Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Information privacy law wikipedia , lookup
Expense and cost recovery system (ECRS) wikipedia , lookup
Predictive analytics wikipedia , lookup
Clusterpoint wikipedia , lookup
Business intelligence wikipedia , lookup
Open data in the United Kingdom wikipedia , lookup
Rainbow table wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Data vault modeling wikipedia , lookup
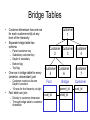
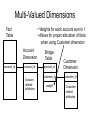
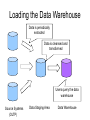
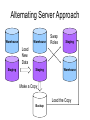
CS 345: Topics in Data Warehousing Thursday, October 14, 2004 Review of Tuesday’s Class • Customer Relationship Management (CRM) • Dimension-focused queries – Drill-across – Conformed dimensions • Customer dimension – Behavioral attributes – Auxiliary tables • Techniques for very large dimensions – Outriggers – Mini-dimensions Outline of Today’s Class • Bridge tables – Hierarchies – Multi-Valued Dimensions • Extraction-Transformation-Load – Data staging area vs. data warehouse – Assigning surrogate keys – Detecting changed rows – Detecting duplicate dimension rows More Outriggers / Mini-Dims • Lots of information about some customers, little info about others – A common scenario • Example: web site browsing behavior – Web User dimension (= Customer dimension) – Unregistered users • User identity tracked over time via cookies • Limited information available – First active date, Latest active date, Behavioral attributes – Possibly ZIP code through IP lookup – Registered users • Lots of data provided by user during registration – Many more unregistered users than registered users – Most attribute values are unknown for unregistered users • Split registered user attributes into a separate table – Either an outrigger or a mini-dimension – For unregistered users, point to special “Unregistered” row Handling Hierarchies • Hierarchical relationships among dimension attributes are common • There are various ways to handle hierarchies – Store all levels of hierarchy in denormalized dimension table • The preferred solution in almost all cases! – Create “snowflake” schema with hierarchy captured in separate outrigger table • Only recommended for huge dimension tables • Storage savings have negligible impact in most cases • What about variable-depth hierarchies? – Examples: • Corporate organization chart • Parts composed of subparts – Previous two solutions assumed fixed-depth – Creating recursive foreign key to parent row is a possibility • • • • Employee dimension has “boss” attribute which is FK to Employee The CEO has NULL value for boss This approach is not recommended Cannot be queried effectively using SQL – Alternative approach: bridge table Bridge Tables • • Customer dimension has one row for each customer entity at any level of the hierarchy Separate bridge table has schema: – – – – – • Parent customer key Subsidiary customer key Depth of subsidiary Bottom flag Top flag One row in bridge table for every (ancestor, descendant) pair – Customer counts as its own Depth-0 ancestor – 16 rows for the hierarchy at right • Fact table can join: – Directly to customer dimension – Through bridge table to customer dimension Customer 1 Customer Customer 2 3 Customer 5 Fact Customer 6 Customer 7 Bridge Customer parent_id cust_id Customer 4 child_id cust_id Bridge Table Example parent_id child_id depth top_flag bottom_flag 1 1 0 Y N 1 2 1 Y N 2 2 0 N N 1 3 1 Y Y 3 3 0 N Y 1 4 1 Y N 4 4 0 N N 1 5 2 Y Y 2 5 1 N Y 5 5 0 N Y 1 6 2 Y Y 2 6 1 N Y … … … … … Using Bridge Tables in Queries • Two join directions – Navigate up the hierarchy • Fact joins to subsidiary customer key • Dimension joins to parent customer key – Navigate down the hierarchy • Fact joins to parent customer key • Dimension joins to subsidiary customer key • Safe uses of the bridge table: – Filter on customer dimension restricts query to a single customer • Use bridge table to combine data about that customer’s subsidiaries or parents – Filter on bridge table restricts query to a single level • Require Top Flag = Y • Require Depth = 1 – For immediate parent / child organizations • Require (Depth = 1 OR (Depth < 1 AND Top Flag = Y)) – Generalizes the previous example to properly treat top-level customers • Other uses of the bridge table risk over-counting – Bridge table is many-to-many between fact and dimension Restricting to One Customer parent_id child_id depth top_flag bottom_flag 1 1 0 Y N 1 2 1 Y N 2 2 0 N N 1 3 1 Y Y 3 3 0 N Y 1 4 1 Y N 4 4 0 N N 1 5 2 Y Y 2 5 1 N Y 5 5 0 N Y 1 6 2 Y Y 2 6 1 N Y … … … … … Restricting to One Depth parent_id child_id depth top_flag bottom_flag 1 1 0 Y N 1 2 1 Y N 2 2 0 N N 1 3 1 Y Y 3 3 0 N Y 1 4 1 Y N 4 4 0 N N 1 5 2 Y Y 2 5 1 N Y 5 5 0 N Y 1 6 2 Y Y 2 6 1 N Y … … … … … Multi-Valued Dimensions • Occasionally a dimension takes on a variable number of multiple values – Example: Bank accounts may be owned by one, two, or even more customers (individual vs. joint accounts) • Can be modeled using a bridge table • Bank transaction fact table – Grain: one row per transaction – Dimensions: Date, Branch, TransType, Account, Customer – Including Customer dimension would violate the grain Multi-Valued Dimensions • Weights for each account sum to 1 • Allows for proper allocation of facts when using Customer dimension Fact Table account_id Account Dimension Bridge Table account_id account_id Customer Dimension customer_id customer_id Accountrelated attributes weight Customerrelated attributes Weighted Report vs. Impact Report • Two formulations for customer queries • Weighted report – Multiply all facts by weight before aggregating – SUM(DollarAmt * weight) – Subtotals and totals are meaningful • Impact report – – – – – Don’t use the weight column SUM(DollarAmt) Some facts are double-counted in totals Each customer is fully credited for his/her activity Most useful when grouping by customer Loading the Data Warehouse Data is periodically extracted Data is cleansed and transformed Users query the data warehouse Source Systems (OLTP) Data Staging Area Data Warehouse Staging Area vs. Warehouse • Data warehouse – Cleansed, transformed data – User-friendly logical design – Optimized physical design • Indexes, Pre-computed aggregates • Staging area – Intermediate representations of data – “Work area” for data transformations • Same server or different? • Separate staging server and warehouse server – Run extraction in parallel with queries • Staging area and warehouse both part of same database – Less copying of data is required Alternating Server Approach Warehouse Warehouse Swap Roles Staging Load New Data Staging Staging Warehouse Make a Copy Load the Copy Backup Surrogate Key Assignment • Maintain natural key → surrogate key mapping – Separate mapping for each dimension table – Can be stored in a relational database table • One or more columns for natural key • One column for surrogate key • Need a separate mapping table for each data source – Unless data sources already use unified natural key scheme • Handling multiple dimension rows that preserve history – 1st approach: Mapping table contains surrogate key for most current dimension row – 2nd approach: Mapping table lists all surrogate keys that were ever used for each natural key • Add additional columns to mapping table: – Begin_date, End_date, Is_current_flag • “Late-arriving” fact rows can use historically correct key • Necessary for hybrid slowly changing dimension schemes Detecting Changed Rows • Some source systems make things easy – All changes timestamped → nothing to do! – Usually the case for fact tables • Except for Accumulating Snapshot facts – For each source system, record latest timestamp covered during previous extraction cycle • Some source systems just hold snapshot – Need to detect new vs. changed vs. unchanged rows – New vs. old rows: Use surrogate key mapping table – Detecting changed vs. unchanged rows • Approach 1: Use a hash function – Faster but less reliable • Approach 2: Column-by-column comparison – Slower but more reliable Handling Changed Rows • Using a hash function – – – – Compute a small summary of the data row Store previous hash value in mapping table Compare with hash value of current attribute values If they’re equal, assume no change • Hash table collisions are possible – Cyclic redundancy checksum (CRC) • Commonly used hash function family • No collisions under local changes and byte reorderings • Determine which attributes have changed – Requires column-by-column comparison – Store untransformed attribute values in mapping table – Choose slowly changing dimension approach based on changed attributes Dimension Loading Workflow Natural key in mapping table? Yes No Insert row in mapping table Insert row in dimension table Has row changed? No Do nothing Yes Which SCD type? Type 2 Type 1 Update row in mapping table Update row in mapping table Update row in dimension table/ Mark aggregates Insert row in dimension table Duplicates from Multiple Sources • Information about the same logical entity found in multiple source systems • Combine info into single dimension row • Problems: – Determine which rows reference same entity • Sometimes it’s hard to tell! • Referred to as the merge/purge problem • Active area of research – Resolve conflicts between source systems • Matching records with different values for the same field • Approach #1: Believe the “more reliable” system • Approach #2: Include both values as separate attributes Merge/Purge • How can we determine that these are the same person? FName LName Address City Zip B Babcock 3135 Campus Dr #112 San Mateo 94403 Brian Bobcock 3135 Compass Drive Apt 112 San Mateo 94403-3205 • Fuzzy matching based on textual similarity • Transformation rules • Comparison to known good source – NCOA: National Change Of Address database • Related application: Householding – Can we determine when two individuals/accounts belong to the same household? – Send one mailing instead of two Next Week: Query Processing • We’re done with logical database design • Next topic: how can the database answer queries efficiently? • No textbook from here on – Optional readings for each topic will be posted on the course web page • Mostly research papers • Some readings from books on reserve in Math/CS library • Tuesday’s topic: Query processing basics – Will be review if you’ve taken CS 245 – Haven’t taken CS 245 → may want to read DSCB Chapter 15.1-15.5, 15.8