select ATD ATD BS SA BS BEQ SA SEQ Vdd I/O Lines GND SEQ SEQ SEQ SEQ DATA Dei BS Sense Amplifier contains two stages: 1st stage: Cross-coupled stage provides min gain and acts as a level shifter for the 2nd stage 2nd stage: current mirror type operating at max gain point + push pull output. 64 Vdd SA, SA GND DATA Data-cut ELEC516/10 Lecture 8 1 Gbit Flash Memory • Two blocks of 512Mb each. • BL of 32 bits/blocks. • Each line connects 1024 of these blocks. • The word lines are driven from both sides • Page size (number of bits that can be read in one cycle) is 2KByte. •The large page size allows high programming rate 10 MByte/s. • Further speed-up is obtained through an extra cache memory: New data can be read while the previous data is being written or verified (cache). 65 From [Nakamura02] ELEC516/10 Lecture 8 Charge pump 2kB Page buffer & cache 10.7mm 125mm2 1Gbit NAND Flash Memory 32 word lines x 1024 blocks 16896 bit lines • Technology • • • • • • • • 1poly, 1polycide, 1W, 2Al Cell size 0.077m2 Chip size 125.2mm2 Organization 2112 x 8b x 64 page x 1k block Power supply 2.7V-3.6V Cycle time 50ns Read time 25s Program time 200s / page Erase time 2ms / block 0.13m p-sub CMOS triple-well 11.7mm 66 From [Nakamura02] ELEC516/10 Lecture 8