Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
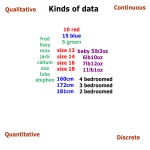
TYPES OF (RANDOM) VARIABLES
Categorical (Nominal) Variables
Ordinal Variables:
A natural order, but the measure of distance not defined / imprecise
/ arbitrary
(e.g. rate on a scale of 1-10 the quality of this your teacher)
Interval Variables:
favorite color: red,blue, sky blue, orange )
No natural order, no clear distance measure
Usually random variables with real number values
Natural order, and clear-defined measure of distance
Ratio Variables:
Similar to Interval variables, but with a lower value limit at 0.0
NOTE: We will not make a formal distinction between the last two,
rather one should be aware of the physical meaning of the values:
e.g. temperatures expressed in F or C would be Interval variables;
expressed in Kelvin, they qualify for Ratio Variables
But still for our statistical analysis it wouldn’t make a difference (far away from 0K)
DESCRIPTION OF RANDOM DATA
SAMPLES (REAL-VALUED VARIABLES)
(Random data that can be sorted by size)
•
Sample Size
•
Center or location of the sample
•
Measure of the range of the sample
•
Symmetry of the sample distribution
•
(sometimes the range of possible outcomes of the
random process is well-known by physical constraints)
MEASURE FOR THE
CENTER OF THE SAMPLE
Arithmetic mean:
x
x
Summed up
i
i
MEASURE FOR THE
RANGE OF THE SAMPLE
Standard deviation:
x
“Bessel Correction:” gives an unbiased
estimate.
i
MEASURE FOR THE
RANGE OF THE SAMPLE
Variance:
x
Again: You often find the denominator
(n-1) instead for an unbiased estimate
i
R-COMMANDS
mean(x)
var(x) (R uses the Bessel Correction (n-1))
sd(x)
summary(x) is a more general function that gives a
statistical summary of the data
Example:
summary(c(1,2,42,3,24,52))
returns
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 2.25 13.50 20.67 37.50 52.00
R COMMANDS
Median(x) is another measure of the data’s center point
When you sort the data sample in ascending order, you
find the mid-point of the sample:
Example:
x<-c(1,2,3,2,5,62)
median(x) returns 2.5
mean(x) returns 12.5
We see the mean is not robust against outliers in the
sample, but the median give a robust result.
R COMMANDS
Imagine,
we did a small typo in the last example,
and the real data sample had seven elements
x<-c(1,2,3,2,5,6,2)
median(x) returns 2
mean(x) returns 3
QUARTILES AND QUANTILES
Similar to finding the median of the sample data, one
can define the lower and upper quartiles of the data
sample
That is, you sort the data x in ascending order
{x1, x2, x3, … , xn} are ordered data with xi indicating the ith smallest data
if you have for example 100 data then the lower quartile
value is closest to (or interpolated between the closest
ranks) the position i such that 25% of the values are
lower than the quartile value xi=26
The upper quantile would be at xi=76
QUARTILES AND QUANTILES
In small sample sizes and the even and odd
samples sizes require modification to the
estimation of median and quartiles
In general: with large sample size
one can sort the data and use the probability
estimate for the chances of exceeding a certain
value in the sorted sample:
Let n be your sample size (say n=1000)
then the p-th quantile is the value (in the same units of
your sample data {xi, i=1,2,…,n}) that exceeds the
values of your sample with a probability of p
QUANTILES
n samples
x
p-th quantile value:
qp
k
Sample data
sorted in ascending
order
p=k/n
0<= p <= 1
Rank i
R COMMANDS
Visualization of data samples:
hist(x)
Albany Airport January 2014
daily mean temperatures [F]
histogram. Sample size with n=31
is small. We count the number of days
with temperatures in a certain range
(bins).
Instructions for R:
Run script albany2.R
after running script execute:
hist(tday)
R COMMANDS
Visualization of data samples:
boxplot(x)
Albany Airport January 2014
daily mean, min. and max. temperatures [F]
We count the number of days
with temperatures in a certain range
(bins).
R instructions:
(make sure you have run script albany2.R)
Execute:
boxplot(list(tmin=jan$MIN,tavg=tday,tmax=jan$MAX))
Note: boxplot is best used if you want to compare two or more sample distributions visually.
To achieve that, boxplot is given a list of data, each data sample get’s it’s own name in the list of data, and boxplot
creates for each named data set of the list it’s own boxplot diagram)
BOXPLOT:
max(tmin)
Upper quartile
median
Lower quartile
min(tmin)
Note: Different flavors of boxplots circulate around. Oftentimes ‘outliers’ are plotted as extra dots, and the
boxplot symbols are caculated without the outliers.