Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Protection Act, 2012 wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Data center wikipedia , lookup
Data analysis wikipedia , lookup
Forecasting wikipedia , lookup
3D optical data storage wikipedia , lookup
Business intelligence wikipedia , lookup
Information privacy law wikipedia , lookup
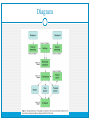
Data Matching CONCEPTS AND TECHNIQUES FOR RECORD LINKAGE, ENTITY RESOLUTION, AND DUPLICATE DETECTION BY PETER CHRISTEN PRESENTED BY JOSEPH PARK Introduction “Data matching is the task of identifying, matching, and merging records that correspond to the same entities from several databases” Also known as: Record or data linkage Entity resolution Object identification Field matching Aims & Challenges Three tasks: Schema matching Data matching Data fusion Challenges: Lack of unique entity identifier and data quality Computation complexity Lack of training data (e.g. gold standards) Privacy and confidentiality (health informatics & data mining) Overview of Data Matching Five major steps: Data pre-processing Indexing Record pair comparison Classification Evaluation Diagram Data Pre-processing Remove unwanted characters and words Expand abbreviations and correct misspellings Segment attributes into well-defined and consistent output attributes Verify the correctness of attribute values Example of Data Pre-processing Indexing Reduces computational complexity Generates candidate record pairs Common technique—Blocking Example of Blocking Record Pair Comparison Comparison vector – vector of numerical similarity values Example of Record Pair Comparison Jaro and Winkler String Comparison Jaro: Combines edit distance and q-gram based comparison Winkler: Increases Jaro similarity for up to four agreeing initial chars Record Pair Classification Two-class or three-class classification: Match or non-match Match or non-match or potential match (requires clerical review) Supervised and unsupervised Active learning Example of Record Pair Classification Unsupervised Classification Threshold-based classification Probabilistic classification Cost-based classification Rule-based classification Clustering-based classification Probabilistic Classification Three-class based Different weights assigned to different attributes Newcombe & Kennedy – cardinalities Comparison vectors, binary comparison Conditionally independent attributes assumed Formulae Example of Probabilistic Classification Active Learning Trains a model with small set of seed data Classifies comparison vectors not in training set as matches or non-matches Asks users for help on the most difficult to classify Adds manually classified to training data set Trains the next, improved, classification model Repeats until stopping criteria met