Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
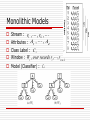
On Reducing Classifier Granularity in Mining Concept-Drifting Data Streams Peng Wang, H. Wang, X. Wu, W. Wang, and B. Shi Proc. of the Fifth IEEE International Conference on Data Mining (ICDM’05) Speaker: Yu Jiun Liu Date : 2006/9/26 Introduction State of the art The incrementally updated classifiers. The ensemble classifiers. Model Granularity Traditional : monolithic This paper : semantic decomposition Motivation The model is decomposable into smaller components. The decomposition is semantic-aware in the sense. Monolithic Models Stream : r1 , , rk , Attributes : A1 , , Ad Class Label : C i Window : Wi , over records ri ,, ri w1 Model (Classifier) : Ci Rule-based Models A rule form : p1 p 2 p k C j minsup = 0.3 and minconf = 0.8 Valid rules of W1 are: Valid rules of W3 are: Algorithm Phase 1 : Initialization Use the first w records to train all valid rules for window W1. Construct the RS-tree and REC-tree. Phase 2 : Update When record ri w arrives, insert it into the REC-tree and update the sup. and conf. of the rules matched by it. Delete oldest record and update the value matched by it. Data Structure RS-Tree A prefix tree with attribute order Each node N represents a unique rule R : P Ci N’ (P’ Cj) is a child node of N, iff: REC-Tree Each record r as a sequence Node N points to rule in the RS-tree if : Detecting Concept Drifts percentage V.S. the distribution of the misclassified records. The percentage approach cannot tell us which part of the classifier gives rise to the inaccuracy. Definition Finding Rule Algorithm Update Algorithm Experiments CPU : 1.7 GHz Memory : 256MB Datasets : synthetic and real life dataset. Synthetic : Real life dataset : 10,344 recodes and 8 dimensions. Effect of model updating Synthetic 10 dimensions Window size 5000 4 dimensions changing The relation of concept drifts and N ij Effect of rule composition Accuracy and Time Window size : 10,000 EC : 10 classifiers, each trained on 1000 records. Synthetic data. Real life data Conclusion Overcome the effects of concept drifts. By reducing granularity, change detection and model update can be more efficient without compromising classification accuracy.