Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Multiplicative Data Perturbations
Outline
Introduction
Multiplicative data perturbations
Rotation perturbation
Geometric Data Perturbation
Random projection
Understanding
Distance preservation
Perturbation-invariant models
Attacks
Privacy Evaluation Model
Background knowledge and attack analysis
Attack-resilient optimization
Comparison
Summary on additive perturbations
problems
Weak to various attacks
Need to publish noise distribution
The column distribution is known
Need to develop/revise data mining algorithms in order to
utilize perturbed data
So far, we have only seen that decision tree and naïve bayes
classifier can utilize additive perturbation.
Benefits
Can be applied to both the Web model and the
collaborative data pooling model
Low cost
More thoughts about
perturbation
1. Preserve Privacy
Hide the original data
not easy to estimate
the original values
from the perturbed
data
Protect from data
reconstruction
techniques
The attacker has prior
knowledge on the
published data
2. Preserve Data Utility for
Tasks
Single-dimensional info
column data
distribution, etc.
Multi-dimensional
info
Cov matrix, distance,
etc
For most PP approaches…
Privacy
guarantee
?
Data Utility/
Model accuracy
Privacy guarantee
Data utility/
Model accuracy
•Difficult to balance the two factors
•Subject to attacks
•May need new DM algorithms: randomization, cryptographic approaches
Multiplicative perturbations
Geometric data perturbation (GDP)
Rotation data perturbation +
Translation data perturbation +
Noise addition
Random projection perturbation(RPP)
Sketch approach
Definition of Geometric Data
Perturbation
G(X) = R*X + T + D
R: random rotation
T: random translation
D: random noise, e.g., Gaussian noise
Characteristics:
R&T preserving distance, D slightly perturbing distance
Example:
ID
001
002
age
1158
943
rent
3143
2424
tax
-2919
-2297
=
.83
-.40
.40
.2
.86
.46
.53
.30
-.79
*
ID
001
002
age
30
25
rent
1350
1000
tax
4230
3320
+
12
12
18
18
30
30
+
-.4
.29
-1.7
-1.1
.13
1.2
* Each component has its use to enhance the resilience to attacks!
Benefits of Geometric Data
Perturbation
Privacy
guarantee
decoupled
Data Utility/
Model accuracy
Make optimization and balancing easier!
-Almost fully preserving model accuracy - we optimize privacy only
Applicable to many DM algorithms
-Distance-based Clustering
-Classification: linear, KNN, Kernel, SVM,…
Resilient to Attacks
-the result of attack research
Limitations
Multiplicative perturbations are
mostly used in outsourcing
Cloud computing
Can be applied to multiparty
collaborative computing in same cases
Web model does not fit – perturbation
parameters cannot be published
Definition of Random Projection
Perturbation
F(X) = P*X
X is m*n matrix: m columns and n rows
P is a k*m random matrix, k <= m
Johnson-Lindenstrauss Lemma
There is a random projection F() with
e is a small number <1, so that
(1-e)||x-y||<=||F(x)-F(y)||<=(1+e)||x-y||
i.e. distance is approximately preserved.
Comparison between GDP and
RPP
Privacy preservation
Subject to similar kinds of attacks
RPP is more resilience to distance-based
attacks
Utility preservation(model accuracy)
GDP preserves distances well
RPP approximately preserves distances
Model accuracy is not guaranteed
Illustration of multiplicative
data perturbation
Preserving distances
while perturbing each
individual dimensions
A Model “invariant” to GDP …
If distance plays an important role
Class/cluster members and decision boundaries are
correlated in terms of distance, not the concrete locations
2D Example:
Class 1
Class
2
Classification boundary
Rotation and
translation
Classification
boundary
Distance perturbation
(Noise addition)
Slightly
changed
Classification
boundary
Applicable DM algorithms
Modeling methods that depend on Euclidean
geometric properties
Models “invariant” to GDP
all Euclidean distance based clustering algorithms
Classification algorithms
K Nearest Neighbors
Kernel methods
Linear classifier
Support vector machines
Most regression models
And potentially more …
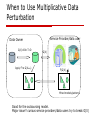
When to Use Multiplicative Data
Perturbation
Service Provider/data user
Data Owner
G(X)=RX+T+D
Apply F to G(Xnew)
G(X)
F(G(X), )
Mined models/patterns
Good for the outsourcing model.
Major issue!! curious service providers/data users try to break G(X)
Major issue: attacks!
Many existing Privacy Preserving methods are
found not so effective
when attacks are considered
Ex: various data reconstruction algorithms to the
random noise addition approach [Huang05][Guo06]
Prior knowledge
Service provider Y has “PRIOR KNOWLEDGE”
about X’s domain and nothing stops Y from using it
to infer information in the sanitized data
Knowledge used to attack GDP
Three levels of knowledge
Know nothing naïve estimation
Know column distributions Independent
Component Analysis
Know specific input-output records (original
points and their images in perturbed data)
distance inference
Methodology of attack analysis
An attack is an estimate of the original
data
Original O(x1, x2,…, xn) vs. estimate P(x’1,
x’2,…, x’n)
How similar are these two series?
One of the effective methods is to evaluate the MSE of the
estimation – VAR(P-O) or STD(P-O)
Two multi-column privacy metrics
qi : privacy guarantee for column i
qi = std(Pi–Oi), Oi normalized column values,
Pi estimated column values
Min privacy guarantee: the weakest link of all columns
min { qi, i=1..d}
Avg privacy guarantee: overall privacy guarantee
1/d qi
Alternative metric
Based on Agarawal’s information
theoretic measure: loss of privacy
PI=1- 2-I(X; X^), X^ is the estimation of X
I(X; X^) = H(X) – H(X|X^) = H(X) –
H(estimation error)
Exact estimation H(X|X^) =0, PI = 1-2-H(X)
Random estimation I(X; X^) = 0, PI=0
Already normalized for different columns
Attack 1: naïve estimation
Estimate original points purely based
on the perturbed data
If using “random rotation” only
Intensity of perturbation matters
Points around origin
Y
Class 1
Class
2
Classification boundary
X
Counter naïve estimation
Maximize intensity
Based on formal analysis of “rotation intensity”
Method to maximize intensity
Fast_Opt algorithm in GDP
“Random translation” T
Hide origin
Increase difficulty of attacking!
Need to estimate R first, in order to find out T
Attack 2: ICA based attacks
Independent Component Analysis (ICA)
Try to separate R and X from Y= R*X
Characteristics of ICA
1. Ordering of dimensions is not preserved.
2. Intensity (value range) is not preserved
Conditions of effective ICA-attack
1. Knowing column distribution
2. Knowing value range.
Counter ICA attack
Weakness of ICA attack
Need certain amount of knowledge
Cannot effectively handle dependent
columns
In reality…
Most datasets have correlated columns
We can find optimal rotation perturbation
maximizing the difficulty of ICA attacks
Attack 3: distance-inference attack
If with only rotation/translation perturbation, when the attacker knows
a set of original points and their mapping…
image
Known
point
Original
Perturbed
How is the Attack done …
Knowing points and their images …
find exact images of the known points
Enumerate pairs by matched distances
… Less effective for large data …
we assume pairs are successfully identified
Estimation
1. Cancel random translation T from pairs (x, x’)
2. calculate R with pairs: Y=RX R = Y*X-1
3. calculate T with R and known pairs
Counter distance-inference:
Noise addition
Noise brings enough variance in estimation of
R and T
Now the attacker has to use regression to estimate R
Then, use approximate R to estimate T increase uncertainty
Regression
1. Cancel random translation T from pairs (x, x’)
2. estimate R with pairs:
Y=RX R = (Y*XT )(X*XT)-1
3. Use the estimated R and known pairs to
estimate T
Discussion
Can the noise be easily filtered?
Need to know noise distribution, distribution of RX + T,
Both distributions are not published, however.
Attack analysis will be different from that for noise
addition data perturbation
Will PCA based noise filtering [Huang05] be effective?
What are the best estimation that the attacker
can get?
If we treat the attack problem as a learning
problem -
Minimum variance of error for the learner
Higher bound of “loss of privacy”
Attackers with more knowledge?
What if attackers know a large amount
of original records?
Able to accurately estimate covariance matrix,
column distribution, and column range, etc., of
the original data
Methods PCA, AK_ICA, …,etc can be used
What do we do?
If you have released so much original information…
Stop releasing data anymore
A randomized perturbation
optimization algorithm
Start with a random rotation
Goal: passing tests on simulated attacks
Not simply random – a hillclimbing
method
1. Iteratively determine R
- Test on naïve estimation (Fast_opt)
- Test on ICA (2nd level)
find a better rotation R
2. Append a random translation component
3. Append an appropriate noise component
Comparison on methods
Privacy preservation
In general, RPP should be better than GDP
Evaluate the effect of attacks for GDP
ICA and distance perturbation need experimental
evaluation
Utility preservation
GDP:
R and T exactly preserve distances,
The effect of D needs experimental evaluation
RPP
# of perturbed dimensions vs. utility
Datasets
12 datasets from UCI Data Repository
Privacy guarantee:GDP
In terms of naïve estimation and ICA-based attacks
Use only the random rotation and translation (R*X+T)
components
Optimized for
Naïve estimation only
Optimized perturbation for both attacks
Worst perturbation (no optimization)
Privacy guarantee:GDP
In terms of distance inference attacks
Use all three components (R*X +T+D)
Noise D : Gaussian N(0, 2)
Assume pairs of (original, image) are identified by attackers
no noise addition, privacy guarantee =0
Considerably high PG
around small perturbation
=0.1
Data utility : GDP with noise
addition
Noise addition vs. model accuracy noise: N(0, 0.12)
Data Utility: RPP
Reduced # of dims vs. model accuracy
KNN classifiers
SVMs
Perceptrons