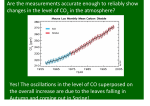
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Erkan Çetiner Outline Introduction Related Works Modeling Methodology Baseline Results DTM Techniques Conclusions INTRODUCTION SMT(Simultaneous Multithreading) Allows instructions from multiple threads to be simultaneously fetched and executed in same pipeline Amortizing the cost by allowing more IPC(instruction per cycle) Even though SMT has shown energy efficiency for most workloads , the significant boost in IPC results in increased power dissipation & possible increased power density So thermal behavior & cooling costs are major concern CMP(Core Multiprocessors) Instantiates multiple processor “cores” on a single die Each core has private branch predictors , first-level caches and a shares a second-level , on-chip cache For multiprogrammed workloads it amortizes cost of die by allowing data sharing within a common L2 cache Like in SMT , CMP promise to boost in throughput The replication of cores means that area and power overhead to support extra threads is much greater with CMP than SMT For a given die size , a single-core SMT chip will therefore support a larger L2 size than a multi- core chip Side effect for CMP Each added cores on a chip increases power dissipation , so thermal behavior and cooling costs are also major concerns for CMP Why Compare Those ? Both paradigms target increased througput for multithreaded and multi-programmed workloads , it is worthy to compare them to see the performance , energy and thermal conditions of them RELATED WORKS Research Areas Area overhead & energy efficiency of SMT Energy efficiency & several power-aware optimizations for a multithreaded Alpha processor Energy efficiency of SMT & CMP for Multimedia Workloads Hybrid Systems include SMT & CMP MODELING METHODOLOGY Microarchitecture & Performance Modeling Turando/Powertimer usedto model an out-of-order , superscalar processor with resource configuration similar to current generation multiprocessors Microarchitecture & Performance Modeling SMT is modeled by duplicating data structures that correspond to duplicated resources and increasing the sizes of those shared critical resources like the register file Round-Robin policy is used at various pipeline stages for deciding which threads should go ahead It is difficult to compare performance of different CMP or SMP configurations need a baseline Benchmarks 15 SPEC2000 used – single thread benchmark Simpoint toolset used – get representative simulation points for 500 million instructions Trace Generation Tool used – generates final static traces by skipping the number of instructions given by Simpoint Finally 500 million instructions are simulated and captured Use pairs of single-thread benchmarks to form dual-thread SMT&CMP benchmark Categorization of Benchmarks High IPC(>0.9) Low IPC(<0.9) High Temperature(peak temperature>82°C) Low Temperature(peak temperature <82°C) Floating Benchmark Integer Benchmark Power Model Base energy models are derived from circuit level power analysis In this research analysis performed at macro level AssumptionUniform Leakage Power Density for all units on chip if they have same temperature(More accurate leakage power models resulted in more accurate conclusions) Temperature Model HotSpot2.0 usedmodels temperature using a circuit of thermal resistances and capacitances that are derived from the layout of microarchitecture units Assumption Provide at least one temperature sensor for each microarchitecture block in floorplan Chip Die Area & L2 Cache Size Selection Appropriate L2 cache size selection is very important Core area stays fixed in experiment The number of cores & L2 cache size determines total chip die area CMP requires additional chip area for second core , L2 cache size must be smaller to achieve equivalent die area BASELINE RESULTS Some statistics Chip area 210 mm² L2 Cache Sizes ST – 2MB SMT – 2MB CMP – 1MB Performance & Energy CMP outperforms SMT for workloads with low L2 cache miss rates (87%-26%) SMT outperforms CMP for workloads with high miss rates(42%-22%) Performance & Energy Power overhead of SMT (38%-46%) Main reasons for power growth Increased resources it requires Increased utilization due to additional simultaneous instruction throughput Power overhead for CMP(93%-71%) Main Reason Addition of entire second processor By looking these metrics , CMP is most-energy efficient for benchmarks with low L2 cache miss rates SMP is most-energy efficient for benchmarks with high L2 cache miss rates Performance & Energy With Smaller L2 Cache size & High Cache Miss Ratio Program is memory bounded hence SMT is better in terms of performance & energy With Larger L2 Cache Size & Low Cache Miss Ratio No memory-bound CMP is better Temperature Relatively similar temperature ratings Temperature So why temperature increase for both of them ? SMT processor the temperature hotspots are largely due to the higher utilization factor of certain structures like the integer register file CMP processor integrated two cores and the total power of the chip nearly doubles and hence the total amount of heat being generated nearly doubles DTM TECHNIQUES DTM Constrained Techniques Reduce packaging costs Sustain thermal requirements of typical workloads Set some DTM techniques when temperature exceeds the design set point DTM Techniques Dynamic Voltage Scaling Fetch-Throttling Rename-Throttling Register-File Occupancy Throttling Dynamic Voltage Scaling Cuts voltage& frequency in response to thermal violations Restores the high voltage & frequency when the temperature drops below the trigger threshold Fetch-throttling Limits how often the fetch stage is allowed to proceed Reduces activity factors through pipeline Rename-throttling •Limits number of instructions renamed each cycle Register-File Occupancy-throttling Register file is hottest spot of all chip Its power is proportional to occupancy To reduce power of register file limit the number of register entries to a fraction of full size All these techniques have a coomon property that by limiting resources available to processors , these policies will cause the processor to slow down , thus consuming less power & finally cooling down to below the thermal trigger level Performance of DTM For workloads with low or moderate miss ratios , CMP always gives the best performance regardless of the DTM technique For workloads that are memory bound , SMT always give better performance Performance of DTM For CMP Register-throttling & fetch-throttling work equally well For SMT Register-throttling is the best techniquerename-throttlingglobal-fetch throttling Energy of DTM Energy consumption is critical design criteria for : Battery life Energy utility costs (e.g. High-performance mobile laptops , servers designed for throughput oriented data centers like Google cluster architecture) Dominant trend is that global DTM techniques tenf to have superior energy-efficiency compared against to local techniques for most configuration Because global nature of DTM mechanism , larger portion of chip will be cooled , resulting in larger savings SMT architecture is superior to ST architecture for all DTM techniques except for Rename-throttling For CMP In Low L2 miss rates , CMP is always superior to the SMT for all DTM configurations CONCLUSIONS Conclusions Both exhibit similar operating temperatures within current generation process technologies but heating behaviors are different : SMT Heating is caused by localized heating within certain key microarchitecturral structures such as register file , due to increased utilization CMP Heating is primarily caused by global impact of increased energy output CMP machines offer significantly more throughput than SMT machines for CPU-bound applications and this leads to significant energy-efficiency savings despite a substantial increase in power dissipation . Conclusions In equal-area comparison loss of L2 cache size hurts the CMP’s performance for L2bound applications CMP&SMT cores tend to perform better with different DTM techniques In performance oriented systems Localized DTM techniques work better for SMT cores and global DTM techniques work better for CMP cores In energy-oriented systems global DVS thermal management technique offer significant energy savings REFERENCES Performance, energy, and thermal considerations for SMT and CMP architectures Yingmin Li Skadron, K. Brooks, D. Zhigang Hu Dept. of Comput. Sci., Virginia Univ., Charlottesville,VA, USA Efficiency of Thread-Level Speculation in SMT and CMP Architectures - Performance, Power and Thermal Perspective Venkatesan Packirisamy, Yangchun Luo, Wei-lung Hung, Antonia Zhai, and Pen-chung Yew THANK YOU