Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Functional Database Model wikipedia , lookup
Concurrency control wikipedia , lookup
Oracle Database wikipedia , lookup
Microsoft SQL Server wikipedia , lookup
Relational model wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Versant Object Database wikipedia , lookup
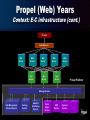
Toto, We’re Not in Kansas Anymore… On Transitioning from Research to the Real World Mike Carey Fellow, Platform Engineering [email protected] Today’s Talk • Background information • Lessons from the "Road to Propel" The UW-Madison years The IBM Almaden years The Propel (web) years • Database research in the new millennium Maturity brings its own challenges Research opportunities in e-commerce Some operational recommendations Part One: Background information Background Info • UW-Madison CS Professor (1983-1995) Concurrency control algorithms Query processing performance Main memory databases Extensible database systems (Exodus) Real-time database systems Client-server O-O database systems (Shore) Online algorithms, DBMS performance Background Info (cont.) • IBM Almaden Research Staff Member and Manager (1995-2000) Heterogeneous database systems (Garlic) Object middleware (Component Broker) Object-relational databases (DB2 UDB) • Propel Platform Engineering Fellow (2000-?) Scalable e-commerce infrastructure software Part Two: Lessons from the "Road to Propel" UW-Madison Years Lesson #1: Awareness is key • Be “plugged in” to current technologies & issues Hardware and OS characteristics CPU, memory, disk, and network performance Path lengths (e.g., TCP/IP messages) DBMS software characteristics DBMS internal components Layers/calls: SQL, records, pages, … Interactions, e.g., concurrency & recovery Application characteristics “Typical” workload characteristics What systems can or cannot know (when/how) UW-Madison Years Lesson #2: Students are the product • Having industrial impact is a laudable goal, but It’s hard (in general) to be fully plugged in Details of systems and workloads The algorithms may not be the hard part More about this shortly • Students are our biggest accomplishment Well-trained students are incredibly valuable Systems sense; ability to think, learn, adapt • I’m extremely proud of my former students! That’s what I miss the most in industry UW-Madison Years The wake-up call: A house of cards? • [ACL85]: Blindly following colleagues Ten years later, some papers still using the same hardware and software parameters • RTDBS: The blind following the blind? We basically stated and then solved these research problems ourselves • SIGMOD-94: The SIGMOD chair’s lunchtime analysis of SIGMOD paper production Not clear to me that “most SIGMOD papers in the last ten years” was such a good thing The First Transition From UW-Madison to IBM Almaden • Intellectual reasons Weary of inventing and then solving problems Wanted access to real problems and systems Also just needed a change after 12 years • IBM Almaden reasons Terrific environment & colleagues for DB research “Development from the safety of a research lab” • Personal reasons Wanted to “have a life” again outside work Wanted to live in the Bay area (Silicon Valley) IBM Almaden Years Context: Extending DB2 UDB • From 1996-2000, I worked on adding object extensions to SQL and DB2 UDB (V5.2-V7.1) Object-relational data model extensions Types, OIDs, references, subtables, object views Corresponding query language extensions Substitutability, path expressions, constraints and triggers, type predicates, sub-table access rules System extensions Storage & query processing for all of the above • DB2 UDB work is geographically distributed IBM Toronto, Santa Teresa, and Almaden labs IBM Almaden Years Lesson #1: Products are hard to build • Products are very different than prototypes Someone else wrote the first 1M+ lines of code System has many nooks and crannies No one person understands the whole thing 100 or so people are working on it with you You have to do the other 80-90% of the work Testing, code reviews, testing, docs, testing, … System catalogs: no big deal, right…? • The engine is just one aspect of a product Import/export, bulk load, control center, visual explain, query tools, design tools, replication, … IBM Almaden Years Lesson #1: Products are hard (cont.) • It’s difficult to make some kinds of changes Customers already have terabytes of data Data migration is a no-no (at least at IBM ) Catalog migration is a pain and a time sink • It’s not just your own product that’s affected 3rd-party vendors may also be a factor Ex. 1: Physical load utilities (table hierarchies) Ex. 2: Logical & physical database design tools Market share & standards come into play here IBM Almaden Years Lesson #2: Adding to a language is hard • SQL is a 25-year old language that was never intended to do everything we want it to today World was simple tables, basic retrievals Various assumptions made for “convenience” Ex. 1: Sub-queries – scalar- or table-valued? Ex. 2: Nulls – inconsistent (e.g., where vs. max) • SQL changes must be monotonic in nature Can’t change meaning of existing queries (!) Extensions must all peacefully co-exist Language is getting “full” (> 1000 pages) IBM Almaden Years Lesson #2: Adding is hard (cont.) • “Cool new SQL features” are a double-edged sword Can add real value for advanced applications Consider OLAP, O-R, and temporal extensions “Different” or “proprietary” = “bad”? To 3rd-party vendors, also to nervous customers And, tools may hide them anyway Query builders, EJB programming model, … • SQL standardization is an interesting world Serious extensions must someday fly with ANSI & ISO SQL standard is in some ways a corporate battleground Vendors only want the extensions on their radar screen IBM Almaden Years Lesson #3: Listen to users’ needs • So many features, so little time…! Potential users help you prioritize your work Ex: Sub-table triggers & constraints in DB2 They also help you make “safe” initial decisions Ex: Internal storage for DB2 table hierarchies • Potential users can help you see things you might otherwise miss (at least initially) Ex 1: Advantages of DB2 user-defined OIDs Customers already “simulate” objects today Access to system-generated OID values? Object caching and efficient write-back Ex 2: DB2 object view functionality Virtual table hierarchies, same authorization model The Second Transition From IBM Almaden to Propel • Some triggering events Working on XML middleware layer for DB2 UDB After spending nearly 20 years “under the hood” Almaden management discussions: connecting to Valley Personal belief that this was a unique period for CS Call (out of the blue) from Steve Kirsch, CEO • Given a 4-year paid scholarship to “e-school” Chance to learn about Using database system technology Web and e-commerce applications The startup company experience Excellent senior team to learn from at Propel Unemployment risk “low” () in Silicon Valley Propel (Web) Years Context: E-commerce infrastructure • Propel is developing two software products E-Commerce Suite “Amazon-in-a-box” product Distributed Services Platform Infrastructure product for the above (and other data-centric, mission-critical internet applications) • Platform = Scalable 24x7 “e-commerce OS” Online data management, caching, search, messaging, live deployment, monitoring, … Propel (Web) Years Context: E-C infrastructure (cont.) ... Firewall Load Balancer Web Server Web Server Web Server App Server Web Server App Server Web Server App Server ... … … … Order Mgmt Service ERP Service Payment Service ... Propel Platform Message Service … Data Management & Search Service … Caching Service … Admin & Monitoring Service … … Propel (Web) Years Lesson #1: Standards vs. innovation • What a marketing person will likely tell you after asking a customer for their input Customers want standards-based solutions “We want DB access via SQL and JDBC” “We want our programmers to use EJBs (J2EE)” “We want to use JSPs for our dynamic pages” I.e., a typical customer dictionary entry says Proprietary: see “bad” • This poses obvious challenges for innovation! Luckily… XML is also considered “standards-based” Performance, ease of use are still compelling in web-land Propel (Web) Years Lesson #2: Oracle is a de facto standard • Talking to dot-com’s with Oracle DBAs is an interesting experience for the academic-minded Academic point of view Whatever; it’s just a database system… Oracle DBA point of view Do my Oracle utilities work with your solution? Do my Oracle sequences work with your solution? You mean it’s not Oracle? (said with a whine ) • Again, this poses obvious challenges for innovation (not to mention other DB vendors!) Luckily… Saying “Oracle inside” seems to help Oracle is not a cheap, perfect, or limitless solution Propel (Web) Years Lesson #3: VCs, dot-coms, and ASPs • Oracle+Sun+Solaris are to web sites what IBM was to corporate IS departments 15+ years ago Some VC firms prescribe(d) them to dot-coms Some IS departments pre-approve (just) them They are a favorite managed stack for ASPs • Thus, today’s “technology brakes” include Corporate and VC comfort zones ASP system management expertise Developer and DBA skill set availability Part Three: Database research in the new millennium The DB Field Has Matured Bringing a new set of challenges • SQL DB systems are becoming a commodity ISVs produce DBMS-independent packages Ex: ERP systems (SAP, Peoplesoft, Baan, …) SQL + ODBC/JDBC is just a “given” New features face a huge uphill battle Witness the rate of object-relational adoption Hopefully SQL99 will help, but….? A SQL DBMS has truly become a component Transactional storage for ERP On-line data repository for e-commerce I.e., just a place to put your data • So where does that leave our community…? The DB Field Has Matured Bringing new challenges (cont.) • Interesting questions remain! For example: A good component is easy to manage DB systems have way too many knobs They’re virtually impossible to hide as a result A good component plugs in well with others Better, faster interfaces would be nice Cache interaction hooks would be nice Workflow hooks would be nice (Your application hooks go here) XML appears poised for interoperation success W3C XML Schema, Query, & Protocol efforts Our community should keep playing a big role The DB Field Has Matured Bringing new challenges (cont.) • Interesting questions remain (cont.) Major applications are worth studying Ex: Kemper, Kossman, et al SAP study Sources of “typical” workload info, database characteristics, and feature use (or disuse) info Bottom line from a component perspective We need to understand how our technologies are being utilized (or not) and respond accordingly - Ex. 1: Queries with parameter markers - Ex. 2: SQL’s approach to authorization - Ex. 3: Actual usage-driven interoperation hooks And, of course, we must continue to innovate! Somehow…?!? E-Commerce DB Research A Propel Perspective • The Propel Distributed Services Platform Scalable, 24x7 e-business infrastructure Array of inexpensive Sun or Intel boxes Exploitation of low main memory cost High-performance and highly available Data management and search capabilities Transparent data replication & partitioning Caching of page fragments, objects, and data Scalable messaging & queuing infrastructure Built from best-of-breed components XML-enabled (for the future of e-business) Unified administration and on-line deployment E-Commerce DB Research Problem #1: Caching • What to cache and where to cache it? Fragments of dynamic HTML pages Personalization ruins basic page caching Commonly used fragments assured, though XML objects used to create HTML fragments If applicable, probably less bulky Java objects materialized on app servers Avoids database re-access cost Issues: load balancing, memory duplication Database objects accessed from DB server(s) Lowers database access cost Where – app servers, DB server(s), or both? E-Commerce DB Research Problem #1: Caching (cont.) • How to keep caches consistent Multiple web servers and app servers DB rows -> Java objects -> XML -> HTML How to uniquely identify objects? How to keep track of what’s where? How to keep track of data dependencies? How/when to propagate updates? How to maintain consistency? In fact, how to define consistency…? What about queries and query results? • And, just to up the ante a bit further Want all this to work across continents…! E-Commerce DB Research Problem #2: Consistency & transactions • Not all e-business data is equally “valuable” Want to trade off reliability & performance Products: hot, may be read-only once deployed Shopping carts: read/write, “best effort” durability Orders: also read/write, require full durability • Similar considerations arise w.r.t. consistency Would like well-defined choices available Auctions: okay to bid using slightly outdated info Orders: real-time inventory requires transactions • Need good, architecturally appropriate solutions Caching, replication, failover, smart load balancing, … E-Commerce DB Research Problem #3: Queries and search • W3C’s XML Schema recommendation How to store richly typed XML data? Sparse/variant data, repeating elements, subtyping, text, … Would like to map it into (object-?) relational databases • W3C’s XML Query recommendation How to process XML queries efficiently? SQL-appropriate processing model Pushdown and other optimizations How to handle search-oriented queries? Want transaction-consistent text indexing Also want relevance ranking and various IR “goodies” E-Commerce DB Research Problem #4: Content management • E-business web sites are rich in content HTML fragments (e.g., logos and other goodies) Images (e.g., pictures of products) Text (e.g., descriptions of products) Database data (e.g., product attributes, pricing) JSP pages (e.g., a product page) Personalization rules (i.e., what to show me) Business logic (i.e., Java code) Data -> object mappings (e.g., Java classes) And the list goes on… E-Commerce DB Research Problem #4: Content mgmt. (cont.) • This poses a number of problems Versioning of file-based artifacts Not unlike CAD or document versioning Multiple editors working on the content base Several companies do this (e.g., Interwoven) Versioning of DB-based artifacts Not clear how to handle & integrate this part No winning solutions out there yet (that I know of) Versioning of code-based artifacts How to keep all this stuff mutually consistent? And, how to deploy online in a 24x7 world…? E-Commerce DB Research Problem #5: The sun never sets anymore • The web brings a clear need for 24x7 solutions Asynchronous replication techniques Online schema evolution (w/replication) Online data loading and deployment Online management of rolling history data • Design for administration/monitoring is also key Online backup/restore Failure & performance monitoring Would like system to be self-tuning & self-scaling Reassign boxes between services as needed Even give and take boxes from ASP infrastructure The Propel Platform We’re attacking all of these issues • Programming model Objects with (truly!) universal OIDs Java classes, derived from XML Schema objects • Caching Multilevel cache hierarchy (w/partitioning) Mini-caches, global cache, MM-DBMS, DB-DBMS • Consistency and transactions Can trade off ACID-ity vs. performance • Queries and search XML-influenced query language, integrated search Transparency for cached, partitioned, & replicated data The Propel Platform We’re attacking all of these issues (cont.) • Platform messaging support Clustered IPC for Platform components Load balancing & failover System monitoring Persistent queues as database objects Think “active tables” (enqueue/dequeue, queries) Good foundation for transactional workflows • Content management Currently focused on deployment problems Partnering for content management today • System monitoring and administration Separate software stack with agents everywhere JSP-based console to oversee & integrate activities Conclusion Lessons from the "Road to Propel" • UW-Madison lessons: Know what matters! Awareness is key Students are the product • IBM Almaden lessons: What’s really hard? Products are hard to build Adding to a language is hard Listen to users’ needs • Propel lessons: Commoditization brings roadblocks. Standards vs. innovation Oracle is a de facto standard Dot-coms, VCs, and ASPs Conclusion DB research in the new millennium • SQL databases are becoming commodity parts ISVs strive for DBMS vendor-independence This makes (visible) innovation hard Lots of interesting research questions, though Component hooks, usage scenarios, XML, … • E-commerce problems are ripe for the picking Examples that have arisen at Propel include Caching, transactions & consistency Queries and search Content management Online everything for a 24x7 world Conclusion Some operational recommendations • Understand the real problems out there Industrial friends can be very helpful Your students will benefit tremendously So will the companies who hire them • Recognize that commoditization is happening Consider working within the constraints that it brings Many important open problems remain E-commerce is one fun/interesting example here • Also keep in mind what really matters It’s actually not any of this stuff, in the end…!