Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
© Deloitte Consulting, 2004
Predictive Modeling for
Property-Casualty
Insurance
James Guszcza, FCAS, MAAA
Peter Wu, FCAS, MAAA
SoCal Actuarial Club
LAX
September 22, 2004
© Deloitte Consulting, 2004
Predictive Modeling:
3 Levels of Discussion
Strategy
Profitable
growth
Retain most profitable policyholders
Methodology
Model
design (actuarial)
Modeling process
Technique
GLM
vs. decision trees vs. neural nets…
2
© Deloitte Consulting, 2004
Methodology vs Technique
How does data mining need actuarial
science?
Variable creation
Model design
Model evaluation
How does actuarial science need data
mining?
Advances in computing, modeling techniques
Ideas from other fields can be applied to insurance
problems
3
© Deloitte Consulting, 2004
Semantics: DM vs PM
One connotation: Data Mining (DM) is about
knowledge discovery in large industrial databases
Data
exploration techniques (some brute
force)
e.g. discover strength of credit variables
Predictive Modeling (PM) applies statistical
techniques (like regression) after knowledge
discovery phase is completed.
Quantify
& synthesize relationships found
during knowledge discovery
e.g. build a credit model
4
© Deloitte Consulting, 2004
Strategy:
Why do Data Mining?
Think Baseball!
© Deloitte Consulting, 2004
Bay Area Baseball
In 1999 Billy Beane (manager for the Oakland
Athletics) found a novel use of data mining.
Not a wealthy team
Ranked 12th (out of 14) in payroll
How to compete with rich teams?
Beane hired a statistics whiz to analyze statistics
advocated by baseball guru Bill James
Beane was able to hire excellent players
undervalued by the market.
A year after Beane took over, the A’s ranked 2nd!
6
© Deloitte Consulting, 2004
Implication
Beane quantified how well a player would do.
Not perfectly, just better than his peers
Implication:
Be on the lookout for fields where an expert is
required to reach a decision based on
judgmentally synthesizing quantifiable information
across many dimensions.
(sound like insurance underwriting?)
Maybe a predictive model can beat the pro.
7
© Deloitte Consulting, 2004
Example
Who is worse?... And by how much?
20 y.o. driver with 1 minor violation who pays his bills
on time and was written by your best agent
Mature driver with a recent accident and has paid his
bills late a few times
Unlike the human, the algorithm knows how
much weight to give each dimension…
Classic PM strategy: build underwriting
models to achieve profitable growth.
8
© Deloitte Consulting, 2004
Keeping Score
Billy Beane
CEO who wants to run the
next Progressive
Beane’s Scouts
Underwriter
Potential Team Member
Potential Insured
Bill James’ stats
Billy Bean’s number
cruncher
Predictive variables – old
or new (e.g. credit)
You! (or people on your
team)
9
© Deloitte Consulting, 2004
What is Predictive
Modeling?
© Deloitte Consulting, 2004
Three Concepts
Scoring engines
Lift curves
A “predictive model” by any other name…
How much worse than average are the policies with
the worst scores?
Out-of-sample tests
How well will the model work in the real world?
Unbiased estimate of predictive power
11
© Deloitte Consulting, 2004
Classic Application:
Scoring Engines
Scoring engine: formula that classifies or
separates policies (or risks, accounts,
agents…) into
profitable
vs. unprofitable
Retaining vs. non-retaining…
(Non-)Linear equation f( ) of several
predictive variables
Produces continuous range of scores
score = f(X1, X2, …, XN)
12
© Deloitte Consulting, 2004
What “Powers” a Scoring
Engine?
Scoring Engine:
score = f(X1, X2, …, XN)
The X1, X2,…, XN are as important as the f( )!
Why actuarial expertise is necessary
A large part of the modeling process consists
of variable creation and selection
Usually possible to generate 100’s of variables
Steepest part of the learning curve
13
© Deloitte Consulting, 2004
Model Evaluation: Lift Curves
Sort data by score
Break the dataset into
10 equal pieces
Best “decile”: lowest
score lowest LR
Worst “decile”: highest
score highest LR
Difference: “Lift”
Lift = segmentation
power
Lift ROI of the
modeling project
14
© Deloitte Consulting, 2004
Out-of-Sample Testing
Randomly divide data into 3 pieces
Use Training data to fit models
Score the Test data to create a lift curve
Training data, Test data, Validation data
Perform the train/test steps iteratively until you have a
model you’re happy with
During this iterative phase, validation data is set aside in a
“lock box”
Once model has been finalized, score the
Validation data and produce a lift curve
Unbiased estimate of future performance
15
© Deloitte Consulting, 2004
Comparison of Techniques
All techniques work ok!
Good variable creation
at least as important as
modeling technique.
1.0
0.8
0.6
0.4
Analogous to lift curves
Good for binary target
0.2
perfect model
mars
neural net
decision tree
glm
regression
0.0
Models built to detect
whether an email
message is really
spam.
“Gains charts” from
several models
Perc.Fraud
Spam Email Detection - Gains Charts
0.0
0.2
0.4
0.6
0.8
1.0
Perc.Total
16
© Deloitte Consulting, 2004
Credit Scoring is an Example
All of these concepts apply to Credit
Scoring
Knowledge discovery in databases (KDD)
Scoring engine
Lift Curve evaluation translates to LR
improvement ROI
Blind-test validation
Credit scoring has been the insurance
industry’s segue into data mining
17
© Deloitte Consulting, 2004
Applications Beyond Credit
The classic: Profitability Scoring Model
Underwriting/Pricing applications
Retention models
Elasticity models
Cross-sell models
Lifetime Value models
Agent/agency monitoring
Target marketing
Fraud detection
Customer segmentation
no target variable (“unsupervised learning”)
18
© Deloitte Consulting, 2004
Data Sources
Company’s internal data
Policy-level records
Loss & premium transactions
Agent database
Billing
VIN……..
Externally purchased data
Credit
CLUE
MVR
Census
….
19
© Deloitte Consulting, 2004
The Predictive Modeling
Process
Early: Variable Creation
Middle: Data Exploration & Modeling
Late: Analysis & Implementation
© Deloitte Consulting, 2004
Variable Creation
Research possible data sources
Extract/purchase data
Check data for quality (QA)
Messy! (still deep in the mines)
Create Predictive and Target Variables
Opportunity to quantify tribal wisdom
…and come up with new ideas
Can be a very big task!
Steepest part of the learning curve
21
© Deloitte Consulting, 2004
Types of Predictive Variables
Behavioral
Policyholder
Age/Gender, # employees …
Policy specifics
Historical Claim, billing, credit …
Vehicle age, Construction Type …
Territorial
Census, Weather …
22
© Deloitte Consulting, 2004
Data Exploration &
Variable Transformation
1-way analyses of predictive variables
Exploratory Data Analysis (EDA)
Data Visualization
Use EDA to cap / transform predictive
variables
Extreme
values
Missing values
…etc
23
© Deloitte Consulting, 2004
Multivariate Modeling
Examine correlations among the variables
Weed out redundant, weak, poorly distributed
variables
Model design
Build candidate models
Regression/GLM
Decision Trees/MARS
Neural Networks
Select final model
24
© Deloitte Consulting, 2004
Building the Model
1.
2.
Pair down collection of predictive variables
to a manageable set
Iterative process
Build candidate models on “training data”
Evaluate on “test data”
Many things to tweak
Different target variables
Different predictive variables
Different modeling techniques
# NN nodes, hidden layers; tree splitting rules…
25
© Deloitte Consulting, 2004
Considerations
Do signs/magnitudes of parameters make
sense? Statistically significant?
Is the model biased for/against certain types
of policies? States? Policy sizes? ...
Predictive power holds up for large policies?
Continuity
Are there small changes in input values that might
produce large swings in scores
Make sure that an agent can’t game the system
26
© Deloitte Consulting, 2004
Model Analysis & Implementation
Perform model analytics
Calibrate Models
Create user-friendly “scale” – client dictates
Implement models
Necessary for client to gain comfort with the model
Programming skills are critical here
Monitor performance
Distribution of scores over time, predictiveness,
usage of model...
Plan model maintenance
27
© Deloitte Consulting, 2004
Modeling Techniques
Where Actuarial Science Needs
Data Mining
© Deloitte Consulting, 2004
The Greatest Hits
Unsupervised:
no target variable
Clustering
Principal Components (dimension reduction)
Supervised:
predict a target variable
Regression GLM
Neural Networks
MARS: Multivariate Adaptive Regression Splines
CART: Classification And Regression Trees
29
© Deloitte Consulting, 2004
Regression and its Relations
GLM: relax regression’s distributional
assumptions
Logistic regression (binary target)
Poisson regression (count target)
MARS & NN
Clever ways of automatically transforming and
interacting input variables
Why: sometimes “true” relationships aren’t linear
Universal approximators: model any functional form
CART is simplified MARS
30
© Deloitte Consulting, 2004
Neural Net Motivation
Let X1, X2, X3 be three predictive variables
Let Y be the target variable
policy age, historical LR, driver age
Loss ratio
A NNET model is a complicated, non-linear,
function φ such that:
φ(X1, X2, X3) ≈ Y
31
© Deloitte Consulting, 2004
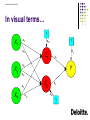
In visual terms…
1
X1
a11
a12
X2
1
b0
Z1
b1
a21
Y
a22
Z2
a31
X3
a01
a32
b2
a02
1
32
© Deloitte Consulting, 2004
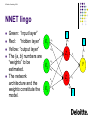
NNET lingo
Green: “input layer”
Red: “hidden layer”
X1
Yellow: “output layer”
The {a, b} numbers are
“weights” to be
X2
estimated.
The network
architecture and the
X3
weights constitute the
model.
1
a11
a12
a01
1
b0
Z1
b1
a21
Y
a22
Z2
a31
a32
b2
a02
1
33
© Deloitte Consulting, 2004
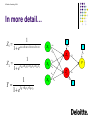
In more detail…
Z1
Z2
1
1 e
a01 b11x1 b21x2 b31x3
1
X1
a11
a12
1
1 e a02 b12x1 b22x2 b32x3
X2
Y
1
1 e
1
b0
Z1
b1
a21
Y
a22
Z2
a31
X3
a01
a32
b2
a02
1
b0 b1 z1 b2 z 2
34
© Deloitte Consulting, 2004
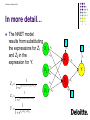
In more detail…
The NNET model
results from substituting
the expressions for Z1 X1
and Z2 in the
expression for Y.
X2
Z1
Z2
Y
1
1 e a01b11x1 b21x2 b31x3
1
1
a11
a12
1
b0
Z1
b1
a21
Y
a22
Z2
a31
X3
a01
a32
b2
a02
1
1 e a02 b12x1 b22x2 b32x3
1
1 eb0 b1z1 b2 z2
35
© Deloitte Consulting, 2004
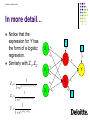
In more detail…
Notice that the
expression for Y has
the form of a logistic
regression.
Similarly with Z1, Z2.
1
X1
a12
X2
Z1
Z2
Y
1
1 e a01b11x1 b21x2 b31x3
1
a11
1
b0
Z1
b1
a21
Y
a22
Z2
a31
X3
a01
a32
b2
a02
1
1 e a02 b12x1 b22x2 b32x3
1
1 eb0 b1z1 b2 z2
36
© Deloitte Consulting, 2004
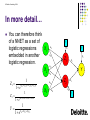
In more detail…
You can therefore think
of a NNET as a set of
logistic regressions
X1
embedded in another
logistic regression.
X2
Z1
Z2
Y
1
1 e a01b11x1 b21x2 b31x3
1
1
a11
a12
1
b0
Z1
b1
a21
Y
a22
Z2
a31
X3
a01
a32
b2
a02
1
1 e a02 b12x1 b22x2 b32x3
1
1 eb0 b1z1 b2 z2
37
© Deloitte Consulting, 2004
Universal Approximators
The essential idea: by layering several
logistic regressions in this way…
…we can model any functional form
no matter how many non-linearities or
interactions between variables X1, X2,…
by varying # of nodes and training cycles only
NNETs are sometimes called “universal
function approximators”.
38
© Deloitte Consulting, 2004
MARS / CART Motivation
NNETs use the logistic function to combine variables
and automatically model any functional form
MARS uses an analogous clever idea to do the
same work
MARS “basis functions”
CART can be viewed as simplified MARS
Basis functions are horizontal step functions
NNETS, MARS, and CART are all cousins of
classic regression analysis
39
© Deloitte Consulting, 2004
Reference
For Beginners:
Data Mining Techniques
--Michael Berry & Gordon Linhoff
For Mavens:
The Elements of Statistical Learning
--Jerome Friedman, Trevor Hastie, Robert Tibshirani
40