Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Knowledge Discovery & Data
Mining
• process of extracting previously unknown, valid,
and actionable (understandable) information from
large databases
• Data mining is a step in the KDD process of
applying data analysis and discovery algorithms
• Machine learning, pattern recognition, statistics,
databases, data visualization.
• Traditional techniques may be inadequate
– large data
Why Mine Data?
• Huge amounts of data being collected and
warehoused
– Walmart records 20 millions per day
– health care transactions: multi-gigabyte databases
– Mobil Oil: geological data of over 100 terabytes
• Affordable computing
• Competitive pressure
– gain an edge by providing improved, customized services
– information as a product in its own right
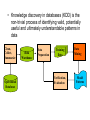
• Knowledge discovery in databases (KDD) is the
non-trivial process of identifying valid, potentially
useful and ultimately understandable patterns in
data
Clean,
Collect,
Summarize
Operational
Databases
Data
Warehouse
Data
Preparation
Training
Data
Verification,
Evaluation
Data
Mining
Model
Patterns
Data mining
• Pattern
– 1212121?
– ’12’ pattern is found often enough So, with some confidence we
can say ‘?’ is 2
– “If ‘1’ then ‘2’ follows”
– Pattern Model
Confidence
– 12121?
– 12121231212123121212?
– 1211212 3
• Models are created using historical data by detecting
patterns. It is a calculated guess about likelihood of
repetition of pattern.
Data mining algorithm components
• Model representation
– descriptions of discovered patterns
– overly limited representation -- unable to capture data patterns
(decision trees, rules, linear/non-linear regression & classification,
nearest neighbor and case-based reasoning methods, graphical
dependency models)
• Model evaluation criteria
– how well a pattern (model) meets goals (fit function)
– eg., accuracy
• Search method
– parameter search: optimization of of parameters for a given model
representation
– model search: considers a family of models
Different methods suit different problems. Proper
problem formulation crucial.
Note: Models and patterns: A pattern can be thought of as
an instantiation of a model. Eg. f(x) = 3 x2 + x is a
pattern whereas f(x) = ax2 + bx is considered a model.
Data mining involves fitting models to and determining
patterns from observed data.
Where are Models Used?
1.
Selection
Business trying to select prospective customers (Profitability)
A model that predicts the LD usage based on credit history.
2. Acquisition
Selection is who would you like to invite to a party. Acquisition is
about getting them to agree. Putting together a plan that will
make them say yes. Again a model.
3. Retention
Keeping your flock together! Sensing it before they jump the ship.
4. Extension
Extending services to existing customers. Cross-selling
Knowledge Discovery Process
• Goal
– understanding the application domain, and goals of KDD effort
• Data selection, acquisition, integration
• Data cleaning
– noise, missing data, outliers, etc.
• Exploratory data analysis
– dimensionality modeling, transformations
– selection of appropriate model for analysis, hypotheses to test
• Data mining
– selecting appropriate method that match set goals (classification,
regression, clustering, etc)
– selecting algorithm
• Testing and verification
• Interpretation
• Consolidation and use
Issues and challenges
• large data
– number of variables (features), number of cases (examples)
– multi gigabyte, terabyte databases
– efficient algorithms, parallel processing
• high dimensionality
– large number of features: exponential increase in search
space
– potential for spurious patterns
– dimensionality reduction
• Overfitting
– models noise in training data, rather than just the general
patterns
• Changing data, missing and noisy data
• Use of domain knowledge
– utilizing knowledge on complex data relationships, known facts
• Understandability of patterns
Data Mining
• Prediction Methods
– using some variables to predict unknown or future values of
other variables
– It uses database fields (predictors) for prediction model,
using the field values we can make predictions
• Descriptive Methods
– finding human-interpretable patterns describing the data
Data Mining Techniques
•
•
•
•
•
•
Classification
Clustering
Association Rule Discovery
Sequential Pattern Discovery
Regression
Deviation Detection
Classification
• Data defined in terms of attributes, one of which is the
class
• Find a model for class attribute as a function of
the values of other(predictor) attributes, such
that previously unseen records can be assigned
a class as accurately as possible.
• Training Data: used to build the model
• Test data: used to validate the model (determine
accuracy of the model)
Given data is usually divided into training and test sets.
Classification:Example
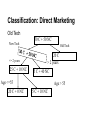
Classification: Direct Marketing
Old Tech
New Tech
<= 2 years
25 C + 10 NC
50 C + 50 NC
Old Tech
20 C
> 2 years
5 C + 40 NC
Age <=55
20 C + 0 NC
Age > 55
5 C + 10 NC
Classification: Decision Tree
• It divides up the data on each branch point without losing any of
the data
• The number of C + NC is conserved
• Easy and intuitive to build
It builds the tree by asking all possible questions, at each stage it
picks the best one that splits the data in two segments.
Recursively applies at all levels.
The tree stops:
• Segment contains only one record or predefined min. records.
• The segment is organized on single prediction value
• The improvement is not sufficient to warrant a split. i.e. the
question improves from 90 C to 89 C
Classification: Decision Tree
•
The decision tree algorithm requires sufficient discriminating data
for tree to grow
Name
Age
Eyes
Salary
Churned?
Steve
27
Blue
80,000
Yes
Alex
27
Blue
80,000
No
Name is the only distinct predictor?
Decision trees continue to work as more data accumulates
Classification: Decision Tree
•
•
•
How to choose a good predictor?
Usually chose a numeric measure of goodness
Best predictor decreases the disorder of data set
A
Y
E
N
A
N
C
Y
B
Y
F
N
B
Y
D
Y
C
Y
G
N
F
Y
E
N
D
Y
H
N
G
N
H
N
For age <50 100% predictor
For salary >300000 each segment has 50% split
ID3 and CART are good algorithms for decision tree building
Classification: Direct Marketing
• Goal: Reduce cost of soliciting (mailing) by
targeting a set of consumers likely to buy a new
product.
• Data
– for similar product introduced earlier
– we know which customers decided to buy and which did
not {buy, not buy} class attribute
– collect various demographic, lifestyle, and company
related information about all such customers - as
possible predictor variables.
• Learn classifier model
Classification: Fraud detection
• Goal: Predict fraudulent cases in credit card
transactions.
• Data
– Use credit card transactions and information on its accountholder as input variables
– label past transactions as fraud or fair.
• Learn a model for the class of transactions
• Use the model to detect fraud by observing credit
card transactions on a given account.
Clustering
• Given a set of data points, each having a set of
attributes, and a similarity measure among them,
find clusters such that
– data points in one cluster are more similar to one another
– data points in separate clusters are less similar to one
another.
• Similarity measures
– Euclidean distance if attributes are continuous
– Problem specific measures
Clustering: Market Segmentation
• Goal: subdivide a market into distinct subsets of
customers where any subset may conceivably be
selected as a market target to be reached with a
distinct marketing mix.
• Approach:
– collect different attributes on customers based on
geographical, and lifestyle related information
– identify clusters of similar customers
– measure the clustering quality by observing buying patterns
of customers in same cluster vs. those from different
clusters.
Association Rule Discovery
• Given a set of records, each of which contain
some number of items from a given collection
– produce dependency rules which will predict occurrence of
an item based on occurences of other items
Association Rules:Application
• Marketing and Sales Promotion:
• Consider discovered rule:
{Bagels, … } --> {Potato Chips}
– Potato Chips as consequent: can be used to determine
what may be done to boost sales
– Bagels as an antecedent: can be used to see which
products may be affected if bagels are discontinued
– Can be used to see which products should be sold with
Bagels to promote sale of Potato Chips
Association Rules: Application
• Supermarket shelf management
• Goal: to identify items which are bought together
(by sufficiently many customers)
• Approach: process point-of-sale data (collected
with barcode scanners) to find dependencies
among items.
• Example
– If a customer buys Diapers and Milk, then he is very likely to
buy Beer
– so stack six-packs next to diapers?
Sequential Pattern Discovery
• Given: set of objects, each associated with its
own timeline of events, find rules that predict
strong sequential dependencies among different
events, of the form (A B) (C) (D E) --> (F)
•xg :max allowed time between consecutive
event-sets
• ng: min required time between consecutive
event sets
•ws: window-size, max time difference between
earliest and latest events in an event-set (events
within an event-set may occur in any order)
•ms: max allowed time between earliest and
latest events of the sequence.
Sequential Pattern Discovery:
Examples
• sequences in which customers purchase goods/services
• understanding long term customer behavior -- timely
promotions.
• In point-of--sale transaction sequences
– Computer bookstore:
(Intro to Visual C++) (C++ Primer) --> (Perl for Dummies,
TCL/TK)
– Athletic Apparel Store:
(Shoes) (Racket, Racketball) --> (Sports Jacket)
Regression
• Predict a value of a given continuous valued
variable (dependent variable) based on values of
other variables (independent variables)
• Statistics, Neural networks, Genetic algorithms
• Examples:
– predicting sales volumes of new product based on
advertising expenditure
– Time series prediction of stock market indices.
Visualization
• complement to other DM techniques like
Segmentation,etc.