Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
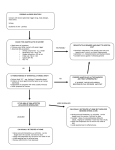
Mixed models • • • • • Various types of models and their relation Mixed effect models: simple case Mixed effect models: Estimation of parameters Tests of hypothesis R functions for mixed effect models Various forms of models and relation between them Classical statistics (Observations are random, parameters are unknown constants) LM: Assumptions 1) independent 2) Normal distribution, 3) constant unknown coefficients GLM: assumption 2) Exponential family NLM: Can be applied to all LM - Linear model GLM - Generalised linear model LMM - Linear mixed model GLMM - Generalised linear mixed model NLM - Non-linear model Repeated measures: Assumptions 1) and 3) is modified LMM: Assumptions 1) and 3) are modified GLMM: Assumption 2) Exponential family and assumptions 1) and 3) are modified Time series Maximum likelihood: All assumptions can be modified Conceptual difference Bayesian statistics: Coefficients as well as observations are random Mixed effect models: motivation In linear and generalised linear models we assumed that 1) observations are independent on each other and have the same variances 2) Distribution is normal; 3) Parameters are constant (in linear model case): y = X+; has Normal distribution N(0,2I); is a vector unknown constants. This type of model is called fixed effect models. Topic of the last lecture (Lecture 10: Generalised linear models) was about the effect of removing one of the assumptions, namely assumption that observation are from population with normal distribution. What happens if we remove assumption 1) and 3). Then problem becomes more complicated and in general we need nx(n+1)/2 number of parameters to describe covariance structure of observations. Mixed effect models deal with these type of problems. In general this type of models bring classical statistics to a new level and allows to tackle such problems as: clustered data, repeated measures, hierarchical data. Mixed effect models: Example Let us assume that we have a clinical trial. There is a drug. We want to test the effect of the different doses of the drug. We are interested only these dose levels. We randomly take n person and give to each of them one of the doses. Then the result of the experiment could be written: yij=+i+ij Where i is i-th dose, j is j-th person, is average effect of the drug and is effect of the drug specific to this particular dose, is error. Our interest lies on effects of these doses and these doses alone. This type of model is fixed effect model. Now let us assume these doses were tested in 20 different clinics. Clinics were chosen randomly. Then we can write the model: yijk=+i+bj +cij ijk i is i-th dose, j is j-th clinic, k is the k-th patient. Since doses are only those doses we are interested in they are fixed, 20 clinics have been chosen randomly form population of all clinics they are random. We can not guarantee that effect of clinic and effect of dose is additive that is why we add c - interaction between clinics and doses. Since clinics are random then c must be random also. This is an example of mixed effect model. To solve the problem we need to find estimations overall effect (), effects of dose () and distribution of clinics (distribution of b and c). Mixed or random It is often a challenging problem to decide if we should use fixed or mixed effect models. For example in drug and clinics case if we are going to use these drugs in all clinics (in case of successful results) then we should consider clinics as random but if drugs are very expensive and specialised and they are going to be used only in these clinics then we cannot consider these clinics as random. Then they should be considered as a fixed. Sometimes choice between random and fixed could be dictated by the amount of the data, information we have. If we have enough data to make inference about the population then we can use mixed effect models. If we do not have enough data then we can make inference only about different levels (e.g. doses of drugs, different clincis) of the variable of interest. Mixed effect models: Simple model Let us consider model: yij=+ai+xj+ij M is overall intercept constant coefficient on x (describes dependence of y on x), a is random intercept specific to i and is random error. Let us assume that distribution of is N(0, ) and the distribution of all ai-s are identically and independently distributed (i.i.d.) random variables with N(0, a). Now we can write the distribution of y: E(yij) = +xi Var(yij) = a2+2 Cov(yij,yij’) = a2 Cov(yi’j,yij’) =0 for i’i We see that only two parameters are sufficient to describe the whole covariance structure of the observations. Now we can write multivariate normal distribution for joint probability distribution of the observations. Mixed effect models: Simple model If we use notation V as variance of the observation then we can write of the distribution of the observation and therefore for likelihood: L(y|m,b,, a) = N(+x,V) Now the problem is to estimate parameters by maximising this likelihood function. The problem is usually solved iteratively: estimate parameters involved in mean assuming V constant and then estimate parameters involved in V. Mixed effect models: Tests of hypothesis There are number of hypothesis that can be tested: 1) hypothesis involving parameters included in the mean - and ; 2) hypothesis about parameters included in the covariance - V part: e.g. a=0. For these tests likelihood ratio test is used. In this particular case, both tests, after some manipulations come to F statistic. General linear mixed effect models General mixed effect models can be written: y=X+Zu+ Where u is random variable with distribution N(0,D), has distribution N(0, ), a is fixed. Then we can write: E(y)=X V(y)=Z DZT+2 I So if the distribution is the normal distribution then we can build joint probability distribution of all observations and therefore the likelihood function. Note that fixed effects are involved only in mean values (just like in linear model), random effect modify the covariance matrix of the observations, it is no longer diagonal and it means that observations are dependent on each other. Above equations are general form of the linear mixed effect models. Simpler forms of linear mixed effect models If the structure of the data is known then it is possible to simplify covariance of the above described model. For example if we have two group of variables that are not dependent on each other. For example: let us assume we want to analyse performances of pupils in maths. We take n schools, in each school k classes and in each class l boys and m girls. In the model we would include one constant parameter for boys and one for girls (since these are only two options), then we would take random effect of schools (we are interested in all schools) and classes in these schools (we are interested in all classes in this school). Now it is reasonable to assume that there is no correlation between classes and schools. If class does not belong to the school then I do not know where correlation could come from, if class in the school then since school is considered as a random effect then correlation between classes and this school would be absorbed by the covariance of the school. So we have variance-covariance of schools and that of classes. Thinking about the system considerable simplifies the model we want to build. Predicting random effects In mixed models we estimate parameters of fixed effects and distribution for random effects. Sometimes it is interesting to predict random effects. The expressions for fixed effect coefficients and for so called best linear unbiased prediction (BLUP) is est=(XT V-1X)-1XTV-1y upredict=DZTV-1(y-Xest)= DZTV-1 (I- (XT V-1X)-1XTV-1)y var(upredict)=DZTV-1(I- (XT V-1X)-1XTV-1)ZD Using these facts one can design tests of hypotheses, confidence intervals about u. R commands for linear mixed models Commands for linear mixed models are in the library nlme: library(nlme) data(Orthodont) lm1 = lme(distance~age+Sex,data=Orthodont) lm1 summary(lm1) References 1) 2) Demidenko E (2004) Mixed Models: Theory and applications McCullagh CE, Searle SR, (2001) Generalized, linear and mixed models Exercise Take the data set esoph form and analyse using generalised linear model. Hints how to analyse this data set is at the end of the help page for this data set: ?esoph