Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
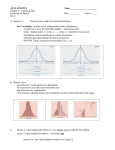
Business Statistics for Managerial Decision Making Examining Distributions Introduction Descriptive Statistics Methods that organize and summarize data aid in effective presentation and increased understanding. Bar charts, tabular displays, various plots of economic data, averages and percentages. Often the individuals or objects studied by an investigator come from a much larger collection, and the researcher’s interest goes beyond just data summarization. Introduction Population The entire collection of individuals or objects about which information is desired. Sample A subset of the population selected in some prescribed manner for study. Introduction Inferential Statistics Involves generalizing from a sample to the population from which it was selected. This type of generalization involves some risk, since a conclusion about the population will be reached based on the basis of available, but incomplete, information. An important aspect in the development of inference techniques involves quantifying the associated risks. Individuals and variables Individuals are the objects described by a set of data. They may be people, but they may also be business firms, common stocks, or other objects. A Variable is any characteristic of an individual. A variable can take different values for different individuals. Categorical & Quantitative Variables A Categorical Variable places an individual into one of several groups or categories. A Quantitative Variable takes numerical values for which arithmetic operations such as adding and averaging make sense. The distribution of a variable tell us what values it takes and how often it takes these values. Example Example Discrete and Continuous Variable With numerical data (quantitative variables), it is useful to make a further distinction. Numerical data is discrete if the possible values are isolated points on the number line. Numerical data is continuous if the set of possible values form an entire interval on the number line. Stem plot To make a stem plot: 1. 2. 3. Separate each observation into a stem consisting of all but the final (rightmost) digit and a leaf, the final digit. Stems may have as many digits as needed, but each leaf contains only a single digit. Write the stems in a vertical column with the smallest at the top, and draw a vertical line at the right of this column. Write each leaf in the row to the right of its stem, in increasing order out from the stem. Stem plot Frequency Distribution A frequency distribution for categorical data is a table that displays the categories, frequencies, and relative frequencies. Example The increasing emphasis on exercise has resulted in an increase of sport related injuries. A listing of the 82 sample observations would look something like this: F, Sp, Sp, Co, F, L, F, Ch, De, L, Sp, Di, St, Cn,… Frequency Distribution The following coding is used: Sp = Sprain, St = Strain, Di = dislocation, Co = Contusion, L = laceration, Cn = Concussion, F = fracture, Ch = chronic, De = dental Frequency Distribution Categories Sprain Contusion Fracture Strain Laceration Chronic Dislication Concussion Dental Total Frequency 22 18 17 9 6 4 3 2 1 Relative Frequency 0.268 0.22 0.207 0.11 0.073 0.049 0.037 0.024 0.012 82 1 Bar Graph Frequency Distribution for Type of Injury 25 20 Count 15 10 5 0 Sprain Contusion Fracture Strain Laceration Chronic Dislication Concussion Dental Pie Chart Frequency Distribution for type of Injury 4% 2% 1% 5% 27% 7% Sprain Contusion Fracture Strain Laceration 11% Chronic Dislication Concussion Dental 22% 21% Frequency Distribution for Discrete Numerical Data Discrete numerical data almost always results from counting. In such cases, each observation is a whole number. For example, if the possible values are 0, 1, 2, 3, …, then these are listed in column, and a running tally is kept as a single pass is made through the data Frequency Distribution for Discrete Numerical Data Example A sample of 708 bus drivers employed by public corporations was selected, and the number of traffic accidents in which each was involved during a 4-year period was determined. A listing of the 708 sample observations would look something like this: 3, 0, 6, 0, 0, 2, 1, 4, 1, … Frequency Distribution for Discrete Numerical Data Number of Accidents 0 1 2 3 4 5 6 7 8 9 10 11 Frequency 117 157 158 115 78 44 21 7 6 1 3 1 Relative Frequency 0.165 0.22 0.223 0.162 0.11 0.062 0.03 0.01 0.008 0.001 0.004 0.001 Total 708 0.998 Bar Graph Frequency Distribution for Number of Accidents by Bus Drivers 180 160 140 Count 120 100 80 60 40 20 0 1 2 3 4 5 6 7 Number of Accidents 8 9 10 11 12 Frequency Distributions for Continuous Data The difficulty with continuous data, such as observations on the unemployment rate by state, is that there is no natural categories. Therefore we define our own categories. by marking off some intervals on horizontal unemployment rate axis as picture below. 1.00 9.00 Frequency Distributions for Continuous Data If the smallest rate were 1.5%, and the largest was 8.9%, we might use the intervals of width 1% with the first one starting at 1 and the last one ending at 9. Each data value should fall in exactly one of these intervals. Frequency Distributions for Continuous Data Frequency Distributions for Continuous Data Unemployment rate Intervals [1, 2) [2, 3) [3, 4) [4, 5) [5, 6) [6, 7) [7, 8) [8, 9) Total Frequency 2 13 21 10 3 1 0 1 Relative Frequency 0.039 0.255 0.412 0.196 0.059 0.020 0.000 0.020 51 1.000 Histograms Mark the boundaries of the class intervals on a horizontal axis. Draw a vertical scale marked with either relative frequencies or frequencies. The rectangle corresponding to a particular interval is drawn directly above the interval. The height of each rectangle is then the class frequency or relative frequency. Histograms Histograms Examining a Distribution In any graph of data, look for overall pattern and for striking deviation from that pattern. You can describe the overall pattern of a histogram by its shape, center, and spread. An important kind of deviation is an outlier, an individual value that falls outside the overall pattern. Symmetric & Skewed Distribution A distribution is symmetric if the right and left sides of the histogram are approximately mirror images of each other. A distribution is skewed to the right if the right side of the histogram ( containing the half of the observations with larger values) extends much farther out than the left side. It is skewed to the left if the left side of the histogram extends much farther out than the right side. Symmetric Distribution Skewed to the Right Symmetric Distribution Numerical Summary Measures Describing the center of a data set. Mean Median Describing the variability in a data set. Variance, standard deviation Quartiles The Mean X To find the mean of a set of observations, add their values and divide by the number of observations. If the n observations are x1 , x2 ,, xn , their mean is X x1 x2 xn n In a more compact notation, x X i n The Median The Median M is the midpoint of a distribution, the number such that half of the observations are smaller and the other half are larger. To find the median of a distribution: 1. 2. 3. Arrange all observations in order of size, from smallest to largest. If the number of observations n is odd, the median M is the center observation in the ordered list. If the number of observations n is even, the median M is the mean of the two center observations in the ordered list. The Quartiles Q1 and Q3 To calculate the quartiles: 1. 2. 3. Arrange the observations in increasing order and locate the median M in the ordered list of observations. The first quartile Q1 is the median of the observations whose position in the ordered list is to the left of the location of the overall median. The third quartile Q3 is the median of the observations whose position in the ordered list is to the right of the location of the overall median. The Five Number Summary and Box-Plot The five number summary of a distribution consists of the smallest observation, the first quartile, the median, the third quartile, and the largest observation, written in order from smallest to largest. In symbols, the five number summary is Minimum Q1 M Q3 Maximum The Five Number Summary and Box-Plot A box-plot is a graph of the five number Summary. A central box spans the quartiles. A line in the box marks the median. Lines extend from the box out to the smallest and largest observations. Box-plots are most useful for side-by-side comparison of several distributions. Example The Standard Deviation s The Variance s2 of a set of observations is the average of the squares of the deviations of the observations from their mean. In symbols, the variance of n observations x , x ,, x is 1 2 ( x1 x ) 2 ( x2 x ) 2 ( xn x ) 2 s n 1 2 or, more compactly, 2 ( x ) i 2 2 x i ( xi x ) 2 n s n 1 n 1 n The Standard Deviation s The standard deviation s is the square root of the variance s2: ( x ) x ( x x ) n s 2 2 i n 1 i 2 i n 1 Choosing a Summary The five number summary is usually better than the mean and standard deviation for describing a skewed distribution or a distribution with extreme outliers. Use x , and s only for reasonably symmetric distributions that are free of outliers. Strategies for Exploring Data Plot the data Make a graph, usually a histogram or a stemplot. Look at the distribution of the variable for: overall pattern (shape, center, spread). striking deviations such as outliers. Calculate a numerical summary to briefly describe center and spread. Describe the overall pattern with a smooth curve. Density Curves Sometimes the overall pattern (the distribution of the variable) of a large number of observations is so regular that we can describe it by a smooth curve, called Density curve. The curve is a mathematical model for the distribution. Density Curve Histogram of the city gas mileage (miles per gallon) of 856, 2001 model year motor vehicle. The smooth curve, density curve, shows the overall shape of the distribution. Density Curve The proportion of cars with gas mileage less than 20 from the histogram is 384 .449 44.9% 856 Density Curve The proportion of cars with gas mileage less than 20 from the density curve is .410 The area under the density curve gives a good approximation of areas given by histogram. Density Curve A density curve is a curve that Is always on or above the horizontal axis. Has area exactly 1 underneath it. A density curve describes the overall pattern of a distribution. The area under the curve and above any range of values is the proportion of all observations that fall in that range. Median and mean of a Density Curve The median of a density curve is the point that divides the area under the curve in Half. Median and Mean of a Density Curve The mean of a density curve is the balance point, at which the curve would balance if made of solid material. Median and Mean of a Density Curve The median and mean are the same for a symmetric density curve. They both are at the center of the curve. Median and Mean of a Density Curve The mean of a skewed curve is pulled away from the median in the direction of the long tail. Normal Density Curve These density curves, called normal curves, are Symmetric Single peaked Bell shaped Normal curves describe normal distributions. Normal Density Curve The exact density curve for a particular normal distribution is described by giving its mean and its standard deviation . The mean is located at the center of the symmetric curve and it is the same as the median. The standard deviation controls the spread of a normal curve. Normal Density Curve The 68-95-99.7 Rule Although there are many normal curve, They all have common properties. In particular, all Normal distributions obey the following rule. In a normal distribution with mean and standard deviation : 68% of the observations fall within of the mean . 95% of the observations fall within 2 of . 99.7% of the observations fall within 3 of . The 68-95-99.7 Rule The 68-95-99.7 Rule Standard Normal Distribution The standard Normal distribution is the Normal distribution N(0, 1) with mean = 0 and standard deviation =1. The standard Normal Table What is the area under the standard normal curve between z = 0 and z = 2.3? Compact notation: p(0 z 2.3) P = .9893 - .5 =.4893 Finding the area under a normal curve 1. 2. 3. 4. State the problem in terms of the observed variable x. Standardize x to restate the problem in terms of a standard normal variable z Draw a picture to show the area under the standard Normal curve. Find the required area under the standard Normal curve Using table A and the fact that the total area under the curve is 1. Example The annual rate of return on stock indexes (which combine many individual stocks) is approximately Normal. Since 1954, the Standard & Poor’s 500 stock index has had a mean yearly return of about 12%, with standard deviation of 16.5%. Take this Normal distribution to be the distribution of yearly returns over a long period. The market is down for the year if the return on the index is less than zero. In what proportion of years is the market down? Example State the problem Call the annual rate of return for Standard & Poor’s 500-stocks Index x. The variable x has the N(12, 16.5) distribution. We want the proportion of years with X < 0. Standardize Subtract the mean, then divide by the standard deviation, to turn x into a standard Normal z: x0 x 12 0 12 16.5 16.5 z .73 Example Draw a picture to show the standard normal curve with the area of interest shaded. Use the table The proportion of observations less than - 0.73 is .2327. The market is down on an annual basis about 23.27% of the time. Example What percent of years have annual return between 12% and 50%? State the problem 12 x 50 Standardize 12 12 x 12 50 12 16.5 16.5 16.5 0 z 2.30 Example Draw a picture. Use table. The area between 0 and 2.30 is the area below 2.30 minus the area below 0. 0.9893- .50 = .4893 Finding a Value when Given a Proportion Sometimes we may want to find the observed value with a given proportion of observations above or below it. To do this, use table A backward. Find the given proportion in the body of the table, read the corresponding z from the left column and top row, then unstandardize to get the observed value. Example Miles per gallon ratings of compact cars (2001 model year) follow approximately the N(25.7, 5.88) distribution. How many miles per gallon must a vehicle get to place in the top 10% of all 2001 model year compact cars? Example We want to find the miles per gallon rating x with area 0.1 to its right under the Normal Curve with mean 25.7 and standard deviation 5.88. That is the same as finding the miles per gallon rating x with area 0.9 to its left. Example Look in the body of Table A for the entry closest to 0.9. It is 0.8997. This is the entry corresponding to z = 1.28. Example Unstandardize to transform the solution from the z back to the original x scale. x z x 25.7 1.28 5.88 x 25.5 (1.28)( 5.88) 33.2 Standard Normal Distribution If a variable x has any normal distribution N(, ) with mean and standard deviation , then the standardized variable z x has the standard Normal distribution. This standardized value is often called z-score. The standard Normal Table Table A is a table of area under the standard Normal curve. The table entry for each value z is the area under the curve to the left of z. Or you can use the applet at the following site. http:/www.stat.sc.edu~west/applet s/normaldemo.html The standard Normal Table What is the area under the standard normal curve to the right of z = - 2.15? Compact notation: p ( z 2.15) P = 1 - .0158 =.9842