Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
STT 315
Ashwini Maurya
This lecture is based on Chapter 4.6-4.11.
Acknowledgement: Author is thankful to Dr. Ashok Sinha, Dr. Jennifer Kaplan and Dr.
Parthanil Roy for allowing him to use/edit some of their slides.
Normal Distribution
2
Normal random variable
A normal random variable X
– is a continuous random variable
– has a probability distribution which is bell-shaped,
i.e.,
• unimodal,
• symmetric.
• In many data-sets, the histogram is bell-shaped.
These data-sets can be modeled using normal
distribution.
3
Normal distribution
• Normal distribution is identified by its mean (𝜇) and
standard deviation (𝜎).
• The form of the normal curve [probability density
function] is defined for all real x, i.e. −∞ < 𝑥 < ∞,
2
(𝑥−𝜇)
1
−
𝑓 𝑥 =
𝑒 2𝜎2 ,
𝜎 2𝜋
where 𝜋 = 3.1415 … and 𝑒 = 2.71828 …
• A normal random variable with 𝜇 = 0, 𝜎 = 1 is called
a standard normal random variable.
• If X is normal with mean mean (𝜇) and standard
𝑋−𝜇
deviation 𝜎 , then 𝑍 =
is standard normal.
𝜎
4
Computing normal probabilities
• Since normal random variable is continuous
𝑃 𝑋 = 𝑥 = 0 for all 𝑥.
• Thus for any two numbers 𝑎 and 𝑏,
𝑃 𝑎<𝑋<𝑏 =𝑃 𝑎<𝑋≤𝑏 =𝑃 𝑎≤𝑋<𝑏
=𝑃 𝑎≤𝑋≤𝑏 .
• We shall use TI 83/84 for computation.
• We generally face two type of problems:
– To compute 𝑃 𝑎 < 𝑋 < 𝑏 [use normalcdf];
– Given the value of 𝑝 finding 𝑥 such that 𝑝 = 𝑃 𝑋 ≤ 𝑥
[use invNorm].
5
Approximately what percent of U.S. women do you expect to
be between 66 in and 67 in tall?
•
Heights of adult women are normally distributed with
– mean of 63.6 in,
– standard deviation of 2.5 in.
Use TI 83/84 Plus.
– Press [2nd] & [VARS] (i.e. [DISTR])
– Select 2: normalcdf
– Format of command:
normalcdf(lower bound, upper bound, mean, std.dev.)
For this problem: normalcdf(66, 67, 63.6, 2.5) = 0.0816.
i.e. about 8.2% of adult U.S. women have heights between 66 in
and 67 in.
6
Approximately what percent of U.S. women do you expect to
be less than 64 in tall?
•
•
•
Heights of adult women are normally distributed with
– mean of 63.6 in,
– standard deviation of 2.5 in.
Note that here upper bound is 64, but there is no mention
of lower bound.
So take a very small value for lower bound, say -1000.
For this problem
normalcdf(-1000, 64, 63.6, 2.5) = 0.5636.
i.e. about 56.4% of adult U.S. women have heights less than 64
in.
7
Approximately what percent of U.S. women do you expect to
be more than 58 in tall?
•
•
•
Heights of adult women are normally distributed with
– mean of 63.6 in,
– standard deviation of 2.5 in.
Note that here lower bound is 58, but there is no mention
of upper bound.
So take a very high value for upper bound, say 1000.
For this problem
normalcdf(58, 1000, 63.6, 2.5) = 0.987.
i.e. 98.7% of adult U.S. women have heights more than 58 in.
8
What about men’s height?
• Heights of adult men are normally distributed with
– mean of 69 in,
– standard deviation of 2.8 in.
• normalcdf(60, 1000, 69, 2.8) = 0.999.
Hence 99.9% adult male will have height more than 60 in.
• normalcdf(64, 1000, 69, 2.8) = 0.963.
So 96.3% adult male will have height more than 64 in.
• Thus for U.S. Army height restriction for women is more
restrictive compared to men.
• But for U.S. Marine height restriction for men is more
restrictive compared to women.
9
Below what height 80% of U.S. men do have their heights?
•
Heights of adult men are normally distributed with
– mean of 69 in,
– standard deviation of 2.8 in.
•
The question is to find the height x such that
{Percent of men’s height < x} = 80% = 0.8.
Use TI 83/84 Plus.
– Press [2nd] & [VARS] (i.e. [DISTR])
– Select 3: invNorm
– Format of command:
invNorm(fraction, mean, std.dev.)
For this problem: invNorm(0.8, 69, 2.8) = 71.36.
i.e. 80% of U.S. men have heights less than 71.36 in.
10
Remark: invNorm
• invNorm only considers percentage or fraction in the lower
tail of normal distribution.
• For example, suppose the question is
“Above what height 10% of U.S. men
do have their heights?”
Notice here the question is find the height x such that
{Percent of men’s height > x} = 10% = 0.1.
This means
{Percent of men’s height < x} = (100-10)% = 90% = 0.9.
For this problem: invNorm(0.9, 69, 2.8) = 72.59.
i.e. 90% of U.S. men have heights less than 72.59 in,
i.e. 10% of U.S. men have heights more than 72.59 in.
11
Normal approximation of binomial distribution
Suppose 𝑋~𝐵𝑖𝑛 𝑛, 𝑝 . Hence μ = 𝑛𝑝, 𝜎 𝑋 = 𝑛𝑝𝑞.
If n is very large, then the probability distribution of X
can be approximated by normal distribution with μ =
𝑛𝑝, 𝜎 𝑋 = 𝑛𝑝𝑞.
However, X being binomially distributed is a discrete
random variable, whereas normal distribution is
continuous. So we need a continuity correction.
If n is very large, then we compute as follows:
𝑃 𝐵𝑖𝑛 𝑛, 𝑝 𝑟. 𝑣. ≤ 𝑥
≈ 𝑃 𝑁 𝑛𝑝, 𝑛𝑝𝑞 𝑟. 𝑣. ≤ 𝑥 + 0.5 .
12
How large n should be?
To apply normal approximation to binomial
distribution n should be so large that the
interval
𝑛𝑝 ± 3 𝑛𝑝𝑞
should lie in the range 0 and 𝑛.
13
Example
Let X be binomially distributed with 𝑛 = 50, 𝑝 = 0.2.
Here μ = 𝑛𝑝 = 10, 𝜎 = 𝑛𝑝𝑞 = 2.828.
Thus 𝑛𝑝 ± 3 𝑛𝑝𝑞 = 1.515, 18.49 , which lies in the range 0 and
𝑛 = 50. Hence n is large enough.
• 𝑃 𝑋 ≤ 16 ≈ 𝑃 𝑁 10, 2.828 ≤ 16.5 =
𝑛𝑜𝑟𝑚𝑎𝑙𝑐𝑑𝑓 −100, 16.5, 10, 2.828 = 0.9892.
• 𝑃 𝑋 < 16 = 𝑃(𝑋 ≤ 15) ≈ 𝑃 𝑁 10, 2.828 ≤ 15.5 =
𝑛𝑜𝑟𝑚𝑎𝑙𝑐𝑑𝑓 −100, 15.5, 10, 2.828 = 0.9741.
• 𝑃 𝑋 = 16 = 𝑃 𝑋 ≤ 16 − 𝑃 𝑋 < 16 ≈ 0.9892 − 0.9741 =
0.0151.
• 𝑃 𝑋 > 12 = 1 − 𝑃 𝑋 ≤ 12 ≈ 1 − 𝑃 𝑁 10, 2.828 ≤ 12.5 =
1 − 𝑛𝑜𝑟𝑚𝑎𝑙𝑐𝑑𝑓 −100, 12.5, 10, 2.828 = 0.1883.
• 𝑃 𝑋 ≥ 12 = 1 − 𝑃 𝑋 < 12 = 1 − 𝑃 𝑋 ≤ 11 ≈
1 − 𝑛𝑜𝑟𝑚𝑎𝑙𝑐𝑑𝑓 −100, 11.5, 10, 2.828 = 0.2979.
14
Example
Suppose X is normally distributed with mean 𝜇 and
standard deviation 𝜎. What is the probability that the
value of X will be within 1.5 standard deviation from
the mean? i.e. 𝑃 𝜇 − 1.5𝜎 ≤ 𝑋 ≤ 𝜇 + 1.5𝜎 =?
𝑋−𝜇
Solution: Remember that 𝑍 =
is standard normal.
𝜎
𝜇−1.5𝜎 −𝜇
The z-score of 𝜇 − 1.5𝜎 is =
= −1.5 and
𝜎
𝜇+1.5𝜎 −𝜇
the z-score of 𝜇 + 1.5𝜎 is =
= 1.5.
𝜎
So, 𝑃 𝜇 − 1.5𝜎 ≤ 𝑋 ≤ 𝜇 + 1.5𝜎 = 𝑃(−1.5 ≤ 𝑍 ≤
15
Sum of independent random
variables
16
Combining Random Variables
• Let X and Y be two random variables. Then
𝐸(𝑋 ± 𝑌) = 𝐸(𝑋) ± 𝐸(𝑌).
• If further X and Y are independent, then
𝑉(𝑋 ± 𝑌) = 𝑉(𝑋) + 𝑉(𝑌).
• Notice that for variance both have a “plus” sign on
the right hand side.
• For expectation, “independence” assumption is not
necessary, but for the above variance formula it is
required.
• Variance for “dependent” case will not be treated in
this course.
17
Example
• Suppose X and Y are two independent random
variables with
E(X) = 4, V(X) = 2, E(Y) = -3, V(Y) = 4.
• Then
E(X+Y) = E(X)+E(Y) = 4+(-3) = 1.
V(X+Y) = V(X)+V(Y) = 2+4 = 6.
σ(X+Y) = std. dev. of (X+Y) = √V(X+Y) = √6 = 2.45.
E(X-Y) = E(X)-E(Y) = 4-(-3) = 7.
V(X-Y) = V(X)+V(Y) = 2+4 = 6.
σ(X-Y) = std. dev. of (X-Y) = 𝑉(𝑋 − 𝑌) = 6 =
2.45.
18
Example
• Suppose X and Y are two independent random
variables with
E(X) = 4, V(X) = 2, E(Y) = -3, V(Y) = 4.
• Then
E(3X-2Y)
= E(3X) - E(2Y)
= 3E(X) - 2E(Y)
= 3×4 - 2×(-3)
= 12 + 6 = 18.
19
Example
• Suppose X and Y are two independent random
variables with
E(X) = 4, V(X) = 2, E(Y) = -3, V(Y) = 4.
• Then
V(3X-2Y)
= V(3X) + V(2Y)
= 32V(X) + 22V(Y)
= 9×2 + 4×4
= 18 + 16 = 34.
σ(3X-2Y) = std. dev. of (3X-2Y) = √V(3X-2Y) = √34 =
5.83.
20
Example
These formulas can be extended to more than two random
variables.
Suppose we have the following information about random
variables X, Y and Z.
• X, Y and Z are independent, and
Random
variables
Expectations
Variances
X
-4
2
Y
2
6
Z
9
4
• E(X + Y - Z) = E(X) + E(Y) – E(Z) = (-4) + 2 – 9 = -11.
• V(X + Y - Z) = V(X) + V(Y) + V(Z) = 2 + 6 + 4 = 12.
• σ(X + Y - Z) = 12 = 3.464.
21
Another Example
Suppose X, Y and Z are independent, and
Random
variables
Expectations
Standard
deviations
X
0
1
Y
0.2
3
Z
2.4
5
Notice that here we are given the standard deviations (not the
variances).
• E(Y – Z – X) = E(Y) – E(Z) – E(X) = 0.2 – 2.4 – 0 = -2.2.
• V(Y – Z – X) = V(X) + V(Y) + V(Z) = 12 + 32 + 52 = 35.
• σ(Y – Z – X) = 35 = 5.916.
22
Sum of independent normal random variables
Suppose
• 𝑋 is normal with mean 𝜇1 and variance 𝜎1 2 ,
• 𝑌 is normal with mean 𝜇2 and variance 𝜎2 2 , and
• 𝑋 and 𝑌 are independent of each other.
Then 𝑋 + 𝑌 is normally distributed with mean 𝜇1 + 𝜇2
and variance 𝜎1 2 + 𝜎2 2 .
That means
𝐸 𝑋 + 𝑌 = 𝜇1 + 𝜇2 .
𝑣𝑎𝑟 𝑋 + 𝑌 = 𝜎1 2 + 𝜎2 2 .
𝜎 𝑋+𝑌 =
𝜎1 2 + 𝜎2 2 .
23
Example
Suppose the monthly revenue in investment A is
normally distributed with mean $25 and std.dev. $8,
and that in investment B is normally distributed with
mean $31 and std.dev. $10. If you have both
investments, what is the probability that your total
monthly revenue will be more than $75?
The total monthly revenue will be normally distributed
with mean $(25+31)=$56, and std. dev. 82 + 102 =
$12.806.
So probability that your total monthly revenue will be
more than $75 is = normalcdf(75,1000,56,12.806) =
0.069.
24
Example
Suppose the monthly revenue in investment A is
normally distributed with mean $25 and std.dev. $8,
and that in investment B is normally distributed with
mean $31 and std.dev. $10. Above what value 80% of
total monthly revenue will lie?
The total monthly revenue will be normally distributed
with mean $(25+31)=$56, and std. dev. 82 + 102 =
$12.806.
If x is the value above which 80% of total monthly
revenue will lie, then 20% of total monthly revenue will
lie below x.
Thus x = invNorm(0.2,56,12.806) = $45.83.
25
Uniform distribution
26
Uniform distribution
A continuous random variable X is uniformly distributed
in the interval [𝑎, 𝑏] if its probability density function is
𝑓 𝑥 =
1
,
𝑏−𝑎
for 𝑎 ≤ 𝑥 ≤ 𝑏.
In this case, if 𝑎 ≤ 𝑙 < 𝑢 ≤ 𝑏
o𝑃 𝑙<𝑋<𝑢 =
o𝐸 𝑋 =
o𝜎 𝑋 =
𝑢−𝑙
,
𝑏−𝑎
𝑎+𝑏
,
2
𝑏−𝑎
.
12
27
Example
If price of gas (X) in East Lansing has uniform
distribution in the interval $[3.45, 3.95] per gallon.
• Probability that gas price will be between $3.50 and $3.60 =
3.60−3.50
𝑃 3.50 ≤ 𝑋 ≤ 3.60 =
= 0.2.
3.95−3.45
• Probability that gas price will be less than $3.70 = 𝑃(𝑋 <
28
Example
If price of gas (X) in East Lansing has uniform
distribution in the interval $[3.45, 3.95] per gallon.
• The expected gas price in East Lansing is =
3.45+3.95
= $3.70.
2
• The standard deviation of gas price in East
3.95−3.45
Lansing is =
= $0.144.
12
29
Exponential distribution
30
Exponential distribution
A continuous random variable X is exponentially
distributed with mean 𝜃 if its probability density
function is
𝑓 𝑥 =
1 −𝑥/𝜃
𝑒
,
𝜃
for 𝑥 > 0.
In this case,
o 𝑃 𝑋 > 𝑥 = 𝑒 −𝑥/𝜃 ,
o 𝐸 𝑋 = 𝜃,
o 𝜎 𝑋 = 𝜃.
31
Example
If the waiting time (X) for Bus #1 is exponentially
distributed with mean 10 min.
Chance that we will get a Bus #1 within next 5 min =
5
−10
𝑃 𝑋 ≤5 =1−𝑃 𝑋 >5 =1−𝑒
= 0.393.
Chance that we have to wait more than 20 min for
20
−10
bus #1 = 𝑃 𝑋 > 20 = 𝑒
= 0.135.
The expected waiting time is 10 min.
The standard deviation of waiting time is 10 min.
The variance of waiting time is 102 = 100 min2.
32
Sampling distributions
33
Remember
• Population is the complete set of all items that we
are interested in studying.
• Parameters are the values we calculate from the
population data.
Population mean (for quantitative variables),
population proportion (categorical variables) etc.
are the examples of parameters.
• A sample is a subset of the population.
• Statistics are values we compute from sample data.
Sample mean, sample proportion etc. are the
examples of statistics.
• Our goal is to make inference on parameters based
on relevant statistics.
34
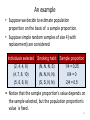
An example
• Consider a population with 10 individuals with the
following smoking habit:
Individual #:
1 2 3 4 5 6 7 8 9 10
Smoking habit:
N N N N S S N N S N
where S = smoker, and N = non-smoker.
So 3 out of 10 people in the population is smoker.
Here the population proportion of smoker is:
3
p
0. 3.
10
35
An example
• Suppose we decide to estimate population
proportion on the basis of a sample proportion.
• Suppose simple random samples of size 4 (with
replacement) are considered.
Individuals selected
Smoking habit
Sample proportion
(2, 4, 4, 9)
(4, 7, 8, 10)
(5, 6, 8, 8)
(N, N, N, S)
(N, N, N, N)
(S, S, N, N)
1/4 = 0.25
0/4 = 0
2/4 = 0.5
• Notice that the sample proportion’s value depends on
the sample selected, but the population proportion’s
value is fixed.
36
Few questions
• Can we justify the use of sample proportion as an
estimator of population proportion?
• What can we expect about the value of sample
proportion when population proportion (p) is 0.3?
Does this behavior depend on the value of p?
• What is the “margin of error”, if we estimate p with
sample proportion?
(To be answered in a later lecture.)
• As sample proportion is a variable, what is its
distribution?
37
Few questions
• Does it matter how the sample is selected?
• Does the sample size matter?
• Is this a problem of population proportion only?
Or do we face it for other parameters also?
This is a problem for all parameters, which are fixed
in value for a particular population.
The value of any statistic changes with the sample
selected.
38
Sampling Distribution
• As any statistic’s value changes with the
selected sample, so statistic is a itself a
random variable.
• The probability distribution of a sample
statistic is called the sampling distribution of
the statistic.
• In this course we shall study sampling
distributions of sample proportion and sample
mean.
39
Sampling method and sample size
• Samples must be independent.
Simple random sampling “with replacement” ensures
independence.
Holds (approximately) also for “without replacement”
sampling as long as the sample size is smaller than 10% of
the population size.
• Sample size must be “large enough”.
What is “large enough” depends on the statistic we are
considering,
i.e. different rules of “large enough” for sample proportion
and sample mean.
It is the “sample size” what is important, NOT what fraction
of population is sampled.
40
Sampling distribution of
sample proportion (𝒑)
41
Sampling distribution of sample proportion
• Consider in a population a categorical variable with
two categories: success and failure.
e.g., “smoking habit” variable the level smoker can be
considered as “success”, and non-smoker as “failure”.
• Let p be the population proportion of success.
• A random sample from the population is drawn.
– Observations in the sample are independent.
– Sample size is n.
– Let x be the number of success in the sample.
• Then sample proportion of success is
𝑥
𝑝= .
𝑛
42
Sampling distribution of sample proportion
• The expected value of 𝑝 is equal to p, i.e. 𝐸 𝑝 = 𝑝.
• The standard deviation of 𝑝 is
𝑝(1 − 𝑝)
𝜎𝑝 =
.
𝑛
• If we repeatedly simulate the selection of samples
from the population with “large enough” sample
size, the distribution of the sample proportions we
found in the samples will be roughly normally
distributed and the distribution will be
𝑝(1 − 𝑝)
𝑁 𝑝,
.
𝑛
43
Sampling distribution of sample proportion
• When is sample “large enough” for the last result to
hold?
• If n is so large that
𝑛𝑝 > 9, and 𝑛(1 − 𝑝) > 9.
• This is covered if the number of successes and
failures are both at least 10.
44
Example One
Of all the cars on the highway, about 80% exceed
the speed limit. If we clock the next 50 cars that
pass, what might we expect to find?
Is the independence condition met?
Most likely NO, because the cars moving at the same
time may influence each others behavior.
Suppose we randomly
select 50 cars that pass.
Is the independence
condition met?
Yes.
45
Example One
Of all the cars on the highway, about 80% exceed
the speed limit. Suppose we randomly select
50 cars that pass.
Is sample size large enough condition met?
a) Yes
b) No
Because,
np = 50×0.8 = 40 > 9,
and
n(1-p) = 50×0.2 = 10 > 9.
46
Example One
Of all the cars on the highway, about 80% exceed
the speed limit. Suppose we randomly select
50 cars that pass.
What is the expected proportion of cars in the
sample to exceed the speed limit?
A.
B.
C.
D.
20%
80%
2.83%
0.057%
47
Example One
Of all the cars on the highway, about 80% exceed
the speed limit. Suppose we randomly select
50 cars that pass.
What is the standard deviation of the sample
proportion of cars exceeding the speed limit?
A.
B.
C.
D.
20
80
2.83
0.057
48
Example One
Of all the cars on the highway, about 80% exceed
the speed limit. Suppose we randomly select
50 cars that pass.
What is the chance that more than 90% of cars in
the sample exceeded the speed limit?
A.
B.
C.
D.
E.
0.80
0.20
0.057
0.039
0.961
normalcdf(0.9,100,0.8,0.057)
= 0.039.
49
Sampling distribution of
sample mean (𝒙)
50
Sampling distribution of sample mean
• Suppose the mean of population distribution is
µ and standard deviation σ.
• A random sample from the population is
drawn.
– Observations in the sample are independent.
– Sample size is n.
– Let the sample mean be 𝑥
• The expected value of 𝑥 is equal to µ.
• The standard deviation of 𝑥 is
𝜎
.
𝑛
51
Central Limit Theorem (CLT)
• If we repeatedly simulate the selection of samples
from the population with “large enough” sample size,
the distribution of the sample mean in random
sampling roughly follows a normal model and the
𝜎
distribution will be 𝑁(𝜇, ).
𝑛
• The larger the sample size, the closer to normal the
distribution will be.
• But how large is “large enough” to apply CLT?
We can use CLT if 𝑛 ≥ 30.
52
Example Two
At birth, babies average 7.8 pounds, with a
standard deviation of 2.1 pounds. A random
sample of 34 babies born to mothers living near a
factory that might be polluting the air and water
shows a mean birth-weight of only 7.2 pounds.
What is the expected value of sample mean?
A. 34 lb
B. 7.2 lb
C. 7.8 lb
D. 2.1 lb
53
Example Two
At birth, babies average 7.8 pounds, with a
standard deviation of 2.1 pounds. A random
sample of 34 babies born to mothers living near a
factory that might be polluting the air and water
shows a mean birth-weight of only 7.2 pounds.
What is the standard deviation of sample mean?
A. 1.23 lb
B. 7.2 lb
C. 0.36 lb
D. 2.1 lb
54
Example Two
At birth, babies average 7.8 pounds, with a
standard deviation of 2.1 pounds. A random
sample of 34 babies born to mothers living near a
factory that might be polluting the air and water
shows a mean birth-weight of only 7.2 pounds.
What is the chance that the sample mean
is lower than 7.2 lbs?
A. 0.952
B. 0.388
C. 0.612
D. 0.048
normalcdf(-100, 7.2, 7.8, 0.36) = 0.048.
55
Example
If price of gas (X) in East Lansing has uniform distribution in the
interval $[3.45, 3.95] per gallon.
Remember that μ = E X = $3.70, 𝜎 𝑋 = $0.144.
Suppose we collect gas prices from 35 gas stations of East
Lansing.
• The expected sample average of gas prices is 𝐸 𝑋 = 𝜇 =
$3.70.
• The standard deviation of sample average of gas prices is
𝜎
0.144
𝜎 𝑋 =
=
= $0.024.
𝑛
35
• Since 𝑛 > 30, we have 𝑋~𝑁 3.70, 0.024 .
• The chance that the sample average will be less than $3.65 is
𝑃 𝑋 < 3.65 = 𝑛𝑜𝑟𝑚𝑎𝑙𝑐𝑑𝑓 −100, 3.65, 3.70, 0.024
= 0.0186.
56
Example
If the waiting time (X) for Bus #1 is exponentially
distributed with mean 10 min. What is the chance that
a sample average of 40 persons’ waiting time will be
within 2 min of the mean time (10 min).
• The expected sample average of waiting time is
𝐸 𝑋 = 𝜇 = 10 min.
• The standard deviation of sample average of waiting
𝜎
10
time is 𝜎 𝑋 =
=
= 1.58 min.
𝑛
40
• Since 𝑛 > 30, we have 𝑋~𝑁 10, 1.58 .
• 𝑃 10 − 2 ≤ 𝑋 ≤ 10 + 2 = 𝑃 8 ≤ 𝑋 ≤ 12 =
𝑛𝑜𝑟𝑚𝑎𝑙𝑐𝑑𝑓 8,12,10,1.58 = 0.7944.
57