Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
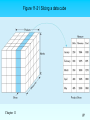
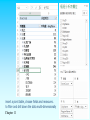
Chapter 11: Data Warehousing 註 : 於11版為Chapter 10 楊立偉教授 台灣大學工管系 2015 Fall 1 Definition Data Warehouse: A subject-oriented, integrated, time-variant, nonupdatable collection of data used in support of management decision-making processes Subject-oriented: e.g. customers, patients, students, products Integrated: Consistent naming conventions, formats, encoding structures; from multiple data sources Time-variant: Can study trends and changes Non-updatable: Read-only, periodically refreshed Data Mart: A data warehouse that is limited in scope Ex. Corporate (Data Warehouse) v.s. Department (Data Mart) Chapter 11 2 History Leading to Data Warehousing Improvement in database technologies, especially relational DBMSs 資料庫技術的進步 Advances in computer hardware, including mass storage and parallel architectures 配合大量儲存與平行運算架構的進步 Emergence of end-user computing with powerful interfaces and tools 使用者自行操作 Advances in middleware, enabling heterogeneous database connectivity 相互整合 Recognition of difference between operational and informational systems 體認到日常作業與資訊分析是不同的 Chapter 11 3 Need for Data Warehousing Integrated, company-wide view of high-quality information (from disparate databases) 整合各種資訊 Separation of operational and informational systems and data (for improved performance) 獨立於日常作業外 Table 11-1 – Comparison of Operational and Informational Systems Chapter 11 4 Issues with Company-Wide View Inconsistent key structures 不一致的PK Synonyms 同義字問題 Free-form vs. structured fields Inconsistent data values 資料值不一致 Missing data 缺值問題 See figure 11-1 for example Chapter 11 5 Figure 11-1 Examples of heterogeneous data Chapter 11 6 Organizational Trends Motivating Data Warehouses No single system of records Multiple systems not synchronized Organizational need to analyze activities in a balanced way 從組織角度, 看資料需要整體來看 for Customer relationship management (CRM) and Supplier relationship management (SRM) Chapter 11 7 Data Warehouse Architectures Independent Data Mart Dependent Data Mart and Operational Data Store Logical Data Mart and Real-Time Data Warehouse Three-Layer architecture All involve some form of extraction, transformation and loading (ETL) Chapter 11 8 Figure 11-2 Independent data mart data warehousing architecture Data marts: Mini-warehouses, limited in scope L T E Separate ETL for each independent data mart Chapter 11 Data access complexity due to multiple data marts 9 Table 11-2 – Data Warehouse Versus Data Mart Source: adapted from Strange (1997). Chapter 11 10 Figure 11-6 Example of DBMS log entry Data Characteristics Status vs. Event Data Status Event = a database action (create/update/delete) that results from a transaction Status Chapter 11 11 Other Data Warehouse Changes 加新欄位 New descriptive attributes New business activity attributes New classes of descriptive attributes Descriptive attributes become more refined 加描述資料 Descriptive data are related to one another 加新資料源 New source of data Chapter 11 12 Derived Data 加入衍生性資料 Objectives 與一般資料庫設計準則略有不同 Ease of use for decision support applications Fast response to predefined user queries Customized data for particular target audiences Ad-hoc query support Data mining capabilities Characteristics Detailed (mostly periodic) data Aggregate (for summary) Distributed (to departmental servers) Most common data model = star schema (also called “dimensional model”) Chapter 11 13 Figure 11-9 Components of a star schema Fact tables contain factual or quantitative data 1:N relationship between dimension tables and fact tables Dimension tables are denormalized to maximize performance Dimension tables contain descriptions about the subjects of the business Excellent for ad-hoc queries, but bad for online transaction processing Chapter 11 →日常作業(有寫入或修改)還是要用正規化後的表格 14 Figure 11-10 Star schema example Fact table provides statistics for sales broken down by product, period and store dimensions Chapter 11 15 Figure 11-11 Star schema with sample data Chapter 11 16 Issues Regarding Star Schema (1) Dimension table keys must be surrogate (nonintelligent and non-business related), because: Keys may change over time Length/format consistency 資料的精細度 Granularity of Fact Table–what level of detail do you want? Transactional grain–finest level Aggregated grain–more summarized Finer grains better market basket analysis capability Finer grain more dimension tables, more rows in fact table Chapter 11 17 Issues Regarding Star Schema (2) 資料期間 Duration of the database–how much history should be kept? Natural duration–13 months or 5 quarters Financial institutions may need longer duration Older data is more difficult to source and cleanse Chapter 11 18 Size of Fact Table Depends on the number of dimensions and the grain of the fact table Number of rows = product of number of possible values for each dimension associated with the fact table Example: Assume the following for the next Figure: Total rows calculated as follows (assuming only half the products record sales for a given month): Chapter 11 19 (new) Figure 9-12 Modeling dates Fact tables contain time-period data Date dimensions are important Chapter 11 20 Slowly Changing Dimensions (SCD) How to maintain knowledge of the past Kimble’s approaches: Type 1: just replace old data with new (lose historical data) Type 2: for each changing attribute, create a current value field and several old-valued fields (multivalued) Type 3: create a new dimension table row each time the dimension object changes, with all dimension characteristics at the time of change. Most common approach Chapter 11 21 (new) Figure 9-18 Example of Type 2 SCD Customer dimension table The dimension table contains several records for the same customer. The specific customer record to use depends on the key and the date of the fact, which should be between start and end dates of the SCD customer record. Chapter 11 22 (new) Figure 9-19 Dimension segmentation For rapidly changing attributes (hot attributes), Type 2 SCD approach creates too many rows and too much redundant data. Use segmentation instead. Chapter 11 23 10 Essential Rules for Dimensional Modeling Use atomic facts Create single-process fact tables Include a date dimension for each fact table Enforce consistent grain Disallow null keys in fact tables Chapter 11 Honor hierarchies Decode dimension tables Use surrogate keys Conform dimensions Balance requirements with actual data 24 Other Data Warehouse Advances Columnar databases for Big Data (huge volume, often unstructured) Columnar databases optimize storage for summary data of few columns (different need than OLTP) Data compression NoSQL “Not only SQL” Deals with unstructured data Hadoop HBase, Cassandra, MongoDB Chapter 11 25 Online Analytical Processing (OLAP) Tools The use of a set of graphical tools that provides users with multidimensional views of their data and allows them to analyze the data using simple windowing techniques Relational OLAP (ROLAP) Multidimensional OLAP (MOLAP) Traditional relational representation Cube structure OLAP Operations Cube slicing–come up with 2-D view of data Drill-down–going from summary to more detailed views Chapter 11 26 Figure 11-21 Slicing a data cube Chapter 11 27 Summary report Figure 11-22 Example of drill-down Starting with summary data, users can obtain details for particular cells Chapter 11 Drill-down with color added 28 Data Mining and Visualization Knowledge discovery using a blend of statistical, AI, and computer graphics techniques Goals: Techniques Explain observed events or conditions Confirm hypotheses Explore data for new or unexpected relationships Statistical regression Decision tree Clustering Association rule Sequence association … and so on. Data visualization–representing data in graphical/multimedia formats for analysis Chapter 11 29 Online Analytical Processing (OLAP) Tools Exercise : use MS Query to connect DBMS, and analyze with MS Excel (Power) Pivot connect via ODBC, and query by SQL or Wizard (to choose tables and fields) Chapter 11 30 connect via ODBC, and query by SQL or Wizard (to join tables) Chapter 11 31 Chapter 11 import the data into a sheet in MS Excel 32 insert a pivot table, choose fields and measures. to filter and drill down the data multi-dimensionally Chapter 11 33