Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CpSc 810: Machine Learning
Feature Selection
Copy Right Notice
Most slides in this presentation are
adopted from slides of text book and
various sources. The Copyright belong to
the original authors. Thanks!
2
Problem Definition: Feature
Selection for Classification
Select among a set of variables the
smallest subset that maximizes
classification performance
Given: a set of predictors (“features”) V
and a target variable T
Find: minimum set F V that achieves
maximum classification performance of T
(for a given set of classifiers and
classification performance metrics)
3
Why Feature Selection is Important?
May improve performance of classification
algorithm
Classification algorithm may not scale up to
the size of the full feature set either in
sample or time
Allows us to better understand the domain
Cheaper to collect a reduced set of
predictors
Safer to collect a reduced set of predictors
4
Is Feature Selection Problem
Solved?
Immense amount of research in this area
Large variety of algorithms in existence
Major Types:
Wrappers – employ learner in heuristic process
Filters – do not employ learner in process
Other: Embedded in learner’s operation
Feature selection algorithms rarely, if ever,
provide guarantees for correctness (either
in the theoretical or practical sense)
Few algorithms scale up to the massive
datasets of today
5
Feature extraction vs. Feature selection
Feature construction:
PCA, ICA, MDS…
Sums or products of features
Normalizations
Denoising, filtering
Random features
Ad-hoc features
Feature selection
6
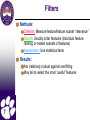
Filters
Methods:
Criterion: Measure feature/feature subset “relevance”
Search: Usually order features (individual feature
ranking or nested subsets of features)
Assessment: Use statistical tests
Results:
Are (relatively) robust against overfitting
May fail to select the most “useful” features
7
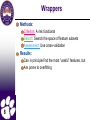
Wrappers
Methods:
Criterion: A risk functional
Search: Search the space of feature subsets
Assessment: Use cross-validation
Results:
Can in principle find the most “useful” features, but
Are prone to overfitting
8
Embedded Methods
Methods:
Criterion: A risk functional
Search: Search guided by the learning process
Assessment: Use cross-validation
Results:
Similar to wrappers, but
Less computationally expensive
Less prone to overfitting
9
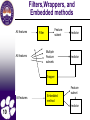
Filters,Wrappers, and
Embedded methods
All features
All features
Feature
subset
Filter
Multiple
Feature
subsets
Predictor
Predictor
Wrapper
All features
Embedded
method
Feature
subset
Predictor
10
Wrappers
Say we have predictors A, B, C and classifier
M. We want to predict T given the smallest
possible subset of {A,B,C}, while achieving
maximal performance (accuracy)
11
FEATURE SET
CLASSIFIER
PERFORMANCE
{A,B,C}
M
98%
{A,B}
M
98%
{A,C}
M
77%
{B,C}
M
56%
{A}
M
89%
{B}
M
90%
{C}
M
91%
{}
M
85%
Wrappers
The set of all subsets is the power set and its size is 2|V| .
Hence for large V we cannot do this procedure
exhaustively; instead we rely on heuristic search of the
space of all possible feature subsets.
{A,B} 98
start
{A} 89
{A,C} 77
{A,B}98
{} 85
{B} 90
{C} 91
{B,C} 56
{A,C}77
{B,C}56
12
{A,B,C}98
end
Wrappers
A common example of heuristic search is hill climbing:
keep adding features one at a time until no further
improvement can be achieved.
{A,B} 98
start
{A} 89
{A,C} 77
{A,B}98
{} 85
{B} 90
{C} 91
{B,C} 56
{A,C}77
{B,C}56
13
{A,B,C}98
end
Wrappers
A common example of heuristic search is hill
climbing: keep adding features one at a time until no
further improvement can be achieved (“forward greedy
wrapping”)
Alternatively we can start with the full set of predictors
and keep removing features one at a time until no
further improvement can be achieved (“backward
greedy wrapping”)
A third alternative is to interleave the two phases
(adding and removing) either in forward or backward
wrapping (“forward-backward wrapping”).
14
Of course other forms of search can be used; most
notably:
Exhaustive search
Genetic Algorithms
Branch-and-Bound (e.g., cost=# of features, goal is to
reach performance th or better)
Filters
In the filter approach we do not rely on running a
particular classifier and searching in the space of feature
subsets; instead we select features on the basis of
statistical properties. A classic example is univariate
associations:
FEATURE
15
ASSOCIATION WITH TARGET
{A}
89%
{B}
90%
{C}
91%
Threshold gives
suboptimal solution
Threshold gives
optimal solution
Threshold gives
suboptimal solution
Example:
Univariate Association Filtering
Order all predictors according to strength
of association with target
Choose the first k predictors and feed them
to the classifier
How to choose k?
16
Univariate Dependence Criteria
17
Univariate selection may fail
18
Guyon-Elisseeff, JMLR 2004; Springer 2006
Example:
Recursive Feature Elimination (RFE)
Filter algorithm where feature
selection uses the properties
of SVM weight vector to rank
the variables
19
Understanding the weight vector w
Recall standard SVM formulation:
w x b 0
Find w and b that minimize
2
1
subject to yi (w xi b) 1
2 w
for i = 1,…,N.
Use classifier: f ( x ) sign ( w x b)
Negative instances (y=-1) Positive instances (y=+1)
• The weight vector w contains as many elements
as
n
there are input variables in the dataset, i.e. w R .
• The magnitude of each element denotes importance of
the corresponding variable for classification task.
20
Understanding the weight vector w
x2
w (1,1)
1x1 1x2 b 0
x1
X1 and X2 are equally important
x2
w (0,1)
0 x1 1x2 b 0
x1
21
X2 is important, X1 is not
Understanding the weight vector w
w (1,0)
1x1 0 x2 b 0
x2
x1
X1 is important, X2 is not
x3
w (1,1,0)
1x1 1x2 0 x3 b 0
x2
x1
22
X1 and X2 are
equally important,
X3 is not
Understanding the weight vector w
SVM decision surface
Melanoma
Nevi
w (1,1)
1x1 1x2 b 0
Decision surface of
another classifier
Gene X2
w (1,0)
1x1 0 x2 b 0
True model
X1
Gene X1
23
• In the true model, X1 is causal and X2 is redundant
X2 Phenotype
• SVM decision surface implies that X1 and X2 are equally
important; thus it is locally causally inconsistent
• There exists a causally consistent decision surface for this example
• Causal discovery algorithms can identify that X1 is causal and X2 is
redundant
Simple SVM-based variable
selection algorithm
Algorithm:
1. Train SVM classifier using data for all
variables to estimate vector w
2. Rank each variable based on the
magnitude of the corresponding element
in vector w
3. Using the above ranking of variables,
select the smallest nested subset of
variables that achieves the best SVM
prediction accuracy.
24
Simple SVM-based variable
selection algorithm
Consider that we have 7 variables: X1, X2, X3, X4, X5, X6, X7
is: (0.1, 0.3, 0.4, 0.01, 0.9, -0.99, 0.2)
The vector w
The ranking of variables is: X6, X5, X3, X2, X7, X1, X4
Classification
accuracy
Subset of variables
X6
X5
X3
X2
X7
X1
X6
X5
X3
X2
X7
X1
X6
X5
X3
X2
X7
X6
X5
X3
X2
X6
X5
X3
X6
X5
X6
25
X4
0.920
0.920
0.919
0.852
Best classification
Classification accu
statistically indist
from the best one
0.843
0.832
0.821
Select the following variable subset: X6, X5, X3, X2 , X7
Simple SVM-based variable
selection algorithm
• SVM weights are not locally causally consistent
we may end up with a variable subset that is not
causal and not necessarily the most compact one.
• The magnitude of a variable in vector w estimates
the effect of removing that variable on the objective
function of SVM (e.g., function that we want to
minimize). However, this algorithm becomes suboptimal when considering effect of removing several
variables at a time… This pitfall is addressed in the
SVM-RFE algorithm that is presented next.
26
SVM-RFE variable selection
algorithm
27
Algorithm:
1. Initialize V to all variables in the data
2. Repeat
3.
Train SVM classifier using data for
variables in V to estimate vector w
4.
Estimate prediction accuracy of variables
in V using the above SVM classifier (e.g.,
by cross-validation)
5.
Remove from V a variable (or a subset of
variables) with the smallest magnitude of
the corresponding element in vector w
6. Until there are no variables in V
7. Select the smallest subset of variables with
the best prediction accuracy
SVM-RFE variable selection
algorithm
10,000
genes
SVM
model
Prediction
accuracy
5,000
genes
SVM
model
Important for
classification
5,000
genes
Prediction
accuracy
Discarded
Not important
for classification
28
2,500
genes
Important for
classification
2,500
genes
Dis
Not important
for classification
• Unlike simple SVM-based variable selection algorithm,
SVM-RFE estimates vector w many times to establish
ranking of the variables.
• Notice that the prediction accuracy should be
estimated at each step in an unbiased fashion, e.g. by
cross-validation.
Filters vs. Wrappers: Which is
Best?
None over all possible classification tasks!
We can only prove that a specific filter (or
wrapper) algorithm for a specific classifier
(or class of classifiers), and a specific class
of distributions yields optimal or suboptimal solutions. Unless we provide such
proofs we are operating on faith and hope…
29