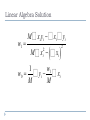Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CS 541: Artificial Intelligence
Lecture IX: Supervised Machine Learning
Slides Credit: Peter Norvig and Sebastian Thrun
Schedule
Week
Date
1 08/29/2012
2 09/05/2012
3 09/12/2012
Topic
Introduction & Intelligent Agent
Search strategy and heuristic search
Constraint Satisfaction & Adversarial Search
4
09/19/2012
Logic: Logic Agent & First Order Logic
5
6
7
09/26/2012
10/03/2012
10/10/2012
Logic: Inference on First Order Logic
No class
Uncertainty and Bayesian Network
8
9
10
10/17/2012
10/24/2012
10/31/2012
Midterm Presentation
Inference in Baysian Network
11
12
13
14
15
16
11/07/2012
11/14/2012
11/21/2012
11/28/2012
12/05/2012
12/12/2012
Machine Learning
Probabilistic Reasoning over Time
No class
Markov Decision Process
Reinforcement learning
Final Project Presentation
Reading
Ch 1 & 2
Ch 3 & 4s
Ch 4s & 5 &
6
Ch 7 & 8s
Homework**
N/A
HW1 (Search)
Teaming Due
HW1 due, Midterm
Project (Game)
Ch 8s & 9
Ch 13 &
Ch14s
Ch 14s
HW2 (Logic)
Midterm Project Due
HW2 Due,
HW3 (PR & ML)
Ch 18 & 20
Ch 15
Ch 16
Ch 21
HW3 due (11/19/2012)
HW4 due
Final Project Due
Re-cap of Lecture VIII
Temporal models use state and sensor variables replicated over time
Markov assumptions and stationarity assumption, so we need
Tasks are filtering, prediction, smoothing, most likely sequence;
All done recursively with constant cost per time step
Hidden Markov models have a single discrete state variable;
Transition model P(Xt|Xt-1)
Sensor model P(Et|Xt)
Widely used for speech recognition
Kalman filters allow n state variables, linear Gaussian, O(n3) update
Dynamic Bayesian nets subsume HMMs, Kalman filters; exact update
intractable
Particle filtering is a good approximate filtering algorithm for DBNs
Outline
Machine Learning
Classification (Naïve Bayes)
Classification (Decision Tree)
Regression (Linear, Smoothing)
Linear Separation (Perceptron, SVMs)
Non-parametric classification (KNN)
Machine Learning
Machine Learning
Up until now: how to reason in a give model
Machine learning: how to acquire a model on the basis of
data / experience
Learning parameters (e.g. probabilities)
Learning structure (e.g. BN graphs)
Learning hidden concepts (e.g. clustering)
Machine Learning Lingo
What?
Parameters
Structure
Hidden concepts
What from?
Supervised
Unsupervised
Reinforcement
Self-supervised
What for?
Prediction
Diagnosis
Compression
Discovery
How?
Passive
Active
Online
Offline
Output?
Classification
Regression
Clustering
Ranking
Details??
Generative
Discriminative
Smoothing
Supervised Machine Learning
f(x)
f(x)
f(x)
x
(a)
f(x)
x
(b)
x
(c)
Given a training set:
(x1, y1), (x2, y2), (x3, y3), … (xn, yn)
Where each yi was generated by an unknown y = f (x),
Discover a function h that approximates the true function f.
x
(d)
Classification (Naïve Bayes)
Classification Example: Spam Filter
Input: x = email
Output: y = “spam” or “ham”
Setup:
Get a large collection of example
emails, each labeled “spam” or
“ham”
Note: someone has to hand label
all this data!
Want to learn to predict labels of
new, future emails
Features: The attributes used to
make the ham / spam decision
Words: FREE!
Text Patterns: $dd, CAPS
Non-text: SenderInContacts
…
Dear Sir.
First, I must solicit your confidence in this
transaction, this is by virture of its nature as
being utterly confidencial and top secret. …
TO BE REMOVED FROM FUTURE
MAILINGS, SIMPLY REPLY TO THIS
MESSAGE AND PUT "REMOVE" IN THE
SUBJECT.
99 MILLION EMAIL ADDRESSES
FOR ONLY $99
Ok, Iknow this is blatantly OT but I'm
beginning to go insane. Had an old Dell
Dimension XPS sitting in the corner and
decided to put it to use, I know it was
working pre being stuck in the corner, but
when I plugged it in, hit the power nothing
happened.
A Spam Filter
Naïve Bayes spam filter
Data:
Collection of emails, labeled spam
or ham
Note: someone has to hand label
all this data!
Split into training, held-out, test
sets
Classifiers
Learn on the training set
(Tune it on a held-out set)
Test it on new emails
Dear Sir.
First, I must solicit your confidence in this
transaction, this is by virture of its nature as
being utterly confidencial and top secret. …
TO BE REMOVED FROM FUTURE
MAILINGS, SIMPLY REPLY TO THIS
MESSAGE AND PUT "REMOVE" IN THE
SUBJECT.
99 MILLION EMAIL ADDRESSES
FOR ONLY $99
Ok, Iknow this is blatantly OT but I'm
beginning to go insane. Had an old Dell
Dimension XPS sitting in the corner and
decided to put it to use, I know it was
working pre being stuck in the corner, but
when I plugged it in, hit the power nothing
happened.
Naïve Bayes for Text
Bag-of-Words Naïve Bayes:
Predict unknown class label (spam vs. ham)
Assume evidence features (e.g. the words) are independent
Generative model
Tied distributions and bag-of-words
Word at position i,
not ith word in the
dictionary!
Usually, each variable gets its own conditional probability distribution P(F|Y)
In a bag-of-words model
Each position is identically distributed
All positions share the same conditional probs P(W|C)
Why make this assumption?
General Naïve Bayes
General probabilistic model:
|Y| x |F|n parameterss
General naive Bayes model:
|Y| parameters
n x |F| x |Y|
parameters
Y
F1
F2
We only specify how each feature depends on the class
Total number of parameters is linear in n
Fn
Example: Spam Filtering
Model:
What are the parameters?
ham : 0.66
spam: 0.33
the :
to :
and :
of :
you :
a
:
with:
from:
...
0.0156
0.0153
0.0115
0.0095
0.0093
0.0086
0.0080
0.0075
Where do these tables come from?
the :
to :
of :
2002:
with:
from:
and :
a
:
...
0.0210
0.0133
0.0119
0.0110
0.0108
0.0107
0.0105
0.0100
Counts from examples!
Spam Example
Word
P(w|spam)
P(w|ham)
Tot Spam
Tot Ham
(prior)
0.33333
0.66666
-1.1
-0.4
Gary
0.00002
0.00021
-11.8
-8.9
would
0.00069
0.00084
-19.1
-16.0
you
0.00881
0.00304
-23.8
-21.8
like
0.00086
0.00083
-30.9
-28.9
to
0.01517
0.01339
-35.1
-33.2
lose
0.00008
0.00002
-44.5
-44.0
weight
0.00016
0.00002
-53.3
-55.0
while
0.00027
0.00027
-61.5
-63.2
you
0.00881
0.00304
-66.2
-69.0
sleep
0.00006
0.00001
-76.0
-80.5
P(spam | words) = e-76 / (e-76 + e-80.5) = 98.9%
Example: Overfitting
Posteriors determined by relative probabilities (odds ratios):
south-west
nation
morally
nicely
extent
seriously
...
:
:
:
:
:
:
inf
inf
inf
inf
inf
inf
screens
minute
guaranteed
$205.00
delivery
signature
...
What went wrong here?
:
:
:
:
:
:
inf
inf
inf
inf
inf
inf
Generalization and Overfitting
Raw counts will overfit the training data!
At the extreme, imagine using the entire email as the only feature
Unlikely that every occurrence of “minute” is 100% spam
Unlikely that every occurrence of “seriously” is 100% ham
What about all the words that don’t occur in the training set at all? 0/0?
In general, we can’t go around giving unseen events zero probability
Would get the training data perfect (if deterministic labeling)
Wouldn’t generalize at all
Just making the bag-of-words assumption gives us some generalization, but isn’t enough
To generalize better: we need to smooth or regularize the estimates
Estimation: Smoothing
Maximum likelihood estimates:
r
g
Problems with maximum likelihood estimates:
g
If I flip a coin once, and it’s heads, what’s the estimate for P(heads)?
What if I flip 10 times with 8 heads?
What if I flip 10M times with 8M heads?
Basic idea:
We have some prior expectation about parameters
(here, the probability of heads)
Given little evidence, we should skew towards our prior
Given a lot of evidence, we should listen to the data
Estimation: Laplace Smoothing
Laplace’s estimate (extended):
Pretend you saw every outcome k
extra times
What’s Laplace with k = 0?
k is the strength of the prior
Laplace for conditionals:
Smooth each condition independently:
H
H
T
Estimation: Linear Interpolation
In practice, Laplace often performs poorly for P(X|Y):
When |X| is very large
When |Y| is very large
Another option: linear interpolation
Also get P(X) from the data
Make sure the estimate of P(X|Y) isn’t too different from P(X)
What if is 0? 1?
Real NB: Smoothing
For real classification problems, smoothing is critical
New odds ratios:
helvetica
seems
group
ago
areas
...
: 11.4
: 10.8
: 10.2
: 8.4
: 8.3
verdana
Credit
ORDER
<FONT>
money
...
Do these make more sense?
:
:
:
:
:
28.8
28.4
27.2
26.9
26.5
Tuning on Held-Out Data
Now we’ve got two kinds of unknowns
Parameters: the probabilities P(Y|X), P(Y)
Hyperparameters, like the amount of smoothing to do:
k
How to learn?
Learn parameters from training data
Must tune hyperparameters on different data
Why?
For each value of the hyperparameters, train and test
on the held-out (validation)data
Choose the best value and do a final test on the test
data
How to Learn
Data: labeled instances, e.g. emails marked spam/ham
Training set
Held out (validation) set
Test set
Features: attribute-value pairs which characterize each x
Experimentation cycle
Evaluation
Learn parameters (e.g. model probabilities) on training set
Tune hyperparameters on held-out set
Compute accuracy on test set
Very important: never “peek” at the test set!
Held-Out
Data
Accuracy: fraction of instances predicted correctly
Overfitting and generalization
Training
Data
Want a classifier which does well on test data
Overfitting: fitting the training data very closely, but not generalizing
well to test data
Test
Data
What to Do About Errors?
Need more features– words aren’t enough!
Have you emailed the sender before?
Have 1K other people just gotten the same email?
Is the sending information consistent?
Is the email in ALL CAPS?
Do inline URLs point where they say they point?
Does the email address you by (your) name?
Can add these information sources as new variables in the
Naïve Bayes model
A Digit Recognizer
Input: x = pixel grids
Output: y = a digit 0-9
Example: Digit Recognition
Input: x = images (pixel grids)
Output: y = a digit 0-9
Setup:
Get a large collection of example images,
each labeled with a digit
Note: someone has to hand label all this data!
Want to learn to predict labels of new, future
digit images
Features: The attributes used to make the digit
decision
Pixels: (6,8)=ON
Shape Patterns: NumComponents,
AspectRatio, NumLoops
…
0
1
2
1
??
Naïve Bayes for Digits
Simple version:
One feature Fij for each grid position <i,j>
Boolean features
Each input maps to a feature vector, e.g.
Here: lots of features, each is binary valued
Naïve Bayes model:
Learning Model Parameters
1
0.1
1
0.01
1
0.05
2
0.1
2
0.05
2
0.01
3
0.1
3
0.05
3
0.90
4
0.1
4
0.30
4
0.80
5
0.1
5
0.80
5
0.90
6
0.1
6
0.90
6
0.90
7
0.1
7
0.05
7
0.25
8
0.1
8
0.60
8
0.85
9
0.1
9
0.50
9
0.60
0
0.1
0
0.80
0
0.80
Problem: Overfitting
2 wins!!
Classification (Decision Tree)
Slides credit: Guoping Qiu
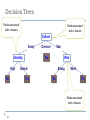
Trees
31
Node
Root
Leaf
Branch
Path
Depth
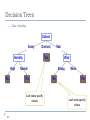
Decision Trees
A hierarchical data structure that represents data by implementing a divide
and conquer strategy
Can be used as a non-parametric classification method.
Given a collection of examples, learn a decision tree that represents it.
Use this representation to classify new examples
32
Decision Trees
Each node is associated with a feature (one of the elements of a feature
vector that represent an object);
Each node test the value of its associated feature;
There is one branch for each value of the feature
Leaves specify the categories (classes)
Can categorize instances into multiple disjoint categories – multi-class
Outlook
Sunny
Humidity
High
No
33
Overcast
Rain
Wind
Yes
Normal
Yes
Strong
No
Weak
Yes
Decision Trees
Play Tennis Example
Feature Vector = (Outlook, Temperature, Humidity, Wind)
Outlook
Sunny
Humidity
High
No
34
Overcast
Rain
Wind
Yes
Normal
Yes
Strong
No
Weak
Yes
Decision Trees
Node associated
with a feature
Node associated
with a feature
Outlook
Sunny
Humidity
High
No
Overcast
Rain
Yes
Wind
Normal
Yes
Strong
No
Weak
Yes
Node associated
with a feature
35
Decision Trees
36
Play Tennis Example
Feature values:
Outlook = (sunny, overcast, rain)
Temperature =(hot, mild, cool)
Humidity = (high, normal)
Wind =(strong, weak)
Decision Trees
Outlook = (sunny, overcast, rain)
One branch for
each value
Outlook
Sunny
Humidity
High
No
37
One branch for
each value
Overcast
Rain
Yes
Normal
Yes
Wind
One branch
for each value
Strong
No
Weak
Yes
Decision Trees
Class = (Yes, No)
Outlook
Sunny
Overcast
Humidity
High
No
Yes
Wind
Normal
Yes
Leaf nodes specify
classes
38
Rain
Strong
No
Weak
Yes
Leaf nodes specify
classes
Decision Trees
Design Decision Tree Classifier
39
Picking the root node
Recursively branching
Decision Trees
Picking the root node
Consider data with two Boolean attributes (A,B) and
two classes + and –
{
{
{
{
40
(A=0,B=0), - }:
(A=0,B=1), - }:
(A=1,B=0), - }:
(A=1,B=1), + }:
50 examples
50 examples
3 examples
100 examples
Decision Trees
Picking the root node
Trees looks structurally similar; which attribute should
we choose?
1 B
1 A
+
41
0
-
0
1 A
-
1 B
+
0
-
0
-
Decision Trees
Picking the root node
42
The goal is to have the resulting decision tree as small as possible
(Occam’s Razor)
The main decision in the algorithm is the selection of the next
attribute to condition on (start from the root node).
We want attributes that split the examples to sets that are
relatively pure in one label; this way we are closer to a leaf node.
The most popular heuristics is based on information gain,
originated with the ID3 system of Quinlan.
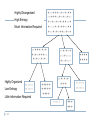
Entropy
S is a sample of training examples
p+ is the proportion of positive
examples in S
p- is the proportion of negative
examples in S
Entropy measures the impurity of S
EntropyS p log p p log p
43
p+
Highly Disorganized
High Entropy
Much Information Required
+--+++--+-+-++
--+++--+-+--+-+-+--+-+-++--+
+- --+-+-++--++
+--+-+-++--+-+
--+++-+-+
+-+-+++-+-+--+-+
Highly Organized
Low Entropy
-----------
Little Information Required
+++++
+++++
++++
--+-+-+
---+---+--+---
--+-+-+
-+++
----44
+++
+++
++++
++++
-----------
Information Gain
Gain (S, A) = expected reduction in entropy due to sorting on A
Gain( S , A) Entropy( S )
vValues( A )
Sv
S
Entropy( S v )
Values (A) is the set of all possible values for attribute A, Sv is the
subset of S which attribute A has value v, |S| and | Sv | represent the
number of samples in set S and set Sv respectively
Gain(S,A) is the expected reduction in entropy caused by knowing
the value of attribute A.
45
Information Gain
Example: Choose A or B ?
Split on A
1 A
100 +
3-
46
Split on B
1 B
0
100 -
100 +
50-
0
53-
Example
Play Tennis Example
Entropy(S)
9
5
14
log( 9
14
)
log( 5
)
14
14
0.94
47
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Example
Gain( S , A) Entropy( S )
vValues( A )
Humidity
High
3+,4E=.985
Sv
S
Entropy( S v )
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Normal
6+,1E=.592
Gain(S, Humidity) = .94 - 7/14 * 0.985 - 7/14 *.592 = 0.151
48
Example
Gain( S , A) Entropy( S )
vValues( A )
Wind
Sv
S
Entropy( S v )
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Weak Strong
6+2E=.811
3+,3E=1.0
Gain(S, Wind) = .94 - 8/14 * 0.811 - 6/14 * 1.0 = 0.048
49
Example
Gain( S , A) Entropy( S )
vValues( A )
Sv
S
Entropy( S v )
Outlook
Sunny
Overcast
Rain
1,2,8,9,11
2+,3-
3,7,12,13
4+,00.0
4,5,6,10,14
3+,2-
0.970
Gain(S, Outlook) = 0.246
50
0.970
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Example
Pick Outlook as the root
Outlook
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Gain(S, Humidity) = 0.151
Sunny
Overcast
Rain
Gain(S, Wind) = 0.048
Gain(S, Temperature) = 0.029
Gain(S, Outlook) = 0.246
51
Example
Pick Outlook as the root
Outlook
Sunny
1,2,8,9,11
2+,3?
Overcast
Yes
3,7,12,13
4+,0-
Rain
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
4,5,6,10,14
3+,2?
Continue until: Every attribute is included in path, or, all examples in the leaf
have same label
52
Example
Outlook
Sunny
1,2,8,9,11
2+,3?
Overcast
Yes
3,7,12,13
4+,0-
Rain
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
1
2
8
9
11
Sunny
Sunny
Sunny
Sunny
Sunny
Gain (Ssunny, Humidity) = .97-(3/5) * 0-(2/5) * 0 = .97
Gain (Ssunny, Temp) = .97- 0-(2/5) *1 = .57
Gain (Ssunny, Wind) = .97-(2/5) *1 - (3/5) *.92 = .02
53
Hot
Hot
Mild
Cool
Mild
High
Weak
High
Strong
High
Weak
Normal Weak
Normal Strong
No
No
No
Yes
Yes
Example
Outlook
Sunny
Overcast
Yes
Rain
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Humidity
High
No
Normal
Yes
Gain (Ssunny, Humidity) = .97-(3/5) * 0-(2/5) * 0 = .97
Gain (Ssunny, Temp) = .97- 0-(2/5) *1 = .57
Gain (Ssunny, Wind) = .97-(2/5) *1 - (3/5) *.92 = .02
54
Example
Outlook
Sunny
Overcast
Yes
Humidity
High
No
Normal
Rain
Day
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
?
4,5,6,10,14
3+,2-
Yes
Gain (Srain, Humidity) =
Gain (Srain, Temp) =
Gain (Srain, Wind) =
55
Example
Outlook
Sunny
Overcast
Rain
Yes
No
Normal
Yes
56
Outlook
Temperature
Humidity
Wind
Play
Tennis
Day1
Day2
Sunny
Sunny
Hot
Hot
High
High
Weak
Strong
No
No
Day3
Overcast
Hot
High
Weak
Yes
Day4
Rain
Mild
High
Weak
Yes
Day5
Rain
Cool
Normal
Weak
Yes
Day6
Rain
Cool
Normal
Strong
No
Day7
Overcast
Cool
Normal
Strong
Yes
Day8
Sunny
Mild
High
Weak
No
Day9
Sunny
Cool
Normal
Weak
Yes
Day10
Rain
Mild
Normal
Weak
Yes
Day11
Sunny
Mild
Normal
Strong
Yes
Day12
Overcast
Mild
High
Strong
Yes
Day13
Overcast
Hot
Normal
Weak
Yes
Day14
Rain
Mild
High
Strong
No
Wind
Humidity
High
Day
Strong
No
Weak
Yes
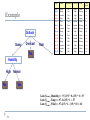
Tutorial/Exercise Questions
An experiment has produced the following 3d feature vectors X = (x1, x2, x3) belonging to two
classes. Design a decision tree classifier to class an unknown feature vector X = (1, 2, 1).
57
X = (x1, x2, x3)
x1
x2
x3
Classes
1
1
1
2
2
2
2
2
1
1
1
1
1
1
1
2
2
2
2
1
1
1
1
1
2
2
2
1
2
2
1
2
1
2
1
2
1
2
2
1
1
2
1
=?
Regression (Linear, smoothing)
Regression
Start with very simple example
What you learned in high school math
From a new perspective
Linear model
Linear regression
y=mx+b
hw(x) = y = w1 x + w0
Find best values for parameters
“maximize goodness of fit”
“maximize probability” or “minimize loss”
Regression: Minimizing Loss
Assume true function f is given by
y = f (x) = m x + b + noise
where noise is normally distributed
Then most probable values of parameters
found by minimizing squared-error loss:
Loss(hw ) = Σj (yj – hw(xj))2
Regression: Minimizing Loss
Regression: Minimizing Loss
Choose weights to minimize
sum of squared errors
Regression: Minimizing Loss
House price in $1000
1000
900
800
700
600
500
400
300
500
1000 1500 2000 2500 3000 3500
House size in square feet
Regression: Minimizing Loss
House price in $1000
1000
900
800
700
Loss
600
w0
500
w1
400
300
500
1000 1500 2000 2500 3000 3500
House size in square feet
y = w1 x + w0
Linear algebra gives
an exact solution to
the minimization
problem
Linear Algebra Solution
w1 =
M å xi yi - å xi å yi
Måx 2
i
(å x )
i
1
w1
w0 = å yi - å xi
M
M
2
Don’t Always Trust Linear Models
Regression by Gradient Descent
w = any point
loop until convergence do:
for each wi in w do:
wi = wi – α ∂Loss(w)
∂ wi
Loss
w0
w1
Multivariate Regression
You learned this in math class too
hw(x) = w ∙ x = w xT = Σi wi xi
The most probable set of weights, w*
(minimizing squared error):
w* = (XT X)-1 XT y
Overfitting
To avoid overfitting, don’t just minimize loss
Maximize probability, including prior over w
Can be stated as minimization:
Cost(h) = EmpiricalLoss(h) + λ Complexity(h)
For linear models, consider
Complexity(hw) = Lq(w) = ∑i | wi |q
L1 regularization minimizes sum of abs. values
L2 regularization minimizes sum of squares
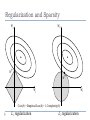
Regularization and Sparsity
w2
w2
w*
w*
w1
w1
Cost(h) = EmpiricalLoss(h) + λ Complexity(h)
L1 regularization
L2 regularization
Linear Separation
Perceptron, SVM
Linear Separator
Perceptron
ìï 1 if w x + w ³ 0
1
0
f (x) = í
ïî 0 if w1 x + w0 < 0
Perceptron Algorithm
Start with random w0, w1
Pick training example <x,y>
Update (α is learning rate)
w1 w1+α(y-f(x))x
w0 w0+α(y-f(x))
Converges to linear separator (if exists)
Picks “a” linear separator (a good one?)
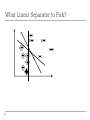
What Linear Separator to Pick?
What Linear Separator to Pick?
Maximizes the “margin”
Support Vector Machines
Support vector machines
•
Find hyperplane that maximizes the margin between
the positive and negative examples
xi positive ( yi 1) :
xi w b 1
xi negative ( yi 1) :
xi w b 1
For support vectors,
Distance between point
and hyperplane:
xi w b 1
| xi w b |
|| w ||
Therefore, the margin is 2 / ||w||
Support vectors
Margin
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Finding the maximum margin hyperplane
1.
2.
Maximize margin 2/||w||
Correctly classify all training data:
xi positive ( yi 1) :
xi w b 1
xi negative ( yi 1) :
xi w b 1
Quadratic optimization problem:
Minimize
1 T
w w
2
Subject to yi(w·xi+b) ≥ 1
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Finding the maximum margin hyperplane
•
Solution:
w i i yi xi
learned
weight
Support
vector
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Finding the maximum margin hyperplane
•
Solution:
w i i yi xi
b = yi – w·xi for any support vector
•
Classification function (decision boundary):
•
Notice that it relies on an inner product between the test
point x and the support vectors xi
Solving the optimization problem also involves
computing the inner products xi · xj between all pairs of
training points
•
w x b i i yi xi x b
Nonlinear SVMs
• Datasets that are linearly separable work out great:
x
0
• But what if the dataset is just too hard?
x
0
• We can map it to a higher-dimensional space:
x2
0
x
Slide credit: Andrew Moore
Nonlinear SVMs
•
General idea: the original input space can always be
mapped to some higher-dimensional feature space
where the training set is separable:
Φ: x → φ(x)
Slide credit: Andrew Moore
Nonlinear SVMs
•
The kernel trick: instead of explicitly computing the lifting
transformation φ(x), define a kernel function K such that
K(xi ,xj) = φ(xi ) · φ(xj)
(to be valid, the kernel function must satisfy Mercer’s
condition)
• This gives a nonlinear decision boundary in the original
feature space:
y ( x ) ( x ) b y K ( x , x ) b
i
i
i
i
i
i
i
i
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Nonlinear kernel: Example
•
Consider the mapping
( x) ( x, x 2 )
x2
( x) ( y) ( x, x 2 ) ( y, y 2 ) xy x 2 y 2
K ( x, y) xy x 2 y 2
Non-parametric classification
Nonparametric Models
If the process of learning good values for parameters is
prone to overfitting, can we do without parameters?
Nearest-Neighbor Classification
Nearest neighbor for digits:
Take new image
Compare to all training images
Assign based on closest example
Encoding: image is vector of intensities:
What’s the similarity function?
Dot product of two images vectors?
Usually normalize vectors so ||x|| = 1
min = 0 (when?), max = 1 (when?)
x2
Earthquakes and Explosions
7.5
7
6.5
6
5.5
5
4.5
4
3.5
3
2.5
4.5
5
5.5
6
x1
6.5
7
Using logistic regression (similar to linear regression) to do linear classification
K=1 Nearest Neighbors
x1
7.5
7
6.5
6
5.5
5
4.5
4
3.5
3
2.5
4.5
5
5.5
6
x2
Using nearest neighbors to do classification
6.5
7
K=5 Nearest Neighbors
x1
7.5
7
6.5
6
5.5
5
4.5
4
3.5
3
2.5
4.5
5
5.5
6
x2
6.5
Even with no parameters, you still have hyperparameters!
7
Edge length of neighborhood
Curse of Dimensionality
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
25
50
75 100 125 150 175 200
Number of dimensions
Average neighborhood size for 10-nearest neighbors, n dimensions, 1M uniform points
Proportion of points in exterior shell
Curse of Dimensionality
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
25
50
75 100 125 150 175 200
Number of dimensions
Proportion of points that are within the outer shell, 1% of thickness of the hypercube
Summary
Machine Learning
Classification (Naïve Bayes)
Regression (Linear, Smoothing)
Linear Separation (Perceptron, SVMs)
Non-parametric classification (KNN)
Machine Learning Lingo
What?
Parameters
Structure
Hidden concepts
What from?
Supervised
Unsupervised
Reinforcement
Self-supervised
What for?
Prediction
Diagnosis
Compression
Discovery
How?
Passive
Active
Online
Offline
Output?
Classification
Regression
Clustering
Ranking
Details??
Generative
Discriminative
Smoothing