Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Grid-based Search and Data Mining
Using Cheshire3
Presented by
Ray R. Larson
University of California,
Berkeley
School of Information
In collaboration with
Robert Sanderson
University of Liverpool
Department of Computer Science
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 1
Overview
•
•
•
•
•
•
•
•
•
Introduction
Context
Architecture
Grid
Text Mining
Data Mining
Applications
Future Plans and Applications
Questions?
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 2
Introduction
• Cheshire History:
– Developed at UC Berkeley originally
– Solution for library data (C1), then SGML (C2), then
XML
– Monolithic applications for indexing and retrieval
server in C + TCL scripting
• Cheshire3:
–
–
–
–
Developed at Liverpool, plus Berkeley
XML, Unicode, Grid scalable: Standards based
Object Oriented Framework
Easy to develop and extend in Python
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 3
Introduction
• Today:
– Version 0.9.4
– Mostly stable, but needs thorough QA and docs
– Grid, NLP and Classification algorithms integrated
• Near Future:
– June: Version 1.0
• Further DM/TM integration, docs, unit tests, stability
– December: Version 1.1
• Grid out-of-the-box, configuration GUI
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 4
Context
• Environmental Requirements:
– Very Large scale information systems
• Terabyte scale (Data Grid)
• Computationally expensive processes (Comp. Grid)
• Digital Preservation
• Analysis of data, not just retrieval (Data/Text
Mining)
• Ease of Extensibility, Customizability (Python)
• Open Source
• Integrate not Re-implement
• "Web 2.0" – interactivity and dynamic interfaces
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 5
Context
Application
Layer
User Interface
Web Browser
Multivalent
Dedicated Client
Query
Digital Library Layer
Data Mining Tools
Text Mining Tools
Orange, Weka, ...
User Interface
Tsujii Labs, ...
Natural
Information
Language
Extraction
Processing
MySRB
PAWN
Classification Clustering
Results
Information System
Cheshire3
Protocol Handler
Apache+
Mod_Python+
Cheshire3
Query
Data Grid
Layer
Data Grid
Store
Query
Results
Search /
Retrieve
SRB
iRODS
Index /
Store
Results
Process Management
Term Management
Kepler
Cheshire3
Termine
WordNet
...
ISGC 2007 - Taipei, Taiwan
Document Parsers
Process Management
Multivalent,...
Export
Parse
Kepler
iRODS rules
2007.03.29 SLIDE 6
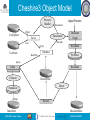
Cheshire3 Object Model
Protocol
Handler
ConfigStore
Ingest Process
Documents
Object
Transformer
Server
Records
User
Document
Query
UserStore
Document
Group
ResultSet
Database
PreParser
PreParser
PreParser
Query
Document
Index
Extracter
RecordStore
Parser
Normaliser
Terms
IndexStore
ISGC 2007 - Taipei, Taiwan
Record
DocumentStore
2007.03.29 SLIDE 7
Object Configuration
• One XML 'record' per non-data object
• Very simple base schema, with extensions as
needed
• Identifiers for objects unique within a context
(e.g., unique at individual database level, but not
necessarily between all databases)
• Allows workflows to reference by identifier but
act appropriately within different contexts.
• Allows multiple administrators to define objects
without reference to each other
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 8
Grid
• Focus on ingest, not discovery (yet)
• Instantiate architecture on every node
• Assign one node as master, rest as slaves.
Master then divides the processing as
appropriate.
• Calls between slaves possible
• Calls as small, simple as possible:
(objectIdentifier, functionName, *arguments)
• Typically:
('workflow-id', 'process', 'document-id')
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 9
Grid Architecture
Master Task
(workflow, process, document)
(workflow, process, document)
fetch document
fetch document
Data Grid
document
document
Slave Task 1
Slave Task N
extracted data
extracted data
GPFS Temporary Storage
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 10
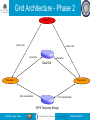
Grid Architecture - Phase 2
Master Task
(index, load)
(index, load)
store index
store index
Data Grid
Slave Task 1
Slave Task N
fetch extracted data
fetch extracted data
GPFS Temporary Storage
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 11
Workflow Objects
• Written as XML within the configuration record.
• Rewrites and compiles to Python code on object
instantiation
Current instructions:
–
–
–
–
–
–
–
–
object
assign
fork
for-each
break/continue
try/except/raise
return
log (= send text to default logger object)
Yes, no if!
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 12
Workflow example
<subConfig id=“buildSingleWorkflow”>
<objectType>workflow.SimpleWorkflow</objectType>
<workflow>
<object type=“workflow” ref=“PreParserWorkflow”/>
<try>
<object type=“parser” ref=“NsSaxParser”/>
</try>
<except>
<log>Unparsable Record</log>
<raise/>
</except>
<object type=“recordStore” function=“create_record”/>
<object type=“database” function=“add_record”/>
<object type=“database” function=“index_record”/>
<log>”Loaded Record:” + input.id</log>
</workflow>
</subConfig>
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 13
Text Mining
• Integration of Natural Language Processing
tools
• Including:
–
–
–
–
Part of Speech taggers (noun, verb, adjective,...)
Phrase Extraction
Deep Parsing (subject, verb, object, preposition,...)
Linguistic Stemming (is/be fairy/fairy vs is/is fairy/fairi)
• Planned: Information Extraction tools
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 14
Data Mining
• Integration of toolkits difficult unless they support
sparse vectors as input - text is high
dimensional, but has lots of zeroes
• Focus on automatic classification for predefined
categories rather than clustering
• Algorithms integrated/implemented:
–
–
–
–
Perceptron, Neural Network (pure python)
Naïve Bayes (pure python)
SVM (libsvm integrated with python wrapper)
Classification Association Rule Mining (Java)
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 15
Data Mining
• Modelled as multi-stage PreParser object
(training phase, prediction phase)
• Plus need for AccumulatingDocumentFactory to
merge document vectors together into single
output for training some algorithms (e.g., SVM)
• Prediction phase attaches metadata (predicted
class) to document object, which can be stored
in DocumentStore
• Document vectors generated per index per
document, so integrated NLP document
normalization for free
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 16
Data Mining + Text Mining
• Testing integrated environment with 500,000 medline abstracts,
using various NLP tools, classification algorithms, and evaluation
strategies.
• Computational grid for distributing expensive NLP analysis
• Results show better accuracy with fewer attributes:
Vector Source
Avg
TCV
Attributes
Accuracy
Every word in document
99
85.7%
Stemmed words in document
95
86.2%
Part of Speech filtered words
69
85.2%
Stemmed Part of Speech filtered
65
86.3%
Genia filtered
68
85.5%
Genia Stem filtered
64
87.2%
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 17
Applications (1)
Automated Collection Strength Analysis
Primary aim: Test if data mining techniques could
be used to develop a coverage map of items
available in the London libraries.
The strengths within the library collections were
automatically determined through enrichment and
analysis of bibliographic level metadata records.
This involved very large scale processing of records to:
– Deduplicate millions of records
– Enrich deduplicated records against database of 45
million
– Automatically reclassify enriched records using
machine learning processes (Naïve Bayes)
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 18
Applications (1)
• Data mining enhances collection mapping strategies by making a
larger proportion of the data usable, by discovering hidden
relationships between textual subjects and hierarchically based
classification systems.
• The graph shows the comparison of numbers of books classified in
the domain of Psychology originally and after enhancement using
data mining
Records per Library for All of Psychology
5500
5000
4500
4000
3500
3000
Original
2500
Enhanced
2000
1500
1000
500
0
Goldsmiths
ISGC 2007 - Taipei, Taiwan
Kings
Queen Mary
Senate
UCL
Westminster
2007.03.29 SLIDE 19
Applications (2)
Assessing the Grade Level of NSDL Education Material
• The National Science Digital Library has assembled a
collection of URLs that point to educational material for
scientific disciplines for all grade levels. These are
harvested into the SRB data grid.
• Working with SDSC we assessed the grade-level
relevance by examining the vocabulary used in the
material present at each registered URL.
• We determined the vocabulary-based grade-level with
the Flesch-Kincaid grade level assessment. The
domain of each website was then determined using data
mining techniques (TF-IDF derived fast domain
classifier).
• This processing was done on the Teragrid cluster at
SDSC.
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 20
Applications (2)
• The formula for the Flesch Reading Ease Score:
FRES = 206.835 –1.015 ((total words)/(total sentences)) – 84.6 ((total
syllables)/(total words))
• The Flesch-Kincaid Grade Level Formula:
FKGLF = 0.39 * ((total words)/(total sentences)) + 11.8 * ((total
syllables)/(total words)) –15.59
• The Domain was determined by:
– Domains used were based upon the AAAS Benchmarks
– Taking in samples from each of the domain areas being examined and
produces scored and ranked lists of vocabularies for each domain.
– Each token in a document is passed through a lookup function against
this table and tallies are calculated for the entire document.
– These tallies are then used to rank the order of likelihood of the
document being about each topic and a statistical pass of the results
returns only those topics that are above in certain threshold.
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 21
Future Plans
• IR Testing and Optimization
– Work with the OCA Book collection as part of INEX
2007
– TREC, CLEF, and INEX Benchmarking
• Integration of Geographic Information Retrieval
methods from Cheshire II
– GIR Ranking and Gazetteer-based text retrieval using
NLP methods
• Pattern-driven text mining methods for extracting
biographical information from texts
– IMLS-funded “Bringing Lives to Light” project
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 22
Overview
• Bringing Lives to Light
– Focusing on the Who in Who, What, Where
and When
– Examining and extending of various types of
Biographical Markup
– Mining biographical data from available
information resources to fill our extended
markup databases
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 23
WHEN, WHERE and WHO
• Catalog records found from a time period search commonly include
names of persons important at that time. Their names can be
forwarded to, e.g., biographies in the Wikipedia encyclopedia.
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 24
Place and time are broadly important across numerous tools
and genres including, e.g. Language atlases, Library catalogs,
Biographical dictionaries, Bibliographies, Archival finding
aids, Museum records, etc., etc.
Biographical dictionaries are also heavy on place and time:
Emanuel Goldberg, Born Moscow 1881. PhD under Wilhelm
Ostwald, Univ. of Leipzig, 1906. Director, Zeiss Ikon,
Dresden, 1926-33. Moved to Palestine 1937. Died Tel Aviv,
1970.
Life as a series of episodes involving Activity (WHAT),
WHERE, WHEN, and WHO else.
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 25
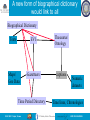
A new form of biographical dictionary
would link to all
Biographical Dictionary
Texts
Maps/
Geo Data
EVI
Thesaurus/
Ontology
Gazetteers
captions
Time Period Directory
ISGC 2007 - Taipei, Taiwan
Numeric
datasets
Time lines, Chronologies
2007.03.29 SLIDE 26
“Lives” Projected Work
• Develop XML markup for Biographical
Events
• Most likely to be adaptation and extension
of existing biographical event markup
– Example: EAC/EAD
• Harvest biographical resources
– Wikipedia, etc.
• Integrate as next generation of current
interface
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 27
EAC/EAD
<bioghist>
<head>Biographical Note</head>
<chronlist>
<chronitem>
<date>1892, May 7</date>
<event>Born, <geogname>Glencoe, Ill.</geogname></event>
</chronitem>
<chronitem>
<date>1915</date>
<event>A.B., <corpname>Yale University, </corpname>New Haven, Conn.</event>
</chronitem>
<chronitem>
<date>1916</date>
<event>Married <persname>Ada Hitchcock</persname>
</event>
</chronitem>
<chronitem>
<date>1917-1919</date>
<event>Served in <corpname>United States Army</corpname></event>
</chronitem>
</chronlist>
</bioghist>
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 28
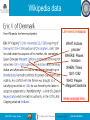
Wikipedia data
Life events metadata
WHAT: Actions
prisoner
WHERE: Places
Holstein
WHEN: Times
1261-1262
WHO: People
Margaret Sambiria
Need external links
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 29
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 30
A Metadata Infrastructure
INTERMEDIA INFRASTRUCTURE
Facet
Authority Control
Special Display Tools
RESOURCES
CATALOGS
WHAT
Thesaurus
Syndetic Structure
Learners
WHERE
Gazetteer
Maps
WHEN
Time Period Directory
Timelines
WHO
Biographical Dictionary
Achives
Historical Societies
Libraries
Museums
Public Television
Publishers
Booksellers
Audio
Images
Numeric Data
Objects
Texts
Virtual Reality
Webpages
Dossiers
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 31
“Lives” Acknowledgements
• Electronic Cultural Atlas Initiative project
• This work is being supported supported by the Institute
of Museum and Library Services through a National
Leadership Grant for Libraries
• Contact: [email protected]
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 32
Thank you!
Available via http://www.cheshire3.org
ISGC 2007 - Taipei, Taiwan
2007.03.29 SLIDE 33