Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
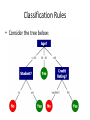
Issues Related to Decision Tree CIT365: Data Mining & Data Warehousing Bajuna Salehe The Institute of Finance Management: Computing and IT Dept. Which Splitting Test Condition? • This depends on the attribute types – Nominal – Ordinal – Continuous (interval/ratio) • It also depends of ways to split – 2 – way (Binary) split – Multi-way split Nominal Attributes • Since a nominal attribute can produced many values, its test condition can be expressed in two ways, as shown in Figure below Nominal Attributes • For multi-way split, the number of outcomes depends on the number of distinct values for the corresponding attribute. • For example, if an attribute such as marital status has three distinct values — single, married, or divorced — its test condition will produce a three-way split, as shown in Figure 2 below: Nominal Attributes • Multi – way split uses as many partitions as distinct values Binary Split • Divides values into two subsets • Must find optimal partitioning • e.g. C(3,2) = 3 possibilities. Diagram below depicts this Ordinal Attributes • Ordinal attributes may also produce binary or multi-way splits. • Grouping of ordinal attribute values is also allowed as long as it does not violate the implicit order property among the attribute values. • Example of grouping shirt-size attribute is shown in the diagram below Ordinal Attributes • The groupings shown in Figures (a) and (b) preserve the order among the attribute values whereas the grouping shown in Figure (c) violate such property because it combines the attribute values Small and Large into the same partition while Medium and Extra Large into another. Splitting Continuous Attributes • Discretization—Convert to ordinal attribute. Example for continuous attributes, the test condition can be expressed as a comparison test (A < v?) or (A ≥ v?) with binary outcomes as shown in the diagram below When to Stop Splitting? • Stop expanding when – All records belong to same class – All records have “similar” attribute values Classification Rules • Represent the knowledge in the form of IFTHEN rules • One rule is created for each path from the root to a leaf • Each attribute-value pair along a path forms a conjunction • The leaf node holds the class prediction Classification Rules • Consider the tree below: Classification Rules • Rules are easier for humans to understand • Example from above tree, the rules would be: IF age = “<=30” AND student = “no” THEN buys_computer = “no” IF age = “<=30” AND student = “yes” THEN buys_computer = “yes” IF age = “31…40” THEN buys_computer = “yes” IF age = “>40” AND credit_rating = “excellent” THEN buys_computer = “yes” IF age = “<=30” AND credit_rating = “fair” THEN buys_computer = “no” Why Decision Tree Classifier? • Inexpensive to train/construct • Extremely FAST @ classifying unknown records – Linear in # attributes • Easy to interpret for small trees Why Decision Tree Classifier? • Accuracy comparable to other classification techniques for many simple data sets • Example: C4.5 – Simple Depth-first construction – Uses Information Gain (entropy) – Sorts Continuous Attributes @ each node – Data must fit in memory! • unsuitable for large datasets • needs out-of-core sorting Decision Boundary 1 0.9 x < 0.43? 0.8 0.7 Yes No y 0.6 y < 0.33? y < 0.47? 0.5 0.4 Yes 0.3 0.2 :4 :0 0.1 No :0 :4 Yes :0 :3 0 0 0.1 0.2 0.3 0.4 0.5 x 0.6 0.7 0.8 0.9 1 • Border line between two neighboring regions of different classes is known as decision boundary • Decision boundary is parallel to axes because test condition involves a single attribute at-a-time No :4 :0 Classification Issues • Underfitting and Overfitting • Missing Values • Costs of Classification Model Underfitting/Overfitting • The errors of a classification model are divided into two types – Training errors: the number of misclassification errors committed on training records. – Generalization errors: the expected error of the model on previously unseen records. • A good model must have both errors low. • Model underfitting: both type of errors are large when the decision tree is too small. • Model overfitting: training error is small but generalization error is large, when the decision tree is too large. Underfitting and Overfitting (Example) 500 circular and 500 triangular data points. Circular points: 0.5 sqrt(x12+x22) 1 Triangular points: sqrt(x12+x22) > 0.5 or sqrt(x12+x22) < 1 Underfitting and Overfitting Overfitting Underfitting: when model is too simple, both training and test errors are large An Example: Training Dataset An Example: Testing Dataset An Example: Two Models, M1 and M2 0% training error 30% testing error 20% training error 10% testing error (human, warm-blooded, yes, no, no) (dolphin, warm-blooded, yes, no, no) (spiny anteater, warm-blooded, no, yes, yes) Overfitting due to Insufficient Examples Lack of data points in the lower half of the diagram makes it difficult to predict correctly the class labels of that region - Insufficient number of training records in the region causes the decision tree to predict the test examples using other training records that are irrelevant to the classification task An Example: A Smaller Training Dataset The training dataset does not provide enough information. All warm-blooded vertebrates that do not hibernate are nonmammals. An Example: A Model for Table 4.5 0% training error 30% testing error (human, warm-blooded, yes, no, no) (dolphin, warm-blooded, yes, no, no) Notes on Overfitting • Overfitting results in decision trees that are more complex than necessary • Training error no longer provides a good estimate of how well the tree will perform on previously unseen records • Need new ways for estimating generalization errors – We cannot use a tree with smaller training error to reduce generalization errors! How to Address Overfitting • Pre-Pruning (Early Stopping Rule) – Stop the algorithm before it becomes a fully-grown tree – Typical stopping conditions for a node: • Stop if all instances belong to the same class • Stop if all the attribute values are the same – More restrictive conditions: • Stop if number of instances is less than some userspecified threshold • Stop if class distribution of instances are independent of the available features (e.g., using 2 test) • Stop if expanding the current node does not improve impurity measures (e.g., Gini or information gain). How to Address Overfitting (Con’d) • Post-pruning – Grow decision tree to its entirety – Trim the nodes of the decision tree in a bottom-up fashion – If generalization error improves after trimming, replace sub-tree by a leaf node. – Class label of leaf node is determined from majority class of instances in the sub-tree Avoiding Overfitting In Classification • An induced tree may overfit the training data – Too many branches, some may reflect anomalies due to noise or outliers – Poor accuracy for unseen samples • Two approaches to avoiding overfitting – Prepruning: Halt tree construction early • Do not split a node if this would result in a measure of the usefullness of the tree falling below a threshold • Difficult to choose an appropriate threshold – Postpruning: Remove branches from a “fully grown” tree to give a sequence of progressively pruned trees • Use a set of data different from the training data to decide which is the “best pruned tree” Model Evaluation • Metrics for Performance Evaluation – How to evaluate the performance of a model? • Methods for Performance Evaluation – How to obtain reliable estimates? • Methods for Model Comparison – How to compare the relative performance among competing models? Metrics for Performance Evaluation • Focus on the predictive capability of a model – Rather than how fast it takes to classify or build models, scalability, etc. • Confusion Matrix: PREDICTED CLASS a: TP (true positive) Class=Yes Class=No ACTUAL Class=Yes CLASS Class=No a b c d b: FN (false negative) c: FP (false positive) d: TN (true negative) Metrics for Performance Evaluation (Con’d) PREDICTED CLASS Class=Yes ACTUAL CLASS Class=No Class=Yes a (TP) b (FN) Class=No c (FP) d (TN) ad TP TN Accuracy a b c d TP TN FP FN • Most widely-used metric: Missing Values • In practice, the data set may contain missing attribute values due to the following reasons. – Some attributes may be costly to measure. E.g., certain medical tests may be far too expensive to be performed on every patient. As a result, the medical record for some patients may not contain the results of such tests. – Second, some attribute values may be untrustworthy. E.g., measurements taken from a known faulty sensor are often invalid, and thus, should be ignored. Missing Values – Third, some attributes may be optional. An attribute such as customer satisfaction, for example, may be applicable only to those customers who have prior experience using the services of a company. • Missing values may affect the performance of classification models if not handled appropriately. Missing Values • One of the approach that can be used for handling missing values is to completely ignore records with missing values. • However this approach may not be desirable especially if the number of training records is limited. Summary • Classification is an extensively studied problem • Classification is probably one of the most widely used data mining techniques with a lot of extensions • Classification techniques can be categorized as either lazy or eager Summary • Scalability is still an important issue for database applications: thus combining classification with database techniques should be a promising topic • Research directions: classification of nonrelational data, e.g., text, spatial, multimedia, etc. classification of skewed data sets