Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
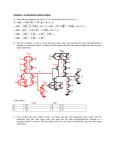
A 32-bit Kogge-Stone Adder using Pulsed-Static CMOS (PS-CMOS) with a Self-Timed Clock Seng Oon Toh, Daniel Huang, Jan Rabaey University of California, Berkeley Department of Electrical Engineering and Computer Sciences Abstract With the increasing trend towards on-chip level parallelism such as multi-core designs, die sizes are getting bigger. These increasing die sizes cause the chip to have a greater susceptibility to process variations. Rather than clocking a chip based on the worst case clock frequency of one of the parallel components, it would be advantageous if a scheme was designed such that all parallel blocks would operate at their own optimum speed. This would increase throughput of the chip as all parallel components are operating at optimum frequency. Yield is also increased as dies with defective parallel blocks could still be used with these blocks running at lower frequencies while other blocks remain at their optimal frequency. As a stepping stone to accomplishing this, we would like to use pulsed-static CMOS (PSCMOS) to create to create high radix Kogge-Stone parallel prefix adder with a self-calibrating clock. The ALU would have the capability of sending out a completion flag which would be used to calibrate the clock generator. A state machine will then be designed to calibrate the clock during power up. The viability of a self-clocked ALU could then be the foundation for further research at the system level to determine a means of utilizing these self-clocked ALU blocks efficiently. Introduction With the increasing trend towards on-chip level parallelism such as multi-core designs, die sizes are getting bigger. These increasing die sizes cause the chip to have a greater susceptibility to process variations. Rather than clocking a chip based on the worst case clock frequency of one of the parallel components, it would be advantageous if a scheme was designed such that all parallel blocks would operate at their own optimum speed Currently clocks are optimized for the critical path of the circuit. The use of a single clock requires the whole circuit to run at the same frequency, which is wasteful and energy inefficient. Another challenge that occurs as a result of a synchronous clock is being able to properly distribute a high speed clock throughout the whole chip efficiently. The obvious choice of using an asynchronous clock design for digital circuits has been under investigation for quite sometime. It has the disadvantage of complexity of design, but has the benefits of being able to address the problems of a synchronous high speed clock. The over all win of the asynchronous clock is a low power design with high performance. One way to implement an asynchronous clock is to have globally asynchronous locally synchronous systems (GALS) [1]. This scheme uses multiple clocks in the chip. The chip is split in to multiple blocks with each block running at its optimal frequency. In order for GALS to operate properly a proper clock needs to be calibrated for each block. One idea is to generate the clock through a calibrated delay line in each separate clock. The delay line is then governed by a global clock [1]. Another scheme is the use of a self-timed circuit, where different parts of the circuit will determine its own clock frequency. In order for this scheme to work a completion signal needs to be generated to tell the next part of the circuit to run. The generation of the completion signal is rather tricky. The annoying need of the completion signal has caused some people to attempt to forgo it completely using DCVS logic [2]. In this paper we will rather stick with the self-timed scheme where the generation of a completion signal is necessary. One question that may occur is the choice of logic styles. For logic styles one of the most robust designs for digital circuits is static logic. It is easy to design with and easy and relatively power efficient. For performance driven application the obvious choice becomes dynamic logic. Dynamic logic however has problems of its own. For one it needs to be frequently coupled with static gates because of the risk of clock feed through. The benefits of dynamic logic and static logic and be realized using pulsed static CMOS. Pulsed static CMOS also solves many of the problems involved with both dynamic and static logic [3]. Nothing of great advantage comes without a price. Pulsed static CMOS require more careful logic design and consideration than a purely static or dynamic logic style will require. In this paper we would like to present the possibility of using a pulsed-static CMOS with a self-timed scheme. We will implement a 32-bit Kogge-Stone pipelined adder, where the clock speed will be determined by selftiming. An appropriate completion signal scheme will be used for our self-timed 32-bit adder. We will have an analysis of the performance and benefits of using this particular scheme. Pulsed Static CMOS (PS-CMOS) PS-CMOS is a very attractive logic family. Like domino logic, nodes between complex gates are precharged to a pre-determined level. Evaluation of input signals then occur through the circuit, starting from the input, with each node either remaining at its pre-charged state or being pulled down or pulled up through NMOS or PMOS networks. Since the evaluate transitions are monotonic, the pull-down or pull-up networks can be skewed for minimized evaluate delays. Circuit design of PS-CMOS is much more straightforward compared to domino logic because PS-CMOS is not affected by issues such as charge-sharing and capacitive coupling. Rules of PS-CMOS design can also be relaxed to allow cascading of gates that have similar evaluate directions because PS-CMOS has DC restoration. Since PS-CMOS does not rely on capacitive storage, it is therefore less susceptible to process variation. The standard deviation of path delays of a PS-CMOS circuit will be much closer to the mean path delay. This reduces the number of paths that need to be evaluated to get an estimate of the average time for completion of calculation. Although PSCMOS requires more area compared to domino logic, this overhead is not that significant as the pre-charge networks can be minimum sized. This overhead is also comparable to the extra transistors used by domino logic for footers, charge keepers, and charge injectors. In ideal PS-CMOS design, NAND and NOR gates are placed one after another to implement the circuit. Inputs are latched into the circuit using a tri-state latch that pre-conditions the circuit to its pre-charge state. Ideally, NAND gate inputs should be pre-conditioned high while NOR gate inputs should be pre-conditioned low. A typical PS-CMOS circuit is shown in Fig. 1 [7]. Fig. 1: PS-CMOS Circuit with Input Latch This scheme allows shortest evaluate cycles and immunity to signal arrival times because the evaluate cycle only exercises the pull-up or pull-down network with parallel connected transistors. The actual inputs are then passed into the circuit during the evaluate cycle and moves to the output like a pulse or falling dominos. This strict requirement of successive NAND and NOR gates limit the use of PS-CMOS in practical designs. A circuit also might not naturally pre-charge to a state where all inputs are at the same level. A workaround to this limitation is to duplicate the tri-state latches at the inputs such that all the nodes in the circuit are pre-charged to the same level [2]. This implementation also relaxes on the strict requirement of successive NAND and NOR gates. The circuit still runs faster than static CMOS because the monotonic transitions allow for skewing of gates for optimum evaluate transitions. There is also an extra penalty in area due to the need of duplicating the input latches. We will be considering an alternative to this method by pipelining our design and dividing the stages at the boundaries of the gates that would normally pre-charge to different levels in a non-pipelined design. This way, the area cost of the duplicated latches is amortized into the area cost of the pipeline registers. Such a scheme might also allow us to implement our adder using pure PS-CMOS with successive NAND and NOR gates. PS-CMOS not only provides faster operation but also is inherently glitch free due to its monotonic transitions. This is beneficial from the standpoint of completion signal generation because the time required for computation is just the duration for an input signal to cause a transition at the output of a circuit. Adder Design We propose to implement a pipelined 32-bit KoggeStone adder using PS-CMOS. Since a 32-bit adder can be considered as a substantial computational block, it fits the objective of this paper, in which we are trying to develop a way of running parallel computational blocks at their optimum speed, depending on process variations. Such a wide adder will also provide us a sufficient variety of paths to be monitored for completion signal. Fig. 2 illustrates an adder structure for a Kogge-Stone adder with radix of 2 [5]. This design has a radix of 2 because group carry-lookaheads are computed considering two groups in each stage. variations. This can be accomplished without the need of going into a special calibration state by looking for input patterns that will cause a transition at the output. Clock Generation Fig. 2: Radix-2 Kogge-Stone Adder Structure We picked a logarithmic carry look-ahead adder (CLA) instead of other designs because this style of adders can be conveniently pipelined based on the groupcarry dot operator stages. The pipeline depth is also minimal [4] with a significant amount of logic depth in each stage which could make use of the speedup from PS-CMOS. We will also consider Kogge-Stone adders of higher radix [5] to determine which design is optimal for PS-CMOS and pipelining. The pull-up and pull-down networks will also be sized for a pre-charge cycle that is 1.5x the evaluate cycle. Clock generation is beyond the scope of this paper. We assume that there will be a high frequency clock available that will clock a counter that measures the propagation delay. The value of this counter will then be used by a local clock generator to clock the adder. The clock signal also needs to have a pre-charge duty cycle that is 1.5x the evaluate duty cycle. Implementation Our pipelined adder design will first be implemented in Verilog to ensure that the adder functions correctly. A SPICE simulation will then be carried out to determine the actual propagation delay of the circuit as a means to check the accuracy of the optimal clock frequency estimated by our completion signal generation scheme. Process variations will then be simulated by modifying parameters of transistors in the adder. This will be used to determine the capability of our design in adapting the clock to process variations. Completion Signal References Measuring of propagation delay will be carried out by observing the duration an input signal takes to cause a transition at the output. This is possible with PS-CMOS because output transitions are monotonic. Our decision to generate a completion signal from the actual circuit comes from our desire to run the computational block at its optimal speed. Other techniques such as critical path replica with padded inverters [6] only attempt to clock the circuit based on performance at the corners of the design which could be significantly more than the optimal speed. The pipelined adder will be designed such that the stages share an equal load of logic depth. A completion signal will then be observed at the stage with the biggest logic depth. In the case where multiple stages share the same logic depth, completion signals will be generated from the different stages and compared to get the worstcase stage delay. During initial circuit start-up, the optimal operating frequency of the adder will be measured by sending in an input pattern that will exercise a worst-case transition at one of the outputs of a pipeline stage. This should be sufficient to calibrate the local clock of the adder such that the block is running at its optimal frequency. If desired, the local clock generator can be designed to continuously monitor the propagation delay of the circuit so that the optimal frequency tracks environment [1] S. W. Moore, G. S. Taylor, Self Calibrating Clocks for Globally Asynchronous Locally Synchronous Systems, IEEE, 2003, 73-78. [2] Sanu Mthew, R. Sridhar, Data-driven Self-timed Differential Cascode Voltage Swithch Logic, IEEE, 1998. [3] Kavitha Seshadri, Adrianne Pontarelli, Gauri Joglekar and Gerald E. Sobelman, Design Techniques for pulsed static CMOS, ISCAS '04. Proceedings of the 2004 International Symposium on, 2004, 929-932. [4] Unwala, I.H.; Swartzlander, E.E., Jr., Superpipelined adder designs, ISCAS '93, 1993 IEEE International Symposium on, Vol. 3, 1993, 1841-1844. [5] Gurkayna, F.K.; Leblebicit, Y.; Chaouati, L.; McGuinness, P.J., Higher radix Kogge-Stone parallel prefix adder architectures, ISCAS 2000 Geneva. The 2000 IEEE International Symposium on, Vol. 5, 2000, 609-612 [6] Uht, A.K., Uniprocessor performance enhancement through adaptive clock frequency control, Computers, IEEE Transactions on, Vol.54, Iss.2, Feb. 2005, 132-140. [7] Chih-Liang Chen and Gary S. Ditlow, Pulsed Static CMOS Circuit, U.S. Patent No. 5,495,188, February 27, 1996.