Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Knowledge Discovery & Data
Mining
• process of extracting previously unknown, valid, and
actionable (understandable) information from large
databases
• Data mining is a step in the KDD process of applying
data analysis and discovery algorithms
• Machine learning, pattern recognition, statistics,
databases, data visualization.
• Traditional techniques may be inadequate
– large data
Why Mine Data?
• Huge amounts of data being collected and warehoused
– Walmart records 20 millions transactions per day
– WebLogs Millions of hits per day on major sites
– health care transactions: multi-gigabyte databases
– Mobil Oil: geological data of over 100 terabytes
• Affordable computing
• Competitive pressure
– gain an edge by providing improved, customized
services
– information as a product in its own right
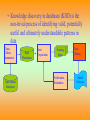
• Knowledge discovery in databases (KDD) is the
non-trivial process of identifying valid, potentially
useful and ultimately understandable patterns in
data
Clean,
Collect,
Summarize
Operational
Databases
Data
Warehouse
Data
Preparation
Training
Data
Verification,
Evaluation
Data
Mining
Model
Patterns
Data mining
• Pattern
– 12121?
– ’12’ pattern is found often enough So, with some confidence we can
say ‘?’ is 2
– “If ‘1’ then ‘2’ follows”
– Pattern Model
Confidence
– 121212?
– 12121231212123121212?
– 121212 3
• Models are created using historical data by detecting patterns. It is a
calculated guess about likelihood of repetition of pattern.
Note: Models and patterns: A pattern can be thought of as
an instantiation of a model. Eg. f(x) = 3 x2 + x is a
pattern whereas f(x) = ax2 + bx is considered a model.
Data mining involves fitting models to and determining
patterns from observed data.
Data Mining
• Prediction Methods
– using some variables to predict unknown or future
values of other variables
– It uses database fields (predictors) for prediction
model, using the field values we can make predictions
• Descriptive Methods
– finding human-interpretable patterns describing the
data
Data Mining Techniques
•
•
•
•
•
•
Classification
Clustering
Association Rule Discovery
Sequential Pattern Discovery
Regression
Deviation Detection
Classification
• Data defined in terms of attributes, one of which is the class
• Find a model for class attribute as a function of the values of
other(predictor) attributes, such that previously unseen records
can be assigned a class as accurately as possible.
• Training Data: used to build the model
• Test data: used to validate the model (determine accuracy of the
model)
Given data is usually divided into training and test sets.
Classification
• Given old data about customers and payments,
predict new applicant’s loan eligibility.
Previous customers
Age
Salary
Profession
Location
Customer type
Classifier
Decision rules
Salary > 5 L
Prof. = Exec
New applicant’s data
Good/
bad
Classification methods
Goal: Predict class Ci = f(x1, x2, .. Xn)
• Regression: (linear or any other polynomial)
• Decision tree classifier: divide decision space into
piecewise constant regions.
• Neural networks: partition by non-linear boundaries
• Probabilistic/generative models
• Lazy learning methods: nearest neighbor
Decision trees
• Tree where internal nodes are simple decision rules
on one or more attributes and leaf nodes are
predicted class labels.
Salary < 50 K
Prof = teacher
Good
Age < 30
Bad
Bad
Good
Classification:Example
Decision Tree
Training
Dataset
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
income student credit_rating
high
no
fair
high
no
excellent
high
no
fair
medium
no
fair
low
yes
fair
low
yes
excellent
low
yes
excellent
medium
no
fair
low
yes
fair
medium
yes
fair
medium
yes
excellent
medium
no
excellent
high
yes
fair
medium
no
excellent
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
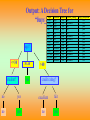
Output: A Decision Tree for
“buys_computer”
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
age?
<=30
overcast
30..40
student?
yes
income student credit_rating
high
no
fair
high
no
excellent
high
no
fair
medium
no
fair
low
yes
fair
low
yes
excellent
low
yes
excellent
medium
no
fair
low
yes
fair
medium
yes
fair
medium
yes
excellent
medium
no
excellent
high
yes
fair
medium
no
excellent
>40
credit rating?
no
yes
excellent
fair
no
yes
no
yes
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
Algorithm for Decision Tree
Induction
• Basic algorithm (a greedy algorithm)
– Tree is constructed in a top-down recursive divide-and-conquer manner
– At start, all the training examples are at the root
– Attributes are categorical (if continuous-valued, they are discretized in
advance)
– Examples are partitioned recursively based on selected attributes
– Test attributes are selected on the basis of a heuristic or statistical measure
(e.g., information gain)
• Conditions for stopping partitioning
– All samples for a given node belong to the same class
– There are no remaining attributes for further partitioning – majority voting
is employed for classifying the leaf
– There are no samples left
Attribute Selection Measure:
Information Gain (ID3/C4.5)
Select the attribute with the highest information gain
S contains si tuples of class Ci for i = {1, …, m}
information measures info required to classify any arbitrary
tuple
m
I( s1,s2,...,sm )
i 1
si
si
log 2
s
s
entropy of attribute A with values {a1,a2,…,av}
s1 j ... smj
I ( s1 j ,..., smj )
s
j 1
v
E(A)
information gained by branching on attribute A
Gain(A) I(s 1, s 2 ,..., sm) E(A)
Attribute Selection by Information
Gain Computation
Class P: buys_computer = “yes”
Class N: buys_computer = “no”
I(p, n) = I(9, 5) =0.940
Compute the entropy for age:
age
<=30
30…40
>40
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
income
high
high
high
medium
low
low
low
medium
low
medium
medium
medium
high
medium
5
4
I ( 2,3)
I ( 4,0)
14
14
5
I (3,2) 0.694
14
E ( age)
pi
2
4
3
ni I(pi, ni)
5
I (2,3)means “age <=30” has 5 out
3 0.971
14 of 14 samples, with 2 yes’es and
0 0
3 no’s. Hence
2 0.971
student credit_rating buys_computer
no
fair
no
Gain(age) I ( p, n) E (age) 0.246
no
no
no
yes
yes
yes
no
yes
yes
yes
no
yes
no
excellent
fair
fair
fair
excellent
excellent
fair
fair
fair
excellent
excellent
fair
excellent
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
Similarly,
Gain(income) 0.029
Gain( student ) 0.151
Gain(credit _ rating ) 0.048
Classification: Direct Marketing
• Goal: Reduce cost of soliciting (mailing) by targeting a set
of consumers likely to buy a new product.
• Data
– for similar product introduced earlier
– we know which customers decided to buy and which
did not {buy, not buy} class attribute
– collect various demographic, lifestyle, and company
related information about all such customers - as
possible predictor variables.
• Learn classifier model
Classification: Fraud detection
• Goal: Predict fraudulent cases in credit card
transactions.
• Data
– Use credit card transactions and information on its
account-holder as input variables
– label past transactions as fraud or fair.
• Learn a model for the class of transactions
• Use the model to detect fraud by observing credit
card transactions on a given account.
Clustering
• Given a set of data points, each having a set of
attributes, and a similarity measure among them,
find clusters such that
– data points in one cluster are more similar to one
another
– data points in separate clusters are less similar to one
another.
• Similarity measures
– Euclidean distance, if attributes are continuous
– Problem specific measures
Clustering: Market Segmentation
• Goal: subdivide a market into distinct subsets of
customers where any subset may conceivably be selected
as a market target to be reached with a distinct marketing
mix.
• Approach:
– collect different attributes on customers based on
geographical, and lifestyle related information
– identify clusters of similar customers
– measure the clustering quality by observing buying
patterns of customers in same cluster vs. those from
different clusters.
Association Rule Discovery
• Given a set of records, each of which contain some
number of items from a given collection
– produce dependency rules which will predict
occurrence of an item based on occurences of other
items
Association Rule: Basic Concepts
• Given: (1) database of transactions, (2) each transaction is a list
of items (purchased by a customer in a visit)
• Find: all rules that correlate the presence of one set of items
with that of another set of items
– E.g., 98% of people who purchase tires and auto accessories also get
automotive services done
• Applications
– * Maintenance Agreement (What the store should do to boost
Maintenance Agreement sales)
– Home Electronics * (What other products should the store stocks
up?)
– Attached mailing in direct marketing
Association Rule: Basic Concepts
number of tuples containing both A and B
Support (A B) = ----------------------------------------------total number of tuples
number of tuples containing both A and B
Confidence (A B) = ----------------------------------------total number of tuples containg A
Rule Measures: Support and Confidence
Customer
buys both
Customer
buys b
Customer
buys d
• Find all the rules X & Y Z with
minimum confidence and support
– support, s, probability that a transaction
contains {X , Y , Z}
– confidence, c, conditional probability that
a transaction having {X , Y} also contains
Z
Transaction ID Items Bought Let minimum support 50%, and
2000
A,B,C
minimum confidence 50%, we
1000
A,C
have
4000
A,D
– A C (50%, 66.6%)
5000
B,E,F
– C A (50%, 100%)
Mining Association Rules—An
Example
Transaction ID
2000
1000
4000
5000
Items Bought
A,B,C
A,C
A,D
B,E,F
For rule A C:
Min. support 50%
Min. confidence 50%
Frequent Itemset Support
{A}
75%
{B}
50%
{C}
50%
{A,C}
50%
support = support({A , C}) = 50%
confidence = support({A , C})/support({A}) = 66.6%
Association Rules:Application
• Marketing and Sales Promotion:
• Consider discovered rule:
{Bagels, … } --> {Potato Chips}
– Potato Chips as consequent: can be used to determine
what may be done to boost sales
– Bagels as an antecedent: can be used to see which
products may be affected if bagels are discontinued
– Can be used to see which products should be sold with
Bagels to promote sale of Potato Chips
Association Rules: Application
• Supermarket shelf management
• Goal: to identify items which are bought together
(by sufficiently many customers)
• Approach: process point-of-sale data (collected
with barcode scanners) to find dependencies
among items.
• Example
– If a customer buys Diapers and Milk, then he is very
likely to buy Beer
– so stack six-packs next to diapers?
Sequential Pattern Discovery
• Given: set of objects, each associated with its own
timeline of events, find rules that predict strong
sequential dependencies among different events,
of the form (A B) (C) (D E) --> (F)
•xg :max allowed time between consecutive
event-sets
• ng: min required time between consecutive
event sets
•ws: window-size, max time difference between
earliest and latest events in an event-set (events
within an event-set may occur in any order)
•ms: max allowed time between earliest and
latest events of the sequence.
Sequential Pattern Discovery: Examples
• Sequences in which customers purchase goods/services
• Understanding long term customer behavior -- timely
promotions.
In point-of--sale transaction sequences
– Computer bookstore:
(Intro to Visual C++) (C++ Primer) --> (Perl for
Dummies, Tcl/Tk)
– Athletic Apparel Store:
(Shoes) (Racket, Racquetball) --> (Sports Jacket)