Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
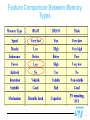
Semiconductor Memory Design (SRAM & DRAM) Kaushik Saha Contact: [email protected], mobile-98110-64398 STMicroelectronics Understanding the Memory Trade The memory market is the most - Volatile - Cost Competitive - Innovative in the IC trade Supply Demand Memory market Technical Change 2 Classification of Memories RWMemory Random Access SRAM (Static) DRAM (Dynamic) Non-Random Access FIFO (Queue) LIFO (Stack) SR (Shift Register) CAM (Content Addressable) NVRWM ROM EPROM EEPROM Mask Programmed FLASH PROM (Fuse Programmed) 3 Feature Comparison Between Memory Types 4 Memory selection : cost and performance DRAM, EPROM - Merit : cheap, high density - Demerit : low speed, high power SRAM - Merit : high speed or low power - Demerit : expensive, low density Large memory with cost pressure : - DRAM Large memory with very fast speed : - SRAM or - DRAM main + SRAM cache Back-up main for no data loss when power failure - SRAM with battery back-up - EEPROM 5 Trends in Storage Technology Generation Increasing die size factor 1.5 per generation Combined with reducing cell size factor 2.6 per generation *MB=Mbytes 6 The Need for Innovation in Memory Industry The learning rate (viz. the constant b) is the highest for the memory industry - Because prices drop most steeply among all ICs • Due to the nature of demand + supply - Yet margins must the maintained Techniques must be applied to reduce production cost Often, memories are the launch vehicles for a technology node - Leads to volatile nature of prices 7 Memory Hierarchy of a Modern Computer System By taking advantage of the principle of locality: - Present the user with as much memory as is available in the cheapest technology. - Provide access at the speed offered by the fastest technology. Processor Control Registers Speed (ns): 1s Size (bytes): 100s On-Chip Cache Datapath Second Level Cache (SRAM) Main Memory (DRAM) 10s 100s Ks Ms Secondary Storage (Disk) Tertiary Storage (Tape) 10,000,000s 10,000,000,000s (10s ms) (10s sec) Gs Ts 8 How is the hierarchy managed? Registers <-> Memory - by compiler (programmer?) cache <-> memory - by the hardware memory <-> disks - by the hardware and operating system (virtual memory) - by the programmer (files) 9 Memory Hierarchy Technology Random Access: - “Random” is good: access time is the same for all locations - DRAM: Dynamic Random Access Memory • • High density, low power, cheap, slow Dynamic: need to be “refreshed” regularly - SRAM: Static Random Access Memory • • Low density, high power, expensive, fast Static: content will last “forever”(until lose power) “Not-so-random” Access Technology: - Access time varies from location to location and from time to time - Examples: Disk, CDROM 10 Main Memory Background Performance of Main Memory: - Latency: Cache Miss Penalty • • Access Time: time between request and word arrives Cycle Time: time between requests - Bandwidth: I/O & Large Block Miss Penalty (L2) Main Memory is DRAM : Dynamic Random Access Memory - Dynamic since needs to be refreshed periodically Addresses divided into 2 halves (Memory as a 2D matrix): • • RAS or Row Access Strobe CAS or Column Access Strobe Cache uses SRAM : Static Random Access Memory - No refresh (6 transistors/bit vs. 1 transistor) Size: DRAM/SRAM 4-8 Cost/Cycle time: SRAM/DRAM 8-16 11 Memory Interfaces Address i/ps - Maybe latched with strobe signals Write Enable (/WE) - To choose between read / write - To control writing of new data to memory Chip Select (/CS) - To choose between memory chips / banks on system Output Enable (/OE) - To control o/p buffer in read circuitry Data i/os - For large memories data i/p and o/p muxed on same pins, • selected with /WE Refresh signals 12 Memory - Basic Organization S0 Word 0 • N words S1 S2 Word 1 Word 2 Single Storage Cell • M bits per word • N select lines • 1:N decoder • very inefficient design SN-2 Word N-2 SN-1 Word N-1 • difficult to place and route M bit output word 13 Memory - Real Organization Array of N x K words S0 row 0 C of M bit words row 1 C of M bit words row 2 C of M bit words row N-2 C of M bit words row N-1 Row Decoder SR-1 Log2C Address Lines N=R*C C of M bit words ------------- rows R------------ Log2R Address Lines ------------- columns ------------ KxM - - - - KxM bits - - - - Column Select M bit data word 14 Array-Structured Memory Architecture Problem: ASPECT RATIO or HEIGHT >> WIDTH AK AK+1 AL-1 Bit Line Storage Cell Row Decoder 2L-K Word Line M.2K Sense Amplifiers / Drivers A0 Column Decoder AK -1 Amplify swing to rail-to-rail amplitude Selects appropriate word Input-Output (M bits) 15 Hierarchical Memory Architecture Row Address Column Address Block Address Global Data Bus Control Circuitry Block Selector Global Amplifier/Driver I/O Advantages: 1. Shorter wires within blocks 2. Block address activates only 1 block => power savings 16 Memory - Organization and Cell Design Issues aspect ratio (height : width) should be relative square - Row / Column organisation (matrix) - R = log2(N_rows); C = log2(N_columns) - R + C = N (N_address_bits) number of rows should be power of 2 - number of bits in a row sense amplifiers to amplify the voltage from each memory cell 1 -> 2R row decoder 1 -> 2C column decoder - implement M of the column decoders (M bits, one per bit) • M = output word width 17 Semiconductor Manufacturing Process 18 Basic Micro Technology 19 Semiconductor Manufacturing Process Fundamental Processing Steps 1.Silicon Manufacturing a) Czochralski method. b) Wafer Manufacturing c) Crystal structure 2.Photolithography a) Photoresists b) Photomask and Reticles c) Patterning 20 Lithography Requirements 21 Excimer Laser DUV & EUV lithography Power o/p Pulse Rate NovaLine Laser – Lambda Physik 22 Dry or Plasma Etching 23 Dry or Plasma Etching 24 Dry or Plasma Etching Combination of chemical and physical etching – Reactive Ion Etching (RIE) Directional etching due to ion assistance. In RIE processes the wafers sit on the powered electrode. This placement sets up a negative bias on the wafer which accelerates positively charge ions toward the surface. These ions enhance the chemical etching mechanisms and allow anisotropic etching. Wet etches are simpler, but dry etches provide better line width control since it is anisotropic. 25 Dry Etching Reactive Ion Etching- RIE 26 CMOS fabrication sequence 4.2 Local oxidation of silicon (LOCOS) - - - Paulo Moreira The photoresist mask is removed The SiO2/SiN layers will now act as masks The thick field oxide is then grown by: • exposing the surface of the wafer to a flow of oxygen-rich gas The oxide grows in both the vertical and lateral directions This results in a active area smaller than patterned patterned active area Field oxide (FOX) n-well active area after LOCOS Technology p-type 27 LOCOS: Local Oxidation 28 Advanced CMOS processes Shallow trench isolation n+ and p+-doped polysilicon gates (low threshold) source-drain extensions LDD (hot-electron effects) Self-aligned silicide (spacers) Non-uniform channel doping (short-channel effects) n+ poly Silicide p+ poly Oxide spacer n+ p-doping p+ n+ n-doping p+ n-well Shallow-trench isolation Source-drain extension p-type substrate Paulo Moreira Technology 29 Process enhancements Up to eight metal levels in modern processes Copper for metal levels 2 and higher Stacked contacts and vias Chemical Metal Polishing for technologies with several metal levels For analog applications some processes offer: - capacitors - resistors - bipolar transistors (BiCMOS) Paulo Moreira Technology 30 Metalisation Metal deposited first, followed by photoresist Then metal etched away to leave pattern, gaps filled with SiO2 31 Electroplating Based Damascene Process Sequence Pre-clean IMP barrier + Copper 25 nm 10-20 nm Electroplating CMP + 100-200 nm Simple, Low-cost, Hybrid, Robust Fill Solution 32 33 34 Example CMOS SRAM Process 0.7u n-channel min gate length, 0.6u Leff 1.0u FOX isolation using SiNiO2 masking 0.25u N+ to P+ spacing Thin epi material to suppress latchup Twin well to suppress parasitic channel through field transistors LDD struct for n & p transistors to suppress hot carrier effects Buried contacts to overlying metal or underlying gates Metal salicide to reduce poly resistivity 2 metals to reduce die area Planarisation after all major process steps - To reduce step coverage problems • on contact cut fills • Large oxide depositions 35 SRAM Application Areas Main memory in high performance small system Main memory in low power consumption system Simpler and less expensive system if without a cache Battery back-up Battery operated system 36 SRAM Performance vs Application Families 37 Typical Application Scenarios SRAM MMU FPU BIU CORE L1 16KB L2 256KB ALU DRAM 64MB I/O PCI ISA i586 based PC Hand phone and Cache 38 Market View by Application 39 Overview of SRAM Types SRAMs Asynchronous Low Speed Medium Speed High Speed Synchronous Flow Through / Pipelined Zero Bus Turnaround Double Data Rate Dual Port Interleaved / Linear Burst Special CAM / Cache Tag FIFO Multiport 40 SRAM Array SL0 Array Organization • common bit precharge lines • need sense amplifier SL1 SL2 41 Logic Diagram of a Typical SRAM A0-AN CS! WE_L 2 N words x M bit SRAM OE_L M D Write Enable is usually active low (WE_L) Din and Dout are combined to save pins: - A new control signal, output enable (OE_L) is needed - WE_L = 0, OE_L = 1 • D serves as the data input pin - WE_L = 1, OE_L = 0 • D is the data output pin - Both WE_L = 1, OE_L = 1 • Result is unknown. Don’t do that!!! 42 Simple 4x4 SRAM Memory read precharge enable 2 bit width M=2 A1 R=2 N_rows = 2R = 4 C=1 A2 c N_columns = 2 x M = 4 N=R+C=3 Array size = N_rows x N_columns = 16 bit line precharge WL[0] BL !BL WL[1] -> WL[2] WL[3] A0 A0! clocking and control -> Column Decoder sense amplifiers WE! , OE! write circuitry 43 Basic Memory Read Cycle System selects memory with /CS=L System presents correct address (A0-AN) System turns o/p buffers on with /OE=L System tri-states previous data sources within a permissible time limit (tOLZ or tCLZ) System must wait minimum time of tAA, tAC or tOE to get correct data 44 Basic Memory Write Cycle System presents correct address (A0-AN) System selects memory with /CS=L System waits a minimum time equal to internal setup time of new addresses (tAS) System enables writing with /WE=L System waits for minimum time to disable o/p driver (twz) System inputs data and waits minimum time (tDW) for data to be written in core, then turns off write (/WE=H) 45 Memory Timing: Definitions Read Cycle READ Read Access Read Access Write Cycle WRITE Write Access Data Valid DATA Data Written 46 Memory Timing: Approaches MSB Address Bus LSB Row Address Column Address Address Bus RAS Address Address transition initiates memory operation CAS RAS-CAS timing DRAM Timing Multiplexed Adressing SRAM Timing Self-timed 47 The system level view of Async SRAMs 48 The system level view of synch SRAMs 49 Typical Async SRAM Timing A N WE_L 2 N words x M bit SRAM OE_L M Write Timing: D Data In D Read Timing: High Z Data Out Data Out Junk A Write Address Read Address Read Address OE_L WE_L Write Hold Time Read Access Time Read Access Time Write Setup Time 50 SRAM Read Timing (typical) tAA (access time for address): how long it takes to get stable output after a change in address. tACS (access time for chip select): how long it takes to get stable output after CS is asserted. tOE (output enable time): how long it takes for the three-state output buffers to leave the highimpedance state when OE and CS are both asserted. tOZ (output-disable time): how long it takes for the three-state output buffers to enter highimpedance state after OE or CS are negated. tOH (output-hold time): how long the output data remains valid after a change to the address inputs. 51 SRAM Read Timing (typical) stable ADDR stable stable tAA Max(tAA, tACS) CS_L tOH tACS OE_L tAA DOUT tOZ valid tOE tOZ valid tOE valid WE_L = HIGH 52 SRAM Architecture and Read Timings tOH tAA tACS tOZ tOE 53 SRAM write cycle timing /WE controlled /CS controlled 54 SRAM Architecture and Write Timings Setup time = tDW tDH Write driver tWP-tDW 55 SRAM Architecture 56 SRAM Cell Design Memory array typically needs to store lots of bits - Need to optimize cell design for area and performance - Peripheral circuits can be complex • Smaller compared to the array (60-70% area in array, 30-40% in periphery) Memory cell design - 6T cell full CMOS - 4T cell with high resistance poly load - TFT load cell 57 Anatomy of the SRAM Cell -> Write: •set bit lines to new data value •b’ = opposite of b •raise word line to “high” •sets cell to new state •May need to flip old state Read: •set bit lines high •set word line high •see which bit line goes low 58 SRAM Cell Operating Principle •Inverter Amplifies •Negative gain •Slope < –1 in middle •Saturates at ends • Inverter Pair Amplifies •Positive gain •Slope > 1 in middle •Saturates at ends 59 Bistable Element Stability Require Vin = V2 Stable at endpoints recover from pertubation Metastable in middle Fall out when perturbed Ball on Ramp Analogy 60 SRAM Cell technologies Bipolar ECL : NPN with dual emitter NMOS load A) Enhancement : additional load gate bias B) Depletion : no additional load gate bias High Load Resistance (4T) Full CMOS (6T) Thin Film Transistors 61 6T & 4T cell Implementation 6T Bistable Latch High resistance poly 4T Bistable Latch 62 Reading a Cell Icell DV = Icell * t ----Cb Sense Amplifier 63 Writing a Cell 0 -> 1 1 -> 0 64 Bistable Element Stability Require Vin = V2 Stable at endpoints recover from pertubation Metastable in middle Fall out when perturbed Ball on Ramp Analogy 65 Cell Static Noise Margin Cell state may be disturbed by •DC •Layout pattern offset •Process mismatches •non-uniformity of implantation •gate pattern size errors •AC •Alpha particles •Crosstalk •Voltage supply ripple •Thermal noise SNM = Maximum Value of Vn Without flipping cell state 66 SNM: Butterfly Curves 1 SNM 2 2 SNM 1 2 1 1 2 67 SNM for Poly Load Cell 68 6T Cell LayoutN Well B- B+ Connection VDD PMOS Pull Up Q/ Q NMOS Pull Down GND SEL SEL MOSFET Substrate Connection 69 6T SRAM Array Layout 70 Another 6T Cell Layout Stick Diagram bit bit’ VDD T T T T T T word Gnd GND and contact shared with cell to left These four contacts shared with (mirrored) cell below 2 Metal Layer Process 71 6T Array Layout (2x2) Stick Diagram bit Gnd VDD bit’ bit Gnd bit’ VDD word word VDD 72 6T Cell Full Layout Transistor sizing - M2 (pMOS) 4:3 - M1 (nMOS) 6:2 - M3 (nMOS) 4:2 M2 All boundaries shared 38l H x 28l W Reduced cap on bit lines M1 M3 73 6T Cell – Example Layout & Abutment Vdd Vdd Vdd T4 T3 T4 T2 T3 Vdd Vss T3 T4 T1 T1 Vss Vss T5 T6 Vdd T6 T5 T5 T6 T6 T2 Vss Vss T5 T1 T2 Vss Vss T3 Vdd T4 B’ B T3 B’ B Vss Vdd Vdd T4 T2 T6 B T1 T1 T5 T2 Vss 4 x 4 array 2 x 2 abutment 74 6T and 4T Cell Layouts R1 BIT T6 Vdd GND T4 VDD T5 R2 BIT! T3 Q Q T1 T4 T3T2 T1 Word Line T2 BL GND WL BL 75 6T - 4T Cell Comparison 6T cell - Merits • Faster • Better Noise Immunity • Low standby current - Demerits • Large size due to 6 transistors 4T cell - Merits • Smaller cell, only 4 transistors • HR Poly stacked above transistors - Demerits • Additional process step due to HR poly • Poor noise immunity • Large standby current • Thermal instability 76 Row Decode Transistor Level View of Core Precharge Column Decode Sense Amp 77 SRAM, Putting it all together 2n rows, 2m * k columns n + m address lines, k bits data width 78 Hierarchical Array Architecture Subblocks 1 / output bit Select 1 column / subblock Row Address Column Address Block Address Global Data Bus Control Circuitry Block Selector Global Amplifier/Driver I/O Advantages: 1. Shorter wires within blocks 2. Block address activates only 1 block => power savings 1 sense amp / subblock 79 Standalone SRAM Floorplan Example 80 Divided bit-line structure 81 SRAM Partitioning Partitioned Bitline 82 SRAM Partitioning Divided Wordline Arch 83 Partioning summary Partioning involves a trade off between area, power and speed For high speed designs, use short blocks(e.g 64 rows x 128 columns ) - Keep local bitline heights small For low power designs use tall narrow blocks (e.g 256 rows x 64 columns) - Keep the number of columns same as the access width to minimize wasted power 84 Redundancy Row Address Redundant rows Fuse : Bank Memory Array Column Decoder Row Decoder Redundant columns Column Address 85 Periphery • Decoders • Sense Amplifiers • Input/Output Buffers • Control / Timing Circuitry 86 Asynchronous & Synchronous SRAMs 87 Address Transition Detection Provides Clock for Asynch RAMs VDD A0 DELAY td A1 DELAY td AN-1 DELAY td ATD ATD ... 88 Row Decoders Collection of 2R complex logic gates organized in a regular, dense fashion (N)AND decoder 9->512 WL(0) /= !A8!A7!A6!A5!A4!A3!A2!A1!A0 … WL(511) /= A8A7A6A5A4A3A2A1A0 NOR decoder 9->512 WL(0) = !(A8+A7+A6+A5+A4+A3+A2+A1+A0) … WL(511) = !(!A8+!A7+!A6+!A5+!A4+!A3+!A2+!A1+!A0) 89 A NAND decoder using 2-input pre-decoders WL 1 WL 0 A0A1 A0 A1 A0 A1 A0A 1 A1 A 0 A0 A1 A 2A3 A2 A3 A2 A3 A2 A3 A3 A2 A2 A3 Splitting decoder into two or more logic layers produces a faster and cheaper implementation 90 Row Decoders (cont’d) A0/ A1/ A0 A1/ A0/ A1 A0 A1 A2/ A3/ A2 A3/ A2/ A3 A2 A3 R0/ R1/ R2/ … and so forth A0 A1 A2 A3 91 Dynamic Decoders Precharge devices GND GND VDD WL 3 WL 3 VDD WL 2 VDD WL 1 WL 2 WL 1 VDD WL 0 VD D A0 A0 A1 A1 Dynamic 2-to-4 NOR decoder WL 0 A0 A0 A1 A1 2-to-4 MOS dynamic NAND Decoder Propagation delay is primary concern 92 Dynamic NOR Row Decoder Vdd WL0 WL1 WL2 WL3 A0 !A0 A1 !A1 Precharge/ 93 Dynamic NAND Row Decoder WL0 WL1 WL2 WL3 !A0 A0 !A1 A1 Precharge/ Back 94 Decoders n:2n decoder consists of 2n n-input AND gates - One needed for each row of memory - Build AND from NAND or NOR gates A1 Make devices on address line minimal size Scale devices on decoder O/P to drive word lines Static CMOS Pseudo-nMOS A0 A1 word0 1 1 8 4 word1 A1 1 word2 A0 1 word3 A0 word0 word A0 1/2 4 16 A1 1 1 2 8 word word1 word2 word3 95 Decoder Layout Decoders must be pitch-matched to SRAM cell - Requires very skinny gates A3 A3 A2 A2 A1 A1 A0 A0 VDD word GND NAND gate buffer inverter 96 Large Decoders For n > 4, NAND gates become slow - Break large gates into multiple smaller gates A3 A2 A1 A0 word0 word1 word2 word3 word15 97 Predecoding - Group address bits in predecoder - Saves area - Same path effort A3 A2 A1 A0 predecoders 1 of 4 hot predecoded lines word0 word1 word2 word3 word15 98 Column Circuitry Some circuitry is required for each column - Bitline conditioning - Sense amplifiers - Column multiplexing Need hazard-free reading & writing of RAM cell Column decoder drives a MUX – the two are often merged 99 Typical Column Access 100 Pass Transistor Based Column Decoder A1 A0 2 input NOR decoder BL3 !BL3 BL2 !BL2 BL1 !BL1 BL0 !BL0 S3 S2 S1 S0 Data !Data Advantage: speed since there is only one extra transistor in the signal path Disadvantage: large transistor count 101 Tree Decoder Mux Column MUX can use pass transistors - Use nMOS only, precharge outputs One design is to use k series transistors for 2k:1 mux - No external decoder logic needed B0 B1 B2 B3 B4 B5 B6 B7 B0 B1 B2 B3 B4 B5 B6 B7 A0 A0 A1 A1 A2 A2 Y to sense amps and write circuits Y 102 Bitline Conditioning Precharge bitlines high before reads bit bit_b Equalize bitlines to minimize voltage difference when using sense amplifiers bit bit_b 103 Bit Line Precharging Static Pull-up Precharge Clocked Precharge clock BL !BL BL !BL equalization transistor - speeds up equalization of the two bit lines by allowing the capacitance and pull-up device of the nondischarged bit line to assist in precharging the discharged line 104 Sense Amplifier: Why? Bit line cap significant for large array - If each cell contributes 2fF, • for 256 cells, 512fF plus wire cap - Pull-down resistance is about 15K - RC = 7.5ns! (assuming DV = Vdd) Cell pull down Xtor resistance RCDV t Vdd Cannot easily change R, C, or Vdd, but can change DV i.e. smallest sensed voltage Cell current - Can reliably sense DV as small as <50mV 105 Sense Amplifiers DV b tp = C ---------------I cell large make D V as small as possible small Idea: Use Sense Amplifer small transition s.a. input output 106 Differential Sensing - SRAM V DD V DD BL PC VDD EQ V DD y M3 BL M4 M1 x SE M2 y x x x M5 SE WL i (b) Doubled-ended Current Mirror Amplifier V DD SRAM cell i Diff. Sense x x Amp y y D D y y x x SE (a) SRAM sensing scheme. (c) Cross-Coupled Amplifier 107 Latch-Based Sense Amplifier EQ BL BL VDD SE SE Initialized in its meta-stable point with EQ Once adequate voltage gap created, sense amp enabled with SE Positive feedback quickly forces output to a stable operating point. 108 Sense Amplifier bit’ bit word sense clk isolation transistor regenerative amplifier 109 Sense Amp Waveforms 1ns / div bit 200mV wordline bit’ wordline begin precharging bit lines 2.5V BIT BIT’ sense clk sense clk 110 Write Driver Circuits 111 Twisted Bitlines Sense amplifiers also amplify noise - Coupling noise is severe in modern processes - Try to couple equally onto bit and bit_b - Done by twisting bitlines b0 b0_b b1 b1_b b2 b2_b b3 b3_b 112 Transposed-Bitline Architecture BL’ Ccross BL SA BL BL" (a) Straightforward bitline routing. BL’ BL Ccross SA BL BL" (b) Transposed bitline architecture. 113 114 DRAM in a nutshell Based on capacitive (non-regenerative) storage Highest density (Gb/cm2) Large external memory (Gb) or embedded DRAM for image, graphics, multimedia… Needs periodic refresh -> overhead, slower 115 116 Classical DRAM Organization (square) bit (data) lines r o w d e c o d e r row address Each intersection represents a 1-T DRAM Cell RAM Cell Array word (row) select Column Selector & I/O Circuits data Column Address Row and Column Address together: - Select 1 bit a time 117 DRAM logical organization (4 Mbit) 118 DRAM physical organization (4 Mbit,x16) 119 Memory Systems address n DRAM Controller n/2 Memory Timing Controller DRAM 2^n x 1 chip w Bus Drivers Tc = Tcycle + Tcontroller + Tdriver 120 Logic Diagram of a Typical DRAM RAS_L A 9 CAS_L WE_L 256K x 8 DRAM OE_L 8 D Control Signals (RAS_L, CAS_L, WE_L, OE_L) are all active low Din and Dout are combined (D): - WE_L is asserted (Low), OE_L is disasserted (High) • D serves as the data input pin - WE_L is disasserted (High), OE_L is asserted (Low) • D is the data output pin Row and column addresses share the same pins (A) - RAS_L goes low: Pins A are latched in as row address - CAS_L goes low: Pins A are latched in as column address - RAS/CAS edge-sensitive 121 DRAM Operations Write - Charge bitline HIGH or LOW and set wordline HIGH Read - Bit line is precharged to a voltage halfway between HIGH and LOW, and then the word line is set HIGH. - Depending on the charge in the cap, the precharged bitline is pulled slightly higher or lower. - Sense Amp Detects change Explains why Cap can’t shrink Word Line C . . . Bit Line Sense Amp - Need to sufficiently drive bitline - Increase density => increase parasitic capacitance 122 DRAM Access 1M DRAM = 1024 x 1024 array of bits 10 row address bits arrive first Row Access Strobe (RAS) 1024 bits are read out 10 column address bits arrive next Subset of bits returned to CPU Column decoder Column Access Strobe (CAS) 123 DRAM Read Timing Every DRAM access begins at: - The assertion of the RAS_L - 2 ways to read: RAS_L CAS_L A early or late v. CAS WE_L 256K x 8 DRAM 9 OE_L D 8 DRAM Read Cycle Time RAS_L CAS_L A Row Address Col Address Junk Row Address Col Address Junk WE_L OE_L D High Z Junk Data Out Read Access Time Early Read Cycle: OE_L asserted before CAS_L High Z Data Out Output Enable Delay Late Read Cycle: OE_L asserted after CAS_L 124 DRAM Write Timing Every DRAM access begins at: RAS_L - The assertion of the RAS_L - 2 ways to write: early or late v. CAS A CAS_L WE_L 256K x 8 DRAM 9 OE_L D 8 DRAM WR Cycle Time RAS_L CAS_L A Row Address Col Address Junk Row Address Col Address Junk OE_L WE_L D Junk Data In WR Access Time Early Wr Cycle: WE_L asserted before CAS_L Junk Data In Junk WR Access Time Late Wr Cycle: WE_L asserted after CAS_L 125 DRAM Performance A 60 ns (tRAC) DRAM can - perform a row access only every 110 ns (tRC) - perform column access (tCAC) in 15 ns, but time between column accesses is at least 35 ns (tPC). • In practice, external address delays and turning around buses make it 40 to 50 ns These times do not include the time to drive the addresses off the microprocessor nor the memory controller overhead. - Drive parallel DRAMs, external memory controller, bus to turn around, SIMM module, pins… - 180 ns to 250 ns latency from processor to memory is good for a “60 ns” (tRAC) DRAM 126 1-Transistor Memory Cell (DRAM) row select Write: - 1. Drive bit line - 2.. Select row Read: - 1. Precharge bit line - 2.. Select row - 3. Cell and bit line share charges • bit Very small voltage changes on the bit line - 4. Sense (fancy sense amp) • Can detect changes of ~1 million electrons - 5. Write: restore the value Refresh - 1. Just do a dummy read to every cell. 127 DRAM architecture 128 Cell read: refresh is the art DV V ' BL -VBL (VSN Cs - VBL ) Cs Cb 129 Sense Amplifier 130 131 DRAM technological requirements Unlike SRAM : large Cb must be charged by small sense FF. This is slow. - Make Cb small: backbias junction cap., limit blocksize, - Backbias generator required. Triple well. Prevent threshold loss in wl pass: VG > Vccs+VTn - Requires another voltage generator on chip Requires VTnwl> Vtnlogic and thus thicker oxide than logic - Better dynamic data retention as there is less subthreshold loss. - DRAM Process unlike Logic process! Must create “large” Cs (10..30fF) in smallest possible area - (-> 2 poly-> trench cap -> stacked cap) 132 Refreshing Overhead Leakage : - junction leakage exponential with temp! - 2…5 msec @ 800 C - Decreases noise margin, destroys info All columns in a selected row are refreshed when read - Count through all row addresses once per 3 msec. (no write possible then) Overhead @ 10nsec read time for 8192*8192=64Mb: - 8192*1e-8/3e-3= 2.7% Requires additional refresh counter and I/O control 133 Dummy cells ½ Bitline ½ Bitline Vdd/2 Vdd/2 precharge precharge Wordline 134 Alternative Sensing Strategy Decreasing Cdummy Convert to differential sense - Create a reference in an identical structure Data Col BL Needs - A method of generating ½ signal swing of bit line Operation: - Dummy cell is ½ C - active wordline and dummy wordline on opposite sides of sense amp. - Amplify difference Vdd DV"1/ 0" C 1 b Cs 2 Dummy Col BL’ BL’ BL Dummy Col BL’ 1 So Small Cs small swing, Large Cb small swing Overhead of fabricating C/2 Data Col BL 135 Alternative Sensing Strategy Increasing Cbitline on Dummy side Double Bitline Data Dummy SA outputs D and D pre-charged to VDD through Q1, Q2 (Pr=1) •reference capacitor, Cdummy, connected to a pair of matched bit lines and is at 0V (Pr=0) •parasitic cap Cp2 on BL’ is ~ 2 Cp1 on BL, sets up a differential voltage LHS vs. RHS due to rise time difference SA outputs (D, D) become charged, with a small difference LHS vs. RHS Regenerative Action of Latch 136 DRAM Memory Systems address n DRAM Controller n/2 Memory Timing Controller DRAM 2^n x 1 chip w Bus Drivers Tc = Tcycle + Tcontroller + Tdriver 137 DRAM Performance Cycle Time Access Time Time DRAM (Read/Write) Cycle Time >> DRAM (Read/Write) Access Time - 2:1; why? DRAM (Read/Write) Cycle Time : - How frequent can you initiate an access? DRAM (Read/Write) Access Time: - How quickly will you get what you want once you initiate an access? DRAM Bandwidth Limitation: - Limited by Cycle Time 138 Fast Page Mode Operation Fast Page Mode DRAM Column Address N cols - N x M “SRAM” to save a row Row Address N rows After a row is read into the register DRAM - Only CAS is needed to access other M-bit blocks on that row N x M “SRAM” - RAS_L remains asserted while M-bit Output CAS_L is toggled 1st M-bit Access M bits 2nd M-bit 3rd M-bit 4th M-bit Col Address Col Address Col Address RAS_L CAS_L A Row Address Col Address 139 Page Mode DRAM Bandwidth Example Page Mode DRAM Example: - 16 bits x 1M DRAM chips (4 nos) in 64-bit module (8 MB module) - 60 ns RAS+CAS access time; 25 ns CAS access time - Latency to first access=60 ns Latency to subsequent accesses=25 ns - 110 ns read/write cycle time; 40 ns page mode access time ; 256 words (64 bits each) per page Bandwidth takes into account 110 ns first cycle, 40 ns for CAS cycles Bandwidth for one word = 8 bytes / 110 ns = 69.35 MB/sec Bandwidth for two words = 16 bytes / (110+40 ns) = 101.73 MB/sec Peak bandwidth = 8 bytes / 40 ns = 190.73 MB/sec Maximum sustained bandwidth = (256 words * 8 bytes) / ( 110ns + 256*40ns) = 188.71 MB/sec 140 4 Transistor Dynamic Memory Remove the PMOS/resistors from the SRAM memory cell Value stored on the drain of M1 and M2 But it is held there only by the capacitance on those nodes Leakage and soft-errors may destroy value 141 142 First 1T DRAM (4K Density) Texas Instruments TMS4030 introduced 1973 NMOS, 1M1P, TTL I/O 1T Cell, Open Bit Line, Differential Sense Amp Vdd=12v, Vcc=5v, Vbb=-3/-5v (Vss=0v) 143 16k DRAM (Double Poly Cell) MostekMK4116, introduced 1977 Address multiplex Page mode NMOS, 2P1M Vdd=12v, Vcc=5v, Vbb=5v (Vss=0v) Vdd-Vt precharge, dynamic sensing 144 64K DRAM Internal Vbbgenerator Boosted Wordline and Active Restore - eliminate Vtloss for ‘1’ x4 pinout 145 256K DRAM Folded bitline architecture - Common mode noise to coupling to B/Ls - Easy Y-access NMOS 2P1M - poly 1 plate - poly 2 (polycide) -gate, W/L - metal -B/L redundancy 146 1M DRAM Triple poly Planar cell, 3P1M - poly1 -gate, W/L poly2 –plate poly3 (polycide) -B/L metal -W/L strap Vdd/2 bitline reference, Vdd/2 cell plate 147 On-chip Voltage Generators Power supplies - for logic and memory precharge voltage - e.g VDD/2 for DRAM Bitline . backgate bias - reduce leakage WL select overdrive (DRAM) 148 Charge Pump Operating Principle Vin ~ +Vin +Vin Charge Phase Vin dV +Vin Discharge Phase dV Vo Vin = dV – Vin + dV +Vo Vo = 2*Vin + 2*dV ~ 2*Vin 149 Voltage Booster for WL Cf CL d Vhi Vhi dV Vcf(0) ~ Vhi VGG=Vhi + VGG ~ Vhi + Vhi CL Cf Vcf ~ Vhi 150 Backgate bias generation Use charge pump Backgate bias: Increases Vt -> reduces leakage • reduces Cj of nMOST when applied to p-well (triple well process!), 151 smaller Cj -> smaller Cb → larger readout ΔV Vdd / 2 Generation 2v 1v 1.5v 0.5v ~1v 0.5v 1 v 0.5v 1v Vtn = |Vtp|~0.5v uN = 2 uP 152 4M DRAM 3D stacked or trench cell CMOS 4P1M x16 introduced Self Refresh Build cell in vertical dimension -shrink area while maintaining 30fF cell capacitance 153 154 Stacked-Capacitor Cells Poly plate Hitachi 64Mbit DRAM Cross Section Samsung 64Mbit DRAM Cross Section 155 Evolution of DRAM cell structures 156 Buried Strap Trench Cell 157 Process Flow of BEST Cell DRAM · Array Buried N-Well · Storage Trench Formation · Node Dielectric (6nm TEQ.) · Buried Strap Formation · Shallow Trench Isolation Formation · N- and P-Well Implants · Gate Oxidation (8nm) · Gate Conductor (N+ poly / WSi) · Junction Implants · Insulator Deposition and Planarization · Contact formation · Bitline (Metal 0) formation · Via 1 / Metal 1 formation · Via 2 / Metal 2 formation 158 Shallow Trench Isolation -> Replaces LOCOS isolation -> saves area by eliminating Bird’s Beak BEST cell Dimensions Deep Trench etch with very high aspect ratio 159 256K DRAM Folded bitline architecture - Common mode noise to coupling to B/Ls - Easy Y-access NMOS 2P1M - poly 1 plate - poly 2 (polycide) -gate, W/L - metal -B/L redundancy 160 161 162 Transposed-Bitline Architecture BL’ Ccross BL SA BL BL" (a) Straightforward bitline routing. BL’ BL Ccross SA BL BL" (b) Transposed bitline architecture. 163 Cell Array and Circuits 1 Transistor 1 Capacitor Cell - Array Example Major Circuits - ・Sense amplifier - ・Dynamic Row Decoder - ・Wordline Driver Other interesting circuits ・ - Data bus amplifier ・ Voltage Regulator Reference generator Redundancy technique High speed I/O circuits 164 Standard DRAM Array Design Example 165 WL direction Column predecode (row) 64K cells (256x256) 1M cells = Global WL decode + drivers 64Kx16 Local WL Decode 166 BL direction (col) DRAM Array Example (cont’d) 2048 256x256 64 256 512K Array Nmat=16 ( 256 WL x 2048 SA) Interleaved S/A & Hierarchical Row Decoder/Driver (shared bit lines are not shown) 167 168 169 170 Standard DRAM Design Feature ・Heavy dependence on technology ・The row circuits are fully different from SRAM. ・Almost always analogue circuit design ・CAD: - Spice-like circuits simulator - Fully handcrafted layout 171