Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Statistics I.
Tamás Dusek
Széchenyi István University
2016
Historical meaning of statistics
• The term „statistics” have many different shades of
meaning
• In the older, original sense of the word (18th century
meaning), statistics was used for any descriptive
information about the state of society
• By the 18th century, the term "statistics" designated the
systematic collection of demographic and economic data
by states
• Today it is also used for descriptive data which have a
quantitative nature and a numerical form
• In this sense statistics is a method of historical research,
it is a description in numerical terms of historical events
that happened in a definite period of time with definite
groups of people in a definite geographical area.
Modern meaning of statistics
• The previous meaning has nothing in common
with its modern natural science meaning
• Accordingly statistics deals with mass
phenomena and it enables us to analyze
systems with very large numbers of particles
• In the field of natural sciences, statistics is a
method of inductive research. To take an
example: quantum mechanics deals with the fact
that we do not know how a particle will behave in
an individual instance. But we know what pattern
of behavior can possibly occur and the
proportion in which these patterns really occur.
Modern meaning of statistics
Meaning I.:
• Statistics is the mathematics of the collection,
organization, and interpretation of numerical data,
especially the analysis of population characteristics by
inference from sampling
• Classification and interpretation of quantitative data in
accordance with probability theory and the application of
methods such as hypothesis testing to them
• The mathematical study of the theoretical nature of such
distributions and tests.
Meaning II.:
• quantitative data on any subject
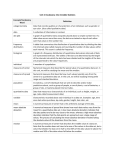
Key events in the history of statistics
Year
Event
Person
1532
First weekly data on deaths in London
Sir W. Petty
1539
Start of data collection on baptisms, marriages, and deaths in France
1608
Beginning of parish registry in Sweden
1662
First published demographic study based on bills of mortality
J. Graunt
1693
Publ. of An estimate of the degrees of mortality of mankind drawn from curious tables of the births and funerals at the city of
Breslaw with an attempt to ascertain the price of annuities upon lives
E. Halley
1713
Publ. of Ars Conjectandi
J. Bernoulli
1714
Publ. of Libellus de Ratiocinus in Ludo Aleae
C. Huygens
1714
Publ. of The Doctrine of Chances
A. De Moivre
1763
Publ. of An essay towards solving a problem in the Doctrine of Chances
Rev. Bayes
1790
First Census in the USA
1809
Publ. of Theoria Motus Corporum Coelestium
C.F. Gauss
1812
Publ. of Théorie analytique des probabilités
P.S. Laplace
1834
Establishment of the Statistical Society of London
1839
Establishment of the American Statistical Association (Boston)
1869
Establishment of the Central Statistical Office, Hungary
Key events in the history of statistics
Year
Event
Person
1889
Publ. of Natural Inheritance
F. Galton
1900
Development of the chi^2 test
K. Pearson
1901
Publ. of the first issue of Biometrika
F. Galton et al.
1903
Development of Principal Component Analysis
K. Pearson
1908
Publ. of The probable error of a mean
``Student''
1910
Publ. of An introduction to the theory of statistics
G.U. Yule
1933
Publ. of On the empirical determination of a distribution
A.N. Kolmogorov
1935
Publ. of The Design of Experiments
R.A. Fisher
1936
Publ. of Relations between two sets of variables
H. Hotelling
1972
Publ. of Regression models and life tables
D.R. Cox
1972
Publ. of Generalized linear models
J.A. Nelder and R.W.M. Wedderburn
1979
Publ. of Bootstrap methods: another look at the jackknife
B. Efron
Uses of Statistics
Almost all fields of study benefit from
the application of statistical methods
Economics, Sociology, Genetics, Insurance,
Biology, Criminology, Polling, Retirement
Planning, automobile fatality rates, and many
more too numerous to mention.
Statistics is objective, interpretation of
statistics not entirely objective.
Statistics is the science of collecting,
organizing, summarising, analysing,
and making inference from data
Descriptive statistics:
collecting, organizing,
summarising, analysing,
and presenting data
Inferential statistics:
Making inferences,
hypothesis testing
Determining relationship,
and making prediction
A simple general taxonomy of
statistical methods
Image of statistics in pop culture is often negative,
based on misunderstandings, mistakes or jokes
Some famous antistatistician
quotations
• “I only believe in statistics that I doctored myself.”
(Churchill)
• „I never believe in statitistics if I didn’t make it myself.”
(Churchill)
• "There are three kinds of lies: lies, damned lies, and
statistics." (origin is uncertain; attributed to Disraeli, but
popularised by Mark Twain)
• Statistics is a precise and logical method for stating a
half truth inaccurately.
• It is proven that the celebration of birthdays is healthy.
Statistics show that those people who celebrate the most
birthdays become the oldest.
The statistician
Statistical biases
Basic Terms
Population: A collection, or set, of
individuals or objects or events whose
properties are to be analyzed.
Two kinds of populations: finite or infinite.
Sample: A subset of the population.
Variable: A characteristic about each individual element of a population
or sample.
Observational unit: the individual entities whose characteristics are
measured
Data (singular): The value of the variable associated with one element
of a population or sample. This value may be a number, a word, or
a symbol.
Data (plural): The set of values collected for the variable from each of
the elements belonging to the sample.
Experiment: A planned activity whose results yield a set of data.
Parameter: A numerical value summarizing all the data of an entire
population.
Statistic: A numerical value summarizing the sample data.
Example: A college dean is interested in learning about the average age of
faculty. Identify the basic terms in this situation.
The observational unit is the persons of faculty.
The population is the age of all faculty members at the college.
A sample is any subset of that population. For example, we might select 10
faculty members and determine their age.
The variable is the “age” of each faculty member.
One data would be the age of a specific faculty member.
The data would be the set of values in the sample.
The experiment would be the method used to select the ages forming the
sample and determining the actual age of each faculty member in the
sample.
The parameter of interest is the “average” age of all faculty at the college.
The statistic is the “average” age for all faculty in the sample.
Two kinds of variables:
Qualitative, or Attribute, or Categorical, Variable: A
variable that categorizes or describes an element of a
population.
Note: Arithmetic operations, such as addition and
averaging, are not meaningful for data resulting from a
qualitative variable.
Quantitative, or Numerical, Variable: A variable that
quantifies an element of a population.
Note: Arithmetic operations such as addition and
averaging, are meaningful for data resulting from a
quantitative variable.
Example: Identify each of the following examples as attribute
(qualitative) or numerical (quantitative) variables.
1. The residence hall for each student in a statistics class. (Attribute)
2. The amount of gasoline pumped by the next 10 customers at a MOL
gasoline station. (Numerical)
3. The amount of radon in the basement of each of 25 homes in a new
development. (Numerical)
4. The color of the baseball cap worn by each of 20 students.
(Attribute)
5. The length of time to complete a mathematics homework
assignment. (Numerical)
6. The state in which each truck is registered when stopped and
inspected at a weigh station. (Attribute)
Qualitative and quantitative variables may be further
subdivided
Variables
Quantitative
•Discrete (counting)
•Continuous (measurement)
Qualitative
•Ordinal
•Categorical/Attribute
Nominal Variable: A qualitative variable that categorizes (or describes,
or names) an element of a population.
Ordinal Variable: A qualitative variable that incorporates an ordered
position, or ranking.
Discrete Variable: A quantitative variable that can assume a countable
number of values. Intuitively, a discrete variable can assume values
corresponding to isolated points along a line interval. That is, there
is a gap between any two values.
Continuous Variable: A quantitative variable that can assume an
uncountable number of values. Intuitively, a continuous variable can
assume any value along a line interval, including every possible
value between any two values.
Note:
1.
In many cases, a discrete and
continuous variable may be
distinguished by determining
whether the variables are related
to a count or a measurement.
2.
Discrete variables are usually
associated with counting. If the
variable cannot be further
subdivided, it is a clue that you
are probably dealing with a
discrete variable.
3.
Continuous variables are usually
associated with measurements.
The values of discrete variables
are only limited by your ability to
measure them.
4.
Countinuous variables are
recorded often as a discrete
variable.
Example
Discrete
The number of eggs that hens lay; for example, 3 eggs a day.
The number of cars in a parking lot.
Number of the inhabitants of a town.
Continuous
The amounts of milk that cows produce; for example, 8.343115 liter a
day.
The temperature.
Age of a person.
Example: Identify each of the following as examples of
qualitative or numerical variables:
1. The temperature in Győr, Hungary at 12:00 pm on any
given day.
2. Whether or not a 6 volt lantern battery is defective.
3. The weight of a lead pencil.
4. The length of time billed for a long distance telephone
call.
5. The brand of cereal children eat for breakfast.
6. The type of book taken out of the library by an adult.
Levels of measurement
1 Nominal
1A Coding
1B Qualitativ data, categorical data (gender,
nationality, ethnicity, language, genre, style,
biological species)
2 Ordinal – rank order
3 Interval - degree of difference; however zero is
arbitrary
4 Ratio
4A continuous quantity with true zero
4B discrete quantity
Importance of the levels of measurement
• Helps you decide what statistical analysis is appropriate
on the values that were assigned
• Helps you decide how to interpret the data from that
variable
Dangers to Avoid
• Attaching unwarranted significance to aspects of the
numbers that do not convey meaningful information
• Failing to simply data when would easily do so
• Manipulating our data in ways that destroy information
• Performing meaningless statistical operations on the
data
Nominal and ordinal measurement
• Nominal measurement: not
measurement in the everyday sense of
the word; the value does not imply any
ordering of the cases, for example, shirt
numbers in football; Even though player
17 has higher number than player 7, you
can’t say from the data that he’s greater
than or more than the other.
When attributes can be rank-ordered
• Distances between attributes do not have
any meaning, for example, the distance
between the winner of a sport
competition and the second one, and
between the second and third one
The Hierarchy of Levels
Ratio
Interval
Ordinal
Nominal
Absolute zero
Distance is meaningful
Attributes can be ordered
Attributes are only named; weakest
Types of data
• Nominal and ordinal are qualitative (categorical) levels of
measurement.
• Interval and ratio are quantitative levels of measurement.
VARIABLES
QUANTITATIVE
RATIO
Pulse rate
Height
INTERVAL
36o-38oC
QUALITATIVE
ORDINAL
Social class
NOMINAL
Gender
Ethnicity
Example: Identify each of the following as examples of (1)
nominal, (2) ordinal, (3) discrete, or (4) continuous
variables:
1. The length of time until a pain reliever begins to work.
2. The number of chocolate chips in a cookie.
3. The number of colors used in a statistics textbook.
4. The brand of refrigerator in a home.
5. The overall satisfaction rating of a new car.
6. The number of files on a computer’s hard disk.
7. The pH level of the water in a swimming pool.
8. The number of staples in a stapler.
Measure and Variability
• No matter what the response variable: there will
always be variability in the data.
• One of the primary objectives of statistics:
measuring and characterizing variability.
• Controlling (or reducing) variability in a
manufacturing process: statistical process
control.
Methods used to collect data
Census: A 100% survey. Every element of the population
is listed. Seldom used: difficult and time-consuming to
compile, and expensive.
Survey: Data are obtained by sampling some of the
population of interest. The investigator does not modify
the environment.
Experiment: The investigator controls or modifies the
environment and observes the effect on the variable
under study.
Administrative resources: The source of the data is an
administrative activity.
Other
Surveys
Surveys may be administered in a variety of ways, e.g.
•
Personal Interview,
•
Telephone Interview,
•
Self Administered Questionnaire, and
•
Internet
Questionnaire design principles:
1.
Keep the questionnaire as short as possible.
2.
Ask short, simple, and clearly worded questions.
3.
Start with demographic questions to help respondents get started
comfortably.
4.
Use dichotomous (yes|no) and multiple choice questions.
5.
Use open-ended questions cautiously.
6.
Avoid using leading-questions.
7.
Pretest a questionnaire on a small number of people.
8.
Think about the way you intend to use the collected data when
preparing the questionnaire.
Not everything that counts can be
counted
5 (Quantity) Happy (Quality) Kids
Univariate descriptive statistics
• After collecting data, the first task is to
organize and simplify the data so that it is
possible to get a general overview of the
results.
• This is the goal of descriptive statistical
techniques.
• One method for simplifying and organizing
data is to present them in graphical way
Graphical presentation
Graphs and statistics are often used to persuade.
Advertisers and others may accidentally or intentionally
present information in a misleading way.
For example, art is often used to make a graph more
interesting, but it can distort the relationships in the data.
Questions to Ask When Looking at Data and/or Graphs:
• Is the information presented correctly?
• Is the graph trying to influence you?
• Does the scale use a regular interval?
• What impression is the graph giving you?
Pie charts and bar graphs
• Both is used for categorical variables
• Pie charts show the amount of data that
belongs to each category as a proportional part
of a circle
• Bar graphs show the amount of data that
belongs to each category as proportionally sized
rectangular areas
• Example: The table below lists the number of
automobiles sold last week by day for a local dealership.
• Describe the data using a pie chart (circle graph) and a
bar graph
Day Number Sold
Monday
15
Tuesday
23
Wednesday
35
Thursday
11
Friday
12
Saturday
42
Pie chart
Automobiles Sold Last Week
Bar graph
Automobiles Sold Last Week
Frequency
Pareto Diagram
• Pareto Diagram: A bar graph with the bars arranged
from the most numerous category to the least numerous
category. It includes a line graph displaying the
cumulative percentages and counts for the bars.
Used to identify the number and type of defects that
happen within a product or service
Separates the “vital few” from the “trivial many”
The Pareto diagram is often used in quality control
applications
Pareto diagram example
The final daily inspection defect report for a cabinet
manufacturer is given in the table below:
Defect
Number
Dent
5
Stain
12
Blemish
43
Chip
25
Scratch
40
Others
10
Daily Defect Inspection Report
1)
140
100
120
80
100
60
80
Count
Percent
60
40
40
20
20
0
Defect:
Count
Percent
Cum%
0
Blemish
Scratch
Chip
Stain
Others
Dent
43
31.9
31.9
40
29.6
61.5
25
18.5
80.0
12
8.9
88.9
10
7.4
96.3
5
3.7
100.0
2) The production line should try to eliminate blemishes and
scratches. This would cut defects by more than 50%.
Frequency distributions and histograms
Frequency distributions and histograms are used to summarize large data sets
Used for quantitative variables
Frequency Distribution: A listing, often expressed in chart form, that pairs each value of
a variable with its frequency
Ungrouped Frequency Distribution: Each value of x in the distribution stands alone
Grouped Frequency Distribution: Group the values into a set of classes
1. A table that summarizes data by classes, or class intervals
2. In a typical grouped frequency distribution, there are usually 5-12 classes of equal
width
3. The table may contain columns for class number, class interval, tally (if constructing
by hand), frequency, relative frequency, cumulative relative frequency, and class
midpoint
4. In an ungrouped frequency distribution each class consists of a single value
Guidelines for constructing a frequency
distribution
1. All classes should be of the same width. In the case of very uneven
distribution of the data or outliers, class width can be different.
2. Classes should be set up so that they do not overlap and so that
each piece of data belongs to exactly one class
3. For problems in the text, 5-12 classes are most desirable. The
square root of n is a reasonable guideline for the number of classes
if n is less than 150.
4. Use a system that takes advantage of a number pattern, to
guarantee accuracy
5. If possible, an even class width is often advantageous
Histogram
Histogram: A bar graph representing a frequency distribution of a
quantitative variable. A histogram is made up of the following
components:
1. A title, which identifies the population of interest
2. A vertical scale, which identifies the frequencies in the various
classes
3. A horizontal scale, which identifies the variable x. Values for the
class boundaries or class midpoints may be labeled along the xaxis. Use whichever method of labeling the axis best presents the
variable.
Notes:
The relative frequency is sometimes used on the vertical scale
It is possible to create a histogram based on class midpoints
Example: A recent survey of Roman Catholic nuns
summarized their ages in the table below.
Age
Frequency
Class Midpoint
-----------------------------------------------------------20 up to 30
34
25
30 up to 40
58
35
40 up to 50
76
45
50 up to 60
187
55
60 up to 70
254
65
70 up to 80
241
75
80 up to 90
147
85
Roman Catholic Nuns
200
Frequency
100
0
25
35
45
55
Age
65
75
85
Special histogram: age pyramids
Terms Used to Describe Histograms
Symmetrical: Both sides of the distribution are identical mirror images.
There is a line of symmetry.
Uniform (Rectangular): Every value appears with equal frequency
Skewed: One tail is stretched out longer than the other. The direction
of skewness is on the side of the longer tail. (Positively skewed vs.
negatively skewed)
J-Shaped: There is no tail on the side of the class with the highest
frequency
Bimodal: The two largest classes are separated by one or more
classes. Often implies two populations are sampled.
Normal: A symmetrical distribution is mounded about the mean and
becomes sparse at the extremes
The mode is the value that occurs with greatest
frequency
The modal class is the class with the greatest
frequency
A bimodal distribution has two high-frequency
classes separated by classes with lower
frequencies
Graphical representations of data should include a
descriptive, meaningful title and proper
identification of the vertical and horizontal scales
Ogive: A line graph of a cumulative frequency or cumulative relative
frequency distribution. An ogive has the following components:
1. A title, which identifies the population or sample
2. A vertical scale, which identifies either the cumulative frequencies or
the cumulative relative frequencies
3. A horizontal scale, which identifies the upper class boundaries. Until
the upper boundary of a class has been reached, you cannot be
sure you have accumulated all the data in the class. Therefore, the
horizontal scale for an ogive is always based on the upper class
boundaries.
Note:
Every ogive starts on the left with a relative frequency of zero at the
lower class boundary of the first class and ends on the right with a relative
frequency of 100% at the upper class boundary of the last class.
This graph is an ogive using cumulative relative
frequencies:
1.0
0.9
0.8
0.7
Cumulative
Relative
Frequency
0.6
0.5
0.4
0.3
0.2
0.1
0.0
0
4
8
12
Test Score
16
20
24
28
Factors that make a graph misleading
•
•
•
•
•
•
•
Y-axis scale is too big or too small
Y-axis skips numbers, or does not start at zero
X-axis scale is too big or too small
X-axis skips numbers, or does not start at zero
Axes are not labeled
Data is left out
Exaggerated area or volume
Misleading graphs
This title tells the reader
what to think (that there
are huge increases in
price).
The scale moves from 0 to 80,000 in
the same amount of space as 80,000 to
81,000.
The actual increase in price is 2,000 pounds, which is less than a 3%
increase.
The graph shows the second bar as being 3 times the size of the first bar,
which implies a 300% increase in price.
A more accurate graph
An unbiased title
A scale with a
regular interval.
This shows a more accurate picture of the increase.
Scaling
Because the scale leaves out 0 to 100 (in school play ticket sales
example), the bar heights make it appear that the sixth grade sold
about three times as many tickets as either of the other two
grades. In fact, the sixth grade sold only about 20% more.
150
Preferred Juice Flavors
148
146
144
142
140
Grape
Cherry
Apple
From
CNN.com
The difference in percentage points between Democrats and
Republicans (and between Democrats and Independents) is 8%
(62 – 54). Since the margin of error is 7%, it is likely that there is
even less of a difference.
The graph implies that the Democrats were 8 times more likely to
agree with the decision. In truth, they were only slightly more
likely to agree with the decision.
The graph does not accurately demonstrate that a majority of all
groups interviewed agreed with the decision.
Correct versus incorrect graph
While retail sales do go down in April 2002, the
title doesn’t accurately reflect what the rest of the
graph shows. Yes, the sales do rise and fall over a
period of a year and a half, but in general, they
have been steadily rising since November 1998.
Retail Sales from November 1998 to April 2000
$300.00
Billions
$250.00
$200.00
$150.00
$100.00
$50.00
$0.00
Nov- Dec- Jan- Feb- Mar- Apr- May- Jun- Jul- Aug- Sep- Oct- Nov- Dec- Jan- Feb- Mar- Apr98 98 99 99 99 99
99 99 99
99 99 99
99 99 00 00 00 00
Month
Month
Ap
ril
ar
ch
M
Fe
br
ua
ry
ry
Ja
nu
a
be
r
De
ce
m
be
r
$300.00
$250.00
$200.00
$150.00
$100.00
$50.00
$0.00
No
ve
m
The original graph seems to be
trying to convince us that April sales
have very obviously fallen, these
two graphs tell us the opposite. The
title for the third graph has been
changed completely to give the
opposite minute.
Billions
Retail Sales Rise
First Year
Second Year
The scale does not have a regular
interval.
The scale is so compressed that it’s hard to
see any difference among the brands.
Irregular scale axes
1993, 1996 and
1998 are missing.
Exaggerated use of Area or Volume
Number of
Singles Sold
Number of Singles Sold
1995 1996 1997 1998
The Brown column looks bigger than the
purple column.
.
Exaggerated use of Area or Volume
Sales at Gerry’s Milkbar have doubled
from 2014 to 2015.
2014
2015
The 2015 volume is eight times bigger
than the 2014 volume.
Exaggerated use of Volume
The new iPad battery gained 70% in capacity.
They did this by making the battery on right
70% taller than the battery on left.
The perspective puts barrel 1979 at the forefront and
barrel 1973 at the back. This effectively draws
reader’s eyes to the 1979 barrel first and then forces
him read the rest of the years in descending order.
Supporting this deceptive tactic is the fact that only
the foremost barrels have complete year to read.
The rest are indicated with only the last two digits, as
in ‘76. The makers of the graph intend for the
audience to read in reverse chronological order,
which has the effect of making oil prices seem to fall.
Secondly, the perspective makes it hard to judge the
numerical difference between each barrel. For
example, even though barrel 1975 appears to be
over two thirds the height of 1976, in reality, the
difference between them is only $0.95.
An other misleading aspect is that this pictograph doesn’t
contain a scale or axis’ of any kind. Without it, the
reader’s attention might be directed to the area of
each barrel instead.
The way in which the barrels are labeled seem
somewhat awkward. Shouldn’t the prices be on the
barrel instead of years? Prices written on the barrel
will clarify that it is the cost that is changing, not the
years. And with more space to indicate years,
readers won’t be forced to read in reverse.
Pie chart should add up to 100%
Extremely bad pie chart
Preudo-pye chart
What do these colors mean?
Why is it divided into quadrants?
Misleading scaling of two y-axes
Problems:
• Only shows five
numbers
• Y-axis is broken twice
• The top section is
inverse of the bottom
• Three dimensions for
no reasons
Problems:
• Missing y-axis
• the points don’t
follow a straight line
• The four points are
not equidistant with
time
There are only two distinct age categories,
grid lines are unnecessary
Area is
independent
from the
represented
numbers
Meaningless map due to the lack of
differentiation
Absolute versus relative magnitudes
Measures of central tendency
MEAN
Average or arithmetic mean of the data
The value which comes half way when
MEDIAN
the data are ranked in order
MODE
Most common value observed
Mean (μ or x )
• The arithmetic
average (add all of
the scores together,
then divide by the
number of scores)
• μ = ∑x / n
x
x
i
n
• Note: The mean can
be greatly influenced
by outliers
Median
•
The middle number (just like the median strip that divides
a highway down the middle; 50/50)
To find the median:
1. Rank the data
2. Determine the depth of the median:
3. Determine the value of the median
•
Used when data is not normally distributed
•
Often hear about the median price of housing
Example: Find the median for the set of data:{4, 8, 3, 8, 2, 9,
2, 11, 3}
1. Rank the data: 2, 2, 3, 3, 4, 8, 8, 9, 11
2. Find the depth: (9+1)/2=5
3. The median is the fifth number from either end in the
ranked data: 4
If n is odd Median = middle value; else, median = mean of
two middle values
Mean versus median
Mean
• Interval data with and approximately symmetric
distribution
Median
• Interval data
• ordinal data
Mean is sensitive to outliers, median is not
Mode
Mode: The mode is the value of x
that occurs most frequently
Note: If two or more values in a
sample are tied for the highest
frequency (number of
occurrences), there is no mode
Mode can be the minimum or
maximum value.
Potential Problem with Means
Mean
Mean
Mean is sensitive to outliers, median and mode are not;
mode can be more „typical” than mean
Mean, Median, or Mode?
• Mean
– If the sum of all values is meaningful
– Incorporates all available information
• Median
– Intuitive sense of central tendency with outliers
– What is “typical” of a set of values?
• Mode
– When data can be grouped into distinct types,
categories (categorical data)
• In a normal distribution,
mean and median are the
same
• If median and mean are
different, indicates that
the data are not normally
distributed
Arithmetic and geometric means
The Arithmetic Mean
•Is the sum of the observations divided by the
total number of observations
(a1+ ...+aN)/N
The Geometric Mean
* Is the nth root of the product of the
observations
* Can also be calculated by taking the
antilog of the arithmetic mean.
(a1· ... ·aN)1/N
xG n x1 x2 xi xn
1/ n
xi
i 1
n
~ Used when several quantities are added
together to produce a total.
~ Used when several quantities are multiplied
by a factor to give a product.
- this is the midpoint of the added numbers if
those numbers are stretched out on a line
- this is the average of the factors that
contribute to a product.
Always less than or equal to the arithmetic
mean (only equal to it when the components
of the set are equal)
Example of the use of geometric mean
If we had an investment that returned 10% the first
year, 60% the second, and 20% the third what is
the average rate of return? (not 30%!)
To calculate this, remember 10, 60, and 20
percents are the same as multiplying the
investment by 1.10, 1.60, and 1.20.
To get the geometric mean calculate:
(1.10 x 1.60 x 1.20)1/3 = 1.283 or an average return
of 28,3% (not 30%!)
Harmonic mean
We could get the harmonic
mean by:
Taking the number of terms (n) in
a set and dividing it by
The sum of the terms’ reciprocals
xH
n
1
i 1 x
i
n
Example of the use of Harmonic mean
Suppose you spend 600 Ft on pills costing 30 Ft per
dozen, and 600 on pills costing 20 Ft per dozen. What
was the average price of the pills you bought?
You spent 1200 on 50 dozen pills, so the average cost is
1200/50=24.
This also happens to be the harmonic mean of 20 and 30:
2
1 1
30 20
24
The arithmetic, geometric, and harmonic means are related
in the following way:
the arithmetic mean > the geometric mean > the
harmonic mean
Unless the terms of the set are equal in which case the
harmonic, arithmetic, and geometric means will all be the
same.
Measures of position
• Measures of position are used to describe the
relative location of an observation
• Quartiles and percentiles are two of the most
popular measures of position
• An additional measure of central tendency, the
midquartile, is defined using quartiles
• Quartiles are part of the 5-number summary
Quartiles: Values of the variable that divide the ranked
data into quarters; each set of data has three quartiles
1. The first quartile, Q1, is a number such that at most 25%
of the data are smaller in value than Q1 and at most 75%
are larger
2. The second quartile, Q2, is the median
3. The third quartile, Q3, is a number such that at most 75%
of the data are smaller in value than Q3 and at most
25% are larger
Ranked data, increasing order
25%
L
25%
Q1
25%
Q2
25%
Q3
H
Box-and-Whisker Display
• Box-and-Whisker Display: A graphic representation of the 5number summary:
• The five numerical values (smallest, first quartile, median, third
quartile, and largest) are located on a scale, either vertical or
horizontal
• The box is used to depict the middle half of the data that lies
between the two quartiles
• The whiskers are line segments used to depict the other half of the
data
• One line segment represents the quarter of the data that is smaller
in value than the first quartile
• The second line segment represents the quarter of the data that is
larger in value that the third quartile
Importance: it helps to interpret and
represent data. It gives a visual
representation of data.
• Data set: 85,92,78,88,90,88,89
78
85
Lower quartile
88
88
Median
89
90 92
Upper quartile
Measures of the shape of data
• Shape of data is measured by
– Skewness
– Kurtosis
There are 4 central moments:
- The first central moment, r=1, is the sum of the
difference of each observation from the sample
average (arithmetic mean), which always equals 0
- The second central moment, r=2, is variance.
- The third central moment, r=3, is skewness.
Skewness describes how the sample differs in shape from
a symmetrical distribution.
If a normal distribution has a skewness of 0, right skewed is
greater then 0 and left skewed is less than 0.
Skewness
Negatively skewed distributions, skewed to the left, occur
when most of the scores are toward the high end of the
distribution.
In a normal distribution where skewness is 0, the mean,
median and mode are equal.
In a negatively skewed distribution, the mode > median >
mean.
Positively skewed distributions occur when most of the
scores are toward the low end of the distribution.
In a positively skewed distribution, mode< median< mean.
Kurtosis
Kurtosis is the 4th central moment.
This is the “peakedness” of a distribution.
It measures the extent to which the data are
distributed in the tails versus the center of the
distribution
There are three types of peakedness.
Leptokurtic- very peaked, kurtosis +
Platykurtic – relatively flat, kurtosis Mesokurtic – in between, kurtosis 0
Measures of dispersion
• Measures of central tendency alone cannot completely
characterize a set of data. Two very different data sets
may have similar measures of central tendency.
• Measures of dispersion are used to describe the spread,
or variability, of a distribution
• Common measures of dispersion: range, variance, and
standard deviation
• Range: The difference in value between the highestvalued (H) and the lowest-valued (L) pieces of data: H-L
• The interquartile range is the difference between the
first and third quartiles. It is the range of the middle 50%
of the data
Same means, but very different distributions
Mean
We need to come up with some way of measuring
not just the average, but also the spread of the
distribution of our data.
The Standard Deviation is a number that
measures how far away each number in a set of
data is from their mean.
If the Standard Deviation is large it means the
numbers are spread out from their mean.
If the Standard Deviation is small it means the
numbers are close to their mean.
Standard deviation
Calculating the standard deviation.
1. Find the mean of the data.
2. Subtract the mean from each
value.
3. Square each deviation of the
mean.
4. Find the sum of the squares.
5. Divide the total by the number of
items – this is the variance.
6. Take the square root of the
variance.
( x )
n
2
This is the
Standard
Deviation
72
76
80
80
81
83
84
85
85
89
Distance
from
Mean
Distances
Squared
- 9.5
- 5.5
- 1.5
- 1.5
- 0.5
1.5
2.5
3.5
3.5
7.5
90.25
30.25
2.25
2.25
0.25
2.25
6.25
12.25
12.25
56.25
Sum:
214.5
(10 - 1)
= 23.8
= 4.88
Coefficient of Variation
• Coefficient of variation (CV) measures the spread of a set of
data as a proportion of its mean.
• It is the ratio of the sample standard deviation to the sample
mean
s
CV 100%
x
• It is sometimes expressed as a percentage
• It is a dimensionless number that can be used to compare the
amount of variance between populations with different means
Moments of the Distribution Summary
• Statistics that describe the shape of the
distribution, using formulae that are similar to
those of the mean and variance
• 1st moment - Mean (describes central value)
• 2nd moment - Variance (describes dispersion)
• 3rd moment - Skewness (describes asymmetry)
• 4th moment - Kurtosis (describes peakedness)
Inter-quartile range
97.5th Centile
12
10
75th Centile
8
6
MEDIAN
(50th centile)
4
2
25th Centile
0
-2
N=
74
27
Female
Male
Inter-quartile
range
2.5th Centile
STANDARD DEVIATION – MEASURE OF THE SPREAD
OF VALUES OF A SAMPLE AROUND THE MEAN
THE SQUARE OF THE
SD IS KNOWN AS
THE VARIANCE
2
SD
Sum(Value Mean)
Number of values
SD decreases as a function of:
• smaller spread of values
about the mean
• larger number of values
IN A NORMAL
DISTRIBUTION, 95%
OF THE VALUES WILL
LIE WITHIN 2 SDs OF
THE MEAN
NORMAL DISTRIBUTION
THE EXTENT OF THE
‘SPREAD’ OF DATA
AROUND THE MEAN –
MEASURED BY THE
STANDARD DEVIATION
MEAN
CASES DISTRIBUTED
SYMMETRICALLY ABOUT
THE MEAN
SKEWED DISTRIBUTION
MEAN
MEDIAN – 50% OF
VALUES WILL LIE
ON EITHER SIDE OF
THE MEDIAN
I’m so confused!!
Distributions, examples
Normal distribution
Skewed distribution
• Height
• Weight
• Haemoglobin
• Bankers’ bonuses
• Number of
marriages
Bivariate data
Bivariate Data: Consists of the values of two
different response variables that are obtained
from the same population of interest.
Four combinations of variable types:
1. Both variables are qualitative (attribute).
2. One variable is qualitative (attribute) and the
other is quantitative (numerical).
3. Both variables are ordinal.
4. Both variables are quantitative (both
numerical).
Dependent or independent variables?
• basic question: can the state of one
variable be predicted from the state of
another variable?
• if not, they are independent
• if partly, the connection is stochastic
• If perfectly, they are dependent
Two Qualitative Variables
When bivariate data results from two qualitative (attribute
or categorical) variables, the data is often arranged on
a cross-tabulation or contingency table.
Example: A survey was conducted to investigate the
relationship between preferences for television, radio,
or newspaper for national news, and gender. The
results are given in the table below.
Male
Female
TV
280
115
Radio
175
275
NP
305
170
This table may be extended to display the marginal
totals (or marginals). The total of the marginal
totals is the grand total.
Contingency tables often show percentages
(relative frequencies). These percentages are
based on the entire sample or on the subsample
(row or column) classifications.
Male
Female
Col. Totals
TV Radio
280
175
115
275
395
450
NP Row Totals
305
760
170
560
475
1320
Percentages based on the grand total (entire sample):
The previous contingency table may be converted to
percentages of the grand total by dividing each
frequency by the grand total and multiplying by 100.
For example, 175 becomes 13.3%
175 100 13.3
1320
Male
Female
Col. Totals
TV Radio
21,2 13,3
8,7 20,8
29,9 34,1
NP Row Totals
23,1
57,6
12,9
42,4
36,0
100,0
• These same statistics (numerical values
describing sample results) can be shown in a
(side-by-side) bar graph.
Percentages Based on Grand Total
25,0
Percentage
20,0
15,0
Male
10,0
Female
5,0
0,0
TV
Radio
Media
NP
Percentages based on row (column) totals:
The entries in a contingency table may also be expressed
as percentages of the row (column) totals by dividing
each row (column) entry by that row’s (column’s) total
and multiplying by 100. The entries in the contingency
table below are expressed as percentages of the column
totals.
Male
Female
Col. Totals
TV Radio
70.9
38.9
29.1
61.1
100.0 100.0
NP Row Totals
64.2
57.6
35.8
42.4
100.0
100.0
Measure of association
Chi-square is a test of independence between
two variables.
Typically, one is interested in knowing whether
an independent variable (x) “has some effect”
on a dependent variable (y).
Said another way, we want to know if y is
independent of x (e.g., if it goes its own way
regardless of what happens to x).
Thus, we might ask, “Is church attendance
independent of the sex of the respondent?”
Fisher’s Exact Test
• just for 2 x 2 tables
• useful where chi-square test is
inappropriate
• gives the exact probability of all tables with
• the same marginal totals
• as or more deviant
than the observed table…
a
b
4
1
c
d
1
5
P = (a+b)!(a+c)!(b+d)!(c+d)! / (N!a!b!c!d!)
P = 5!5!6!6! / 11!4!1!1!5! = 5*6!6! / 11!
P = 5*6!6! / 11! = 5*6! / 11*10*9*8*7
P = 5*6! / 11*10*9*8*7 = 3600 / 55440
P = .065
• The chi-squared test is an extremely simple test of
relationships between categories.
– In chi-squared tests, we ask “Does the distribution of one
variable depend on the categories for the other variable?”
– This sort of question requires only nominal-scaled data
• We are usually interested in more informative tests of
relationships between categories.
– In such tests, we ask “As we increase the level of one variable,
how do we change the level of another?”
– “The more of X, the more of Y”
Chi-square Statistic
k
Oi Ei
i 1
Ei
2
2
•an aggregate measure (i.e., based on the
entire table)
•the greater the deviation from expected
values, the larger (exponentially!) the chisquare statistic…
•one could devise others that would place less
emphasis on large deviations
|o-e|/e
Scenario 1: Consider these data on sex of the
subject and church attendance:
Church Attendance
Sex
Yes No Total
Male
28 12 40
Female
42 18 60
Total:
70 30 100
– Note that:
• 70% of all persons attend church.
• 70% of men attend church.
• 70% of women attend church.
– Thus, we can say that church attendance is
independent of the sex of the respondent because, if
the total number of church goers equals 70%, then,
with independence, we expect 70% of men and 70%
of women to attend church, and they do.
Scenario 2: Now, suppose we observed this
pattern of church attendance:
Church Attendance
Sex
Yes No Total
Male
20 20 40
Female
50 10 60
Total:
70 30 100
50% of the men attend church and 83.3% of the
women attend church.
Observed counts is in red
Expected counts is in White
Sex
Male
Female
Church Attendance
Yes
No
20-28 = -8
50-42 = 8
20-12 = 8
10-18 = -8
in each cell, if we assume independence, we make a mistake equal
to “8” (sometimes positive and sometimes negative).
If we add all of our mistakes, we obtain a sum of zero, which we
know is not true.
So, we will square each mistake to give every number a positive
valence.
Proportionate error is calculated for each cell:
Sex
Male
Female
Church Attendance
Yes No
(-8 )2 / 28 = 2.29
(8)2 / 42 = 1.52
(8)2 / 12 = 5.33
(-8)2 / 18 = 3.56
The total of all proportionate error = 12.70.
This is the chi-square value for this table.
The chi-square value of 12.70 gives us a number that
summarizes our proportionate amount of mistakes for
the whole table
Calculation of chi-square
Status:
low
Ritual arch.: altar
no altar
low
altar
no altar
low
altar
no altar
(7-11.8)2
11.8
intermed. high
7
20
18
22
25
42
16
8
24
intermed. high
11.8
19.8
11.3
13.2
22.2
12.7
25
42
24
intermed. high
2.0
0.0
1.8
0.0
3.7
0.0
1.9
1.7
3.6
43
48
91
43
48
91
3.9
3.5
7.3
(43*24)
91
= 2
.025
Example for Association: Biblical
Literalism and Education
• Is the Bible the word of God or of men? (NES 2000)
• Chi-sq = 105.4 at 4 df p = .000 reject the null hypothesis
Is the Bible the word of God or man? * Education: 3 categories Crosstabulation
Is the Bible the
word of God or
man?
God's word, literal
God's word, not literal
Man's word
Total
Count
% within Education:
3 categories
Count
% within Education:
3 categories
Count
% within Education:
3 categories
Count
% within Education:
3 categories
Education: 3 categories
1. Les s
3. More
than HS
2. HS
than HS
96
230
274
Total
600
56.1%
46.2%
26.2%
35.0%
58
227
583
868
33.9%
45.6%
55.7%
50.6%
17
41
189
247
9.9%
8.2%
18.1%
14.4%
171
498
1046
1715
100.0%
100.0%
100.0%
100.0%
• chi-square is basically a measure of
significance
• it is not a good measure of strength of
association
• can help you decide if a relationship
exists, but not how strong it is
Cramer’s V
• also a measure of strength of association
• an attempt to standardize phi-square
(i.e., control the lack of an upper boundary in
tables larger than 2x2 cells)
• V= 2/m
where m=min(r-1,c-1) ; i.e., the smaller of
rows-1 or columns-1)
• limits: 0-1 for any size table; 1=highest
possible association
Yule’s Q
• for 2x2 tables only
• Q = (ad-bc)/(ad+bc)
a
b
c
d
Collapsing tables
• can often combine columns/rows to
increase expected counts that are too low
– may increase or reduce interpretability
– may create or destroy structure in the table
• no clear guidelines
– avoid simply trying to identify the combination
of cells that produces a “significant” result
obs. counts
8
6
6
3
23
3
1
4
12
20
6
6
5
8
25
2
5
4
3
14
19
18
19
26
82
4.6
4.4
4.6
6.3
20
5.8
5.5
5.8
7.9
25
3.2
3.1
3.2
4.4
14
19
18
19
26
82
8
11
9
11
39
19
18
19
26
82
9.0
8.6
9.0
12.4
39
19
18
19
26
82
exp. counts
5.3
5.0
5.3
7.3
23
obs. counts
11
7
10
15
43
exp. counts
10.0
9.4
10.0
13.6
43
Gamma, Tau-b, Tau-c…
Symmetric Measures
Ordinal by
Ordinal
Kendall's tau-b
Kendall's tau-c
Gamma
N of Valid Cas es
Value
.222
.188
.383
1715
Asymp.
a
Std. Error
.022
.019
.036
b
Approx. T
10.099
10.099
10.099
Approx. Sig.
.000
.000
.000
a. Not as s uming the null hypothes is .
b. Using the as ymptotic s tandard error ass uming the null hypothes is .
So our independent variable, education, reduces our error in
predicting Biblical literalism by either
22.2% (tau-b),
18.8% (tau-c) or
38.3 whopping % (gamma)
And, SPSS reports sign. level, but let me come back to that later.
• Why are there multiple measures of association?
• Statisticians over the years have thought of
varying ways of characterizing what a perfect
relationship is:
tau-b = 1, gamma = 1
tau-b <1, gamma = 1
55
35
40
55
10
25
3
7
30
Either of these might be considered a perfect
relationship, depending on one’s reasoning about
what relationships between variables look like.
The problem: Chi-Squared tests are for nominal
associations. If we use a chi-squared test when there is
an ordinal association, we waste some information.
Chi-Squared tests cannot distinguish the following
patterns:
wag
es
low
like job?
no
maybe
yes
++
-
wag
es
low
like job?
no
maybe
yes
++
-
med
-
++
-
med
-
-
++
high
-
-
++
high
-
++
-
Rule of Thumb
• Gamma tends to overestimate
strength but gives an idea of
upper boundary.
• If table is square use tau-b; if
rectangular, use tau-c.
• Pollock:
τ <.1 is weak; .1<τ<.2 is
moderate; .2<τ<.3 moderately
strong; .3< τ<1 strong.
One Qualitative and One
Quantitative Variable
1. When bivariate data results from one qualitative and one
quantitative variable, the quantitative values are
viewed as separate samples.
2. Each set is identified by levels of the qualitative variable.
3. Each sample is described using summary statistics, and
the results are displayed for side-by-side comparison.
4. Statistics for comparison: measures of central tendency,
measures of variation, 5-number summary.
5. Graphs for comparison: dotplot, boxplot.
Example: A random sample of households from three
different parts of the country was obtained and their
electric bill for June was recorded. The data is given
in the table below.
The part of the country is a qualitative variable with
three levels of response. The electric bill is a
quantitative variable. The electric bills may be
compared with numerical and graphical techniques.
East
23,75
33,65
42,55
37,70
38,85
40,50
31,25
50,60
31,55
21,25
Central
34,38
34,35
39,15
37,12
36,71
34,39
35,12
35,80
37,24
40,01
West
54,54
65,60
59,78
45,12
60,35
61,53
52,79
47,37
59,64
37,40
• Comparison using Box-and-Whisker plots:
70
Electric Bill
60
50
40
30
20
Northeast
Midwes t
West
Connection between two ordinal data
• Example:
Connection between two ordinal data
• Measure: Spearman’s Rank Correlation
Coefficient
6S
i=1
i=n
rs = 1 -
2
di
n3 - n
• Spearman's rank correlation coefficient or Spearman's rho is named
after Charles Spearman
• Used Greek letter ρ (rho) or as rs (non- parametric measure of
statistical dependence between two variables)
• Assesses how well the relationship between two variables can be
described using a monotonic function
• Monotonic is a function (or monotone function) in mathematic that
preserves the given order.
• If there are no repeated data values, a perfect Spearman correlation
of +1 or −1 occurs when each of the variables is a perfect monotone
function of the other
A correlation coefficient is a numerical measure or index of the amount of
association between two sets of scores. It ranges in size from a maximum
of +1.00 through 0.00 to -1.00
The ‘+’ sign indicates a positive correlation (the scores on one variable
increase as the scores on the other variable increase)
The ‘-’ sign indicates a negative correlation (the scores on one variable
increase, the scores on the other variable decrease)
Interpretation
•
The sign of the Spearman correlation indicates the direction of association between X
(the independent variable) and Y (the dependent variable)
•
If Y tends to increase when X increases, the Spearman correlation coefficient is
positive
•
If Y tends to decrease when X increases, the Spearman correlation coefficient is
negative
•
A Spearman correlation of zero indicates that there is no tendency for Y to either
increase or decrease when X increases
Alternative name for the Spearman rank correlation is the "grade correlation” the
"rank" of an observation is replaced by the "grade"
•
•
When X and Y are perfectly monotonically related, the Spearman correlation
coefficient becomes 1
•
A perfect monotone increasing relationship implies that for any two pairs of data
values Xi, Yi and Xj, Yj, that Xi − Xj and Yi − Yj always have the same sign
Example # 1
Calculate the correlation between the
IQ of a person with the number of
hours spent in the class per week
Find the value of the term d²i:
1.
Sort the data by the first
column (Xi). Create a new column xi
and assign it the ranked values
1,2,3,...n.
2.
Sort the data by the second
column (Yi). Create a fourth column yi
and similarly assign it the ranked
values 1,2,3,...n.
3.
Create a fifth column di to
hold the differences between the two
rank columns (xi and yi).
IQ, Xi
Hours of class per
week, Yi
106
7
86
0
100
27
101
50
99
28
103
29
97
20
113
12
112
6
110
17
4. Create one final column to hold the value of
column di squared.
IQ
(Xi )
Hours of class per week
(Yi)
rank xi
rank yi
di
d²i
86
0
1
1
0
0
97
20
2
6
-4
16
99
28
3
8
-5
25
100
27
4
7
-3
9
101
50
5
10
-5
25
103
29
6
9
-3
9
106
7
7
3
4
16
110
17
8
5
3
9
112
6
9
2
7
49
113
12
10
4
6
36
Example 1- Result
• With d²i found, we can add them to find d²i = 194
• The value of n is 10, so;
ρ=
1- 6 x 194
10(10² - 1)
ρ=
−0.18
• The low value shows that the correlation between IQ and
hours spent in the class is very low
RECOMMENDED RESOURCES
• The books below explain statistics simply,
without excessive mathematical or logical
language.
– David S. Moore: The basic practice of statistics. W. H.
Freeman Publishers, 2003
– Geoffrey Norman and David Steiner: PDQ Statistics.
3rd Edition. BC Decker, 2003
– David Bowers, Allan House, David Owens:
Understanding Clinical Papers (2nd Edition). Wiley,
2006
– Douglas Altman et al.: Statistics with Confidence.
2nd Edition. BMJ Books, 2000