Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
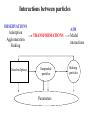
Data Mining with Artificial Evolution. Helen Johnson Anna Kwiatkowska David Sweeney Panagiotis Tzionas Problem leader: Michele Sebag Team leader: Michael Herdy Data mining • A multi-objective optimisation problem • Aims to extract valid, novel and interesting rules (laws) from data. Support Law generality Validity Confidence Law accuracy The ‘real’ data problem “The flows of particles of various sizes in the austral seas” Details of the data set: Particles at four size groups measured at two depths: 2000 and 3000 m A total of 51 measurements over a period of a few hundred days sm 2000 sm 3000 last 2000 last 3000 med 2000 med 3000 lg 2000 Concentration 1,4 1,2 1 0,8 0,6 0,4 0,2 0 -0,2 0 10 20 30 40 50 60 Example Data provided by V. Athias and C. Jeandel Interactions between particles OBSERVATIONS Adsorption Agglomeration Sinking Dissolved phase TRANSFORMATIONS Suspended particles Parameters AIM Model interactions Sinking particles Methodology Target = LAW Phenotype: a linear combination of terms 1.2x2 + x3sin(x1) + 3.6x1x2 Genotype: coding of the phenotype (1.2,0,2,3), (1,2,3,1), (3.6,1,1,2) where 0 = xi ; 1 = xi * xj ; 2 = xisin xj • Mixed integer–real valued representation hybrid ES/GA • Selection: The problem to find a set of laws (Michigan, Pittsburgh, Universal Suffrage) Assessing the fitness of one law • • • • The law is calculated for each example The results are sorted Plateaux are identified Fitness function is calculated 10 P2 9 8 7 Result 6 P1 5 4 3 2 1 0 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51 Example Testing a simple fitness function Fitness function = Σlength(Pi) The known law (A0 * A1 = cst). Found laws 1) -0.37A0 * A1 – 0.36A2/A2 + 0.07A0/A0 2) -0.04A0*A0 – 0.008A1*A2 – 0.77A1*A0 Problem with the fitness function: Fitness=8 Example Result vj Result vj Fitness=8 Example The new fitness function Identifying the maximum length plateau for each example. F no of plateau examples length P i i 1 Fitness=8 Example Result vj Result vj Fitness=64 Example Correct law: A0*A1=0.156 One of our best results:A0*A1=0.12138 The tautology problem A tautology: A0-A0=0 A1/A1=1 • A tautology provides no knowledge. • The derived laws must be checked for tautologies. • Apply laws to a random data set. • If the law fits all the data then it is a tautology. Lessons from preliminary experiments 1. Population size: no influence on the laws 2. Probability of crossover: Decrease from 0.6 to 0.4: many tautologies So decrease “tautology threshold”: elimination of some tautologies. 3. Probability of mutation: Decrease from 0.1 to 0.05: improvement in laws 4. Plateau threshold Decreasing the threshold in steps: improved laws Plot generated after optimisation 1,46 1,44 Result 1,42 1,4 1,38 1,36 1,34 1,32 1 6 11 16 21 26 31 36 41 46 51 56 Example 61 66 71 76 81 86 91 96 Conclusions • Powerful technique for finding knowledge in data • The fitness function is crucial • Tuning of the algorithm is data dependant • No single optimum algorithm for a specific dataset Questions arising • • • • Pre-processing of data ? Criteria for defining a plateau ? Number of constructs and type of constructs ? How important is law interpretation ?