Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
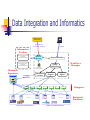
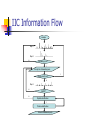
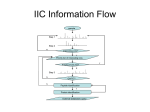
Data Management Support for Life Sciences or What can we do for the Life Sciences? Mourad Ouzzani [email protected] The Big Picture Proteomics, Metabolomics, & Cytomics Sample Data Purdue BioScience Pipeline Experiments Storage System Data Streaming System Samples Processed Data Raw MS file Peak Deconvolution Noise filtering Online Analysis Raw peak group Peak group selection Single scan clusters Doublet detection Charge fitting Chromatographic refinement Mixed doublet rescue Multiscan clusters Isotope fitting Data Mining Priority list Protein identification Calculation of Differentials Web Service Internet Biological Databases Databases Integration System Raw Data Intelligent Instrument Control Protein Identification Mass Spectrometer Diseased Sample Samples Preparation & Transformation (LC, isotoping, etc.…) Non Diseased Sample Mass Spectra Data Analysis Step 1 Step 2 Step 3 Data Mining Massive Data Storage Issues Time sensitive data Limited sample quantities Experiments repetition Massive data Intelligent Instrument Control Mass Spectrometer (1) Instrument Vendor PC (2) Instrument Intelligence (3) Samples Network Databases (4) Raw Data Archives (5) Benefits The outcome of IIC will be biological knowledge instead of raw mass spectra. The biological knowledge is backed up by data acquired by IIC. Scientists do not need to review the raw mass spectra. Data Flow in IIC Nile Support and others IIC Issues IIC system development Non-proprietary API for both data collection and control of the instrument Optimized storage for Massive data (Instrument Output and Sequences) etc. Data Stream Issues Data filters that identify interesting data and reduce chemical noise Algorithms for rapid identification of the base peaks and the number of peaks in the spectrum Algorithms for prediction of upcoming peaks Online statistical analysis over the streams Data summaries on different granularities etc. Data Integration Non-glycosylated peptide identification MS/MS Spectra preprocessing de novo sequencing APLIXYX CLIKWDYR database search stats auto-validation protein validation Protein List Data Integration and Informatics Web Browser Web Service Consumer Web Service Invocation (SOAP) Queries Informatics Toolbox NON-GLYCOSYLATED PEPTIDE IDENTIFICATION Web Service Access GLYCOSYLATED PEPTIDE IDENTIFICATION Web Service Description (WSDL) Metadata Repository Database Discovery Database Locator Request Handler Query Optimizer Execution Engine WebGlyco Manager Mapping Agent Wrappers Biological Databases Glycoprotein Databases Other Protein Databases Data Integration Issues Databases description and organization Schemas mediation Annotation and Provenance Use of model management techniques Query processing and optimization Web-service access Implementation and deployment Requirements Data types diversity: sequences, graphs, 3D structures, etc. Unconventional queries: similarity, pattern matching, etc. Uncertainty (probability) Data curation: cleaning and annotation Data provenance (pedigree) Large scale: 100s of DBs Terminology management (semantics) etc. Data Correlation Non-overlapping Schemas (different instruments or scales of resolution) Contradictory information (experiments with different assumptions) Comparing data only after matching their context (constraints) Other Issues ? IIC Information Flow sample Step 1 Step 2 N Interesting ions? Y Priority list of interesting ions Empty priority list? N Step 3 N N QA/QC? Peptide identification Y Protein identification External Databases query Y Intelligent Instrument Control Algorithms design Spectra Deconvolution Online analysis (protein/peptide identification) Online peaks Identification for feedback Data filters and noise removal Prediction of upcoming peaks Experimental Simulation In silico generation of spectrum Algorithms simulation Intelligent Instrument Control Experimental settings Selection of a biology system, e.g., yeast Two types of experiments Target analysis Global analysis Integration with the instrument Data collection Control of the instrument API Actual implementation (algorithms) Intelligent Instrument Control Online data mining Other Issues: Optimized storage of massive data Data representation (streams, database) Integrated Access to Glycoprotein Databases Informatics tools Glycosylated peptide identification Non-glycosylated peptide identification Enabling uniform access to different glycoprotein databases Databases description and organization Schema mediation Integrated Access to Glycoprotein Databases Query Processing Data correlation Non-overlapping schemas Contradictory information Sequence alignment Web service enabled access Target databases selection (focus)