Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
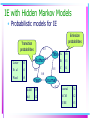
Data mining An overview of techniques and applications Sunita Sarawagi IIT Bombay http://www.it.iitb.ernet.in/~sunita Data mining • Process of semi-automatically analyzing large databases to find patterns that are: – valid: hold on new data with some certainity – novel: non-obvious to the system – useful: should be possible to act on the item – understandable: humans should be able to interpret the pattern • Other names: Knowledge discovery in databases, Data analysis Relationship with other fields • Overlaps with machine learning, statistics, artificial intelligence, databases, visualization but more stress on – scalability of number of features and instances – stress on algorithms and architectures whereas foundations of methods and formulations provided by statistics and machine learning. – automation for handling large, heterogeneous data Outline • Mining operations – Classification – Clustering – Association rule mining – Sequence mining • Two applications – Intrusion detection – Information extraction Applications Methods Classification X1 X2 ... Xn Y 2 6.7 BB + 5 3.4 .. CA + .. – Xi could numeric or string – Special attribute Y, the class-label .. • Given, a table D of rows with columns X1..Xn,Y • Training – Learn a classifier C that can predict the label Y in terms of X1,X2..Xn – C must hold for .. .. 10 • examples in D • unseen data 0.9 C • Application – Use C to predict Y for new X-s .. 10 0.9 CX - +/CX ? Automatic loan approval • Given old data about customers and payments, predict new applicant’s loan eligibility. Previous customers Classifier Decision rules Salary > 5 L Age Salary Profession Location Customer type Prof. = Exec New applicant’s data Age Salary Profession Location Good/ bad Drug design: molecular Bioactivity • Predict activity of compounds binding to thrombin • Library of compounds included: – 1909 known molecules (42 actively binding thrombin) • 139,351 binary features describe the 3D structure of each compound • 636 new compounds with unknown capacity to bind thrombin Automatic webpage classification • Several large categorized search engines – Yahoo, Dmoz used in Google/Altavista • Web: 2 billion pages and only a subset in the directories • Existing taxonomies manually created • Need to automatically classify new pages Several classification methods • Regression • Decision tree Choose based on classifier – data type (numeric,categorical) • Rule-learners – number of attributes – number of classes • Neural networks – number of training • Generative models examples – need for interpretation • Nearest neighbor • Support vector machines Nearest neighbor • Define similarity between instances • Find neighbors of new instance in training data – K-NN approach: assign majority class amongst k nearest neighbour – weighted regression: learn a new regression equation by weighting each training instance based on distance from new instance • Pros + Fast training • Cons – Slow during application. – No feature selection. – Notion of proximity vague Decision tree classifiers • Widely used learning method • Easy to interpret: can be re-represented as if-then-else rules • Approximates function by piece wise constant regions • Does not require any prior knowledge of data distribution, works well on noisy data. Decision trees • Tree where internal nodes are simple decision rules on one or more attributes and leaf nodes are predicted class labels. Salary < 20K Profession = teacher Good Bad Age < 30 Bad Good Algorithm for tree building • Greedy top-down construction. Gen_Tree (Node, data) make node a leaf? Yes Stop Selection Find best attribute and best split on attribute criteria Partition data on split condition For each child j of node Gen_Tree (node_j, data_j) Support vector machines • Binary classifier: find hyper-plane providing maximum margin between vectors of the two classes fj fi Support Vector Machines • Extendable to: – Non-separable problems (Cortes & Vapnik, 1995) – Non-linear classifiers (Boser et al., 1992) • Good generalization performance – OCR (Boser et al.) – Vision (Poggio et al.) – Text classification (Joachims) • Requires tuning: which kernel, what parameters? • Several freely available packages: SVMTorch Neural networks • Useful for learning complex data like handwriting, speech and image recognition Decision boundaries: Linear regression Classification tree Neural network Bayesian learning • Assume a probability model on generation of data. • Apply Bayes theorem to find most likely class as: c max p(c j | d ) max cj p(d | c j ) p(c j ) p(d ) cj • Naïve bayes: Assume attributes conditionally independent given class value p(c j ) n c max cj p(a p(d ) i 1 i | cj) Meta learning methods • No single classifier good under all cases • Difficult to evaluate in advance the conditions • Meta learning: combine the effects of the classifiers – Voting: sum up votes of component classifiers – Combiners: learn a new classifier on the outcomes of previous ones: – Boosting: staged classifiers • Disadvantage: interpretation hard – Knowledge probing: learn single classifier to mimick meta classifier Outline • Mining operations – Classification Applications – Clustering Methods – Association rule mining – Sequence mining What is Cluster Analysis? • Cluster: a collection of data objects – Similar to one another within the same cluster – Dissimilar to the objects in other clusters • Cluster analysis – Grouping a set of data objects into clusters • Clustering is unsupervised classification: no predefined classes • Typical applications – As a stand-alone tool to get insight into data distribution – As a preprocessing step for other algorithms Applications • Customer segmentation e.g. for targeted marketing – Group/cluster existing customers based on time series of payment history such that similar customers in same cluster. – Identify micro-markets and develop policies foreach • Image processing • Text clustering e.g. scatter/gather • Compression Distance functions • Numeric data: euclidean, manhattan distances – Minkowski metric: [sum(xi-yi)^m]^(1/m) – Larger m gives higher weight to larger distances • Categorical data: 0/1 to indicate presence/absence – Euclidean distance: equal weightage to 1 and 0 match – Hamming distance (# dissimilarity) – Jaccard coefficients: #similarity in 1s/(# of 1s) (00 matches not important – data dependent measures: similarity of A and B depends on co-occurance with C. • Combined numeric and categorical data:weighted normalized distance: Clustering methods • Hierarchical clustering – agglomerative Vs divisive – single link Vs complete link • Partitional clustering – distance-based: K-means – model-based: EM – density-based: Outline • Mining operations – Classification – Clustering – Association rule mining – Sequence mining • Two applications – Intrusion detection – Information extraction Applications Methods Intrusion via privileged programs • Attacks exploit a loophole in the program to do illegal actions – Example: exploit buffer over-flows to run user-code • What to monitor of an executing privileged program to detect attacks? • Sequence of system calls – |S| = set of all possible system calls ~100 • Mining problem: given traces of previous normal execution, monitor a new execution and flag attack or normal • Challenge: is it possible to do this given widely varying normal conditions? open lseek lstat mmap execve ioctl ioctl close execve close unlink Detecting attacks on privileged programs • • Short sequences of system calls made during normal execution of system calls are very consistent, yet different from the sequences of its abnormal executions Each execution a trace of system calls: – ignore online traces for the moment • Two approaches – STIDE • Create dictionary of unique k-windows in normal traces, count what fraction occur in new traces and threshold. – IDS • next... Classification models on k-grams • When both normal and abnormal data available – class label = normal/abnormal: • When only normal trace, 7-grams class labels 4 2 66 66 4 138 66 “normal” 5 5 5 4 59 105 104 “abnormal” … … 6 attributes Class labels 4 2 66 66 4 138 “66” 5 5 5 4 59 105 “104” … … – class-label=k-th system call Learn rules to predict class-label [RIPPER] Examples of output RIPPER rules • Both-traces: – if the 2nd system call is vtimes and the 7th is vtrace, then the sequence is “normal” – if the 6th system call is lseek and the 7th is sigvec, then the sequence is “normal” –… – if none of the above, then the sequence is “abnormal” • Only-normal: – if the 3rd system call is lstat and the 4th is write, then the 7th is stat – if the 1st system call is sigblock and the 4th is bind, then the 7th is setsockopt –… – if none of the above, then the 7th is open Experimental results on sendmail • The output rule sets contain ~250 rules, each with 2 or 3 attribute tests • Score each trace by counting fraction of mismatches and thresholding Summary: Only normal traces sufficient to detect intrusions traces sscp-1 sscp-2 sscp-3 syslog-remote-1 syslog-remote-2 syslog-local-1 syslog-local-2 decode-1 decode-2 sm565a sm5x sendmail Only-normal 13.5 13.6 13.6 11.5 8.4 6.1 8.0 3.9 4.2 8.1 8.2 0.6 BOTH 32.2 30.4 30.4 21.2 15.6 11.1 15.9 2.1 2.0 8.0 6.5 0.1 Information extraction • Automatically extract structured fields from unstructured documents – by learning from examples • Technology: – Graph models (Hidden Markov Models) – Probabilistic parsers • Applications: – Comparison shopping agents – Bibliography databases (citeseer) – Address elementization (IIT Bombay) Problem definition Source: concatenation of structured elements with limited reordering and some missing fields – Example: Addresses, bib records House number 156 Author Building Road Area City Hillside ctype Scenic drive Powai Mumbai Year Title Journal Zip 400076 Volume Page P.P.Wangikar, T.P. Graycar, D.A. Estell, D.S. Clark, J.S. Dordick (1993) Protein and Solvent Engineering of Subtilising BPN' in Nearly Anhydrous Organic Media J.Amer. Chem. Soc. 115, 12231-12237. Learning to segment Given, – list of structured elements – several examples showing position of structured elements in text, Train a model to identify them in unseen text At top-level a classification problem Issues: What are the input features? Build per-element classifiers or a single joint classifier? Which type of classifier to use? How much training data is required? Input features Content of the element Specific keywords like street, zip, vol, pp, Properties of words like capitalization, parts of speech, number? Inter-element sequencing Intra-element sequencing Element length IE with Hidden Markov Models • Probabilistic models for IE Emission probabilities Transition probabilities 0.5 Author Letter 0.3 Et. al 0.1 0.1 Word 0.5 Year Title 0.9 0.5 A 0.6 B 0.3 C 0.1 0.8 dddd 0.8 dd 0.2 Journal 0.2 journal 0.4 ACM 0.2 IEEE 0.3 HMM Structure Naïve Model: One state per element … Mahatma Gandhi Road Near Parkland ... Nested model Each element another HMM … [Mahatma Gandhi Road Near : Landmark] Parkland ... Results: Comparative Evaluation Dataset inst anc es Elem ents IITB student Addresses 2388 17 Company Addresses 769 6 US Addresses 740 6 The Nested model does best in all three cases Mining market • Around 20 to 30 mining tool vendors • Major tool players: – SAS’s Enterprise Miner. – IBM’s Intelligent Miner, – SGI’s MineSet, • All pretty much the same set of tools • Many embedded products: – – – – fraud detection: electronic commerce applications, health care, customer relationship management: Epiphany