Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
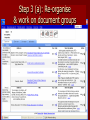
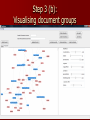
Data mining, interactive semantic structuring, and collaboration: A diversity-aware method for sense-making in search Mathias Verbeke, Bettina Berendt, Siegfried Nijssen Dept. Computer Science, KU Leuven Agenda Motivation Diversity Diversity-aware tools (our) Context Main part Measures of diversity Tool Outlook Motivation (1): Diversity is ... Speaking different languages (etc.) localisation / internationalisation Having different abilities accessibility Liking different things collaborative filtering Structuring the world in different ways ? Motivation (2): Diversity-aware applications ... Must have a (formal) notion of diversity Can follow a – “personalization approach“ adapt to the user‘s value on the diversity variable(s) transparently? Is this paternalistic? – “customization approach“ show the space of diversity allow choice / semi-automatic! (Our) Context Diversity and Web usage: language, culture 2. Family of tools focussing on interactive sensemaking helped by data mining 1. – PORPOISE: global and local analysis of news and blogs + their relations – STORIES: finding + visualisation of “stories” in news – CiteseerCluster: literature search + sense-making – Damilicious: CiteseerCluster + re-use/transfer of semantics + diversity Measuring grouping diversity Diversity = 1 – similarity = 1 - Normalized mutual information By colour & NMI = 0 NMI = 0.35 Measuring user diversity “How similarly do two users group documents?“ For each query q, consider their groupings gr: For various queries: aggregate ... and now: the application domain ... that‘s only the 1st step! Workflow 1. 2. 3. 4. Query Automatic clustering Manual regrouping Re-use 1. Learn + present way(s) of grouping 2. Transfer the constructed concepts Concepts Extension – the instances in a group Intension – Ideally: “squares vs. circles“ – Pragmatically: defined via a classifier Step 1: Retrieve CiteseerX via OAI Output: set of – document IDs, – document details – their texts Step 2: Cluster “the classic bibliometric solution“ CiteseerCluster: – Similarity measure: co-citation, bibliometric coupling, word or LSA similarity, combinations – Clustering algorithm: k-means, hierarchical Damilicious: phrases Lingo How to choose the “best“? – Experiments: Lingo better than k-means at reconstruction and extension-over-time Step 3 (a): Re-organise & work on document groups Step 3 (b): Visualising document groups Steps 4+5: Re-use Basic idea: 1. learn a classifier from the final grouping (Lingo phrases) 2. apply the classifier to a new search result “re-use semantics“ Whose grouping? – One‘s own – Somebody else‘s Which search result? – – – – “ the same“ (same query, structuring by somebody else) “ More of the same“ (same query, later time more doc.s) “ related“ (... Measured how? ...) arbitrary Visualising user diversity (1) Simulated users with different strategies U0: did not change anything (“System“) U1: tried produce a better fit of the document groups to the cluster intensions; 5 regroupings U2: attempted to move everything that did not fit well into the remainder group “Other topics”, & better fit; 10 regroupings U3: attempted to move everything from „Other topics“ into matching real groups; 5 regroupings U4: regrouping by author and institution; 5 regroupings 5*5 matrix of diversities gdiv(A,B,q) multidimensional scaling Visualising user diversity (2) Web mining Data mining RFID aggregated using gdiv(A,B) Evaluating the application Clustering only: Does it generate meaningful document groups? – yes (tradition in bibliometrics) – but: data? – Small expert evaluation of CiteseerCluster Clustering & regrouping – End-user experiment with CiteseerCluster – 5-person formative user study of Damilicious Summary and (some) open questions Damilicious: a tool that helps users in sense-making, exploring diversity, and re-using semantics diversity measures when queries and result sets are different? how to best present of diversity? – How to integrate into an environment supporting user and community contexts (e.g., Niederée et al. 2005)? Incentives to use the functionalities? how to find the best balance between similarity and diversity? which measures of grouping diversity are most meaningful? – Extensional? – Intensional? Structure-based? Hybrid? (cf. ontology matching) which other sources of user diversity? Thanks!