Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Lecture 3 - Standard Scores, Probability, and the Normal
Distribution
Howell Chapter 6, 7
Standard Scores
Standard Score: A way of representing performance on a test or some other
measure so that persons familiar with the standard score know immediately how
well the person did relative to others taking the same test.
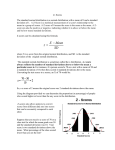
1. Percentile based Standard Scores
The Percentile Rank of a score: Percentage of Scores in a reference group less
than or equal to a score value.
ID
RSE Percentile
No. of scores <= X i
PR X = 100*
i
N
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Typical Values
100
Largest possible percentile rank
50
Middle-of-the-road percentile rank
(i.e., the median)
Lowest possible percentile rank.
0
Pros
4.90
5.50
5.30
6.90
4.60
6.40
5.30
5.70
6.20
5.20
6.30
4.50
3.70
1.90
5.80
6.10
4.60
6.40
6.70
3.80
1. Useful for everyone because it’s easy to understand.
(List of cases on the right is of the Rosenberg SelfEsteem scale. Raw scores are on a 1-7 scale.
I claim that the Percentiles are easier for people unfamiliar with the Rosenberg
to understand.)
19.90
38.80
31.10
97.60
14.10
80.60
31.10
51.90
70.90
27.70
75.20
12.10
2.90
.50
57.80
68.90
14.10
80.60
91.30
3.40
2. Doesn’t depend on distribution shape for precise interpretation (as do Zs)
Cons
Unequal percentile differences
1. No statistical heritage, no roots.
2. Not completely linearly related to the original
score values.
Equal score differences don’t have equal percentile
differences.
Percentile
This creates a problem when dealing with extreme
scores. When dealing with scores near the middle of
the distribution, the relationship is close enough to
being linear to not be a problem in many cases.
Standard Scores / Normal Distribution - 1
Raw score
Equal score
differences
4/29/2017
2. Standard Scores based on a linear transformation of the difference between X
and the mean.
Linear Transformation:
New score = Multiplicative constant • Old score + Additive constant
a. The Z Score (The Godfather of standard scores)
X – Mean
1
Z = ----------------------- = (------)*X – Mean/SD
SD
SD
Interpretation: Z is number of SDs X is above or below the mean.
Z = 1 means X is 1 SD above mean.
Z = -3 means X is 3 SDs below the mean.
General rule of thumb: Most Z scores will be between -3 and +3.
2/3 of Zs will be between -1 and +1;
95% of Zs will be between -2 and +2.
Mean of the whole collection of Zs: Will always equal 0.
SD of the whole collection of Zs: Will always equal 1.
Note: Must compute from
ALL the Zs.
b. The T-score – the Education standard score
Ti = 10 * Zi + 50, rounded to nearest whole number.
Mean of Ts is always 50.
SD of Ts is always 10.
Note: Most tests that are reported as T-scores have special
formulas that take you directly to the T, without having to
go through Z.
c. The SAT score
SATi = 100 * Zi + 500, rounded to nearest whole number.
Mean = 500 and SD = 100.
GRE scores have been scored in this fashion. That changed in Fall 2012.
Standard Scores / Normal Distribution - 2
4/29/2017
Comparison of Scales of the three types:
3 SD's below mean
3 SD's above mean
2 SD's below mean
2 SD's above mean
1 SD above mean
1 SD below mean
The mean
Z
-3
-2
-1
0
1
2
3
T
20
30
40
50
60
70
80
SAT
200
300
400
500
600
700
800
Standard Scores / Normal Distribution - 3
4/29/2017
Effects of Linear Transformations of the original scores on measures of central
tendency and variability
1. Location shift: A constant is added to each score in the collection.
New X = Old X + A
New measure of central tendency = Old measure + A
New measure of variability = Old measure (no change)
New measures of shape are = old measures of shape.
Distributions are identical with the exception of the shift in location.
Standard Scores / Normal Distribution - 4
4/29/2017
2. Scale change: Multiplying or dividing each score by a constant.
New X = B*Old X.
New measure of central tendency = B*Old measure
New Range = B*Old range
New Interquartile range = B*Old Interquartile range
New SD = B*Old SD
But . . . New Variance = B2 * Old Variance
The bottom distribution is of scores multiplied by 2. It is twice as “wide” as measured by
the standard deviation. It’s location has also increased by a factor of 2.
So multiplying each score by a constant affects both the location and the variability
Standard Scores / Normal Distribution - 5
4/29/2017
Probability
A. Definition of probability
The probability of an event is a number between 0 and 1 inclusive.
This number represents the likelihood of occurrence of the event.
B. Examples of Events
The event "A randomly selected person is a male."
The event "A randomly selected IQ score is larger than 130."
The event, “An experimenter will incorrectly reject the null hypothesis.”
The event "I change my name to Fred tomorrow."
C. Why do we want probabilities?
A probability is a formalized numerical way of looking into the future and making
decisions.
When our oldest son was 4, we found that he had a tumor on his neck.
The doctors, based on the available evidence, gave us the probability of his
survival if we did not operate and the probability of his survival if we did
operate. Outcomes of many medical conditions are expressed formally in
terms of probabilities.
The consequences of a pre-emptive strike on Iran’s nuclear facilities have
been expressed as probabilities – the probability of a failure, the probability of
a Mideast uprising, the probability of Iran backing down in its attempts to
create a nuclear arsenal, the probability of a strike strengthening the Iran
government.
Probabilities are used to determine costs.
Insurance companies have derived quantitative formulas relating the
probability of persons of each age having a car accident to rates based on
those probability estimates – the higher the probability, the higher the rate.
Probabilities are used to evaluate the results of experiments
1. An experiment is conducted comparing two pain relievers and the outcome
is recorded.
2. The probability of that particular outcome is computed assuming that the
pain relievers are equal.
3a. If that probability is large, then the researcher concludes that the pain
relievers are equal.
3b. But if the probability is small, then the researcher concludes that they’re
not equal.
Standard Scores / Normal Distribution - 6
4/29/2017
D. Computing or determining the probability of an event.
1. Subjective determination. For example, P(Light turning Red before you get to
it.)
We make subjective determinations all the time.
2. The Relative Frequency method, from the proportion of previous occurrences,
Number of previous occurrences
Probability estimate = --------------------------------------------Number of previous opportunities to occur
Applications of this method: Actuarial tables created by insurance companies
Problems with this method
Depends on the future mirroring the past.
Not applicable to events for which we have no history (AIDS)
Accurate counts may not be available (AIDS again)
3. The Universe of Elementary Events method, from a universe of elementary
events
Let U = A collection of equally likely elementary (indivisible) events.
Let A = an event defined as a subset of U.
Number of elem. events in A
Probability of A, P(A) = ------------------------------------Number of elem. events in U
Example
Let U = {1, 2, 3, 4, 5, 6 } the possible faces of a single die.
Suppose A = {1, 3, 5}, then P(A) = 3 / 6 = 0.5
Problems with the Universe of Elementary Events method:
There aren't many real world situations to which it applies
Applications: Games of chance
Standard Scores / Normal Distribution - 7
4/29/2017
Two Important Events defined as combinations of other events
Start here on 9/13/16.
1. The intersection or joint-occurrence event, “A and also B”
An outcome is in the intersection of A and B if it represents the occurrence of both A
and B.
This event is called the Intersection of A and B. The name can best be appreciated by
considering A and B as two streets which cross.
A
A and also B
B
A = 1st person past the door is a male.
B = 1st person past the door has blue eyes.
The intersection is “1st person past the door is a male with blue eyes.”
Example:
2. The union event, “Either A or B or Both”.
This event is called the Union of A and B. Think of union as in the union of
matrimony. After the marriage, either the husband (A) or the wife (B) or both can
represent the family.
A
Either A or B or both
B
Example:
A = 1st person past the door is a male.
B = 1st person past the door has blue eyes
Union is “1st person past the door is either male or blue-eyed or both.”
Standard Scores / Normal Distribution - 8
4/29/2017
Two important event relationships.
1. Mutually exclusive events – one or the other but not both.
Two events, A and B, are mutually exclusive if the occurrence of either precludes the
occurrence of the other.
They’re mutually exclusive if an outcome cannot simultaneously be both.
Examples.
A: 1st person past the door is taller than 6’.
B: 1st person past the door is shorter than 5’.
The 1st person cannot be both taller than 6’ and shorter than 5’, so A and B are mutually
exclusive.
A: The IQ of a randomly selected person is greater than 130.
B: The IQ of the same randomly selected person is less than 70.
A: The results of an experiment result in rejection of the null hypothesis.
B: The results of the same experiment result in failure to reject the same null
hypothesis.
A special type of mutually exclusive event: Complement
A: Anything
~A: Anything but A (may also be written as A’ or –A or Ac )
Example:
A = The first card drawn from a deck is the 10 of clubs
~A = The first card drawn from a deck is not be a 10 of clubs
Standard Scores / Normal Distribution - 9
4/29/2017
2. Independent events.
Two events, A and B, are independent if the occurrence of either has no effect on the
probability of occurrence of the other.
AB can occur,
A and ~B can occur,
~A and B can occur, ~A and ~B can occur
Moreover, the occurrence of A or ~A will not affect the probability of occurrence of B.
And the occurrence of B or ~B will not affect the probability of occurrence of A.
Examples.
A: It will rain in Tokyo tomorrow.
B: The Tennessee Titans will win on Sunday.
A: Experimenter A finds a significant difference between an Experimental and Control
group.
B: Experimenter B working in a different laboratory with no connection or
communication with Experimenter A finds a significant difference between a
similar Experimental and Control group.
Standard Scores / Normal Distribution - 10
4/29/2017
Two Laws of Probability
1. The Multiplicative Law - Probability of “A and also B”.
In general, P(A and also B) = P(A) * P(B|A) or P(B) * P(A|B)
Where P(B|A) is called the conditional probability of B given A, read as Probability of B
given A.
If this were a course on probability, we’d spend a week or so studying conditional
probability.
We won’t pursue this general case here, however.
Two special cases:
A. A and B are mutually exclusive
If A and B are mutually exclusive, P(A and also B) = 0 .
B. A and B are independent.
If A and B are independent, P(A and also B) = P(A) * P(B) .
This is called the multiplicative law of probability.
2. The Additive Law - Probability of “Either A or B or Both”
In general P(Either A or B or Both) = P(A) + P(B) – P(A and also B)
Two special cases (same two as above)
A. A and B are mutually exclusive
If A and B are mutually exclusive, P(Either A or B or Both) = P(A) + P(B).
This is called the additive law of probability
Application to complements: P(Either A or ~A) = 1
So, P(~A) = 1 – P(A). The probability of the complement of an event is 1 minus
probability of the event.
B. A and B are independent
If A and B are independent, P(Either A or B or Both) = P(A) + P(B) – P(A)*P(B).
Standard Scores / Normal Distribution - 11
4/29/2017
“One or More” problems: An application of the above laws
A researcher conducts research intent on demonstrating the existence of telekinesis – the
ability to move things through mind power alone. The probability of rejecting the null
(incorrectly, since telekinesis does not exist) is .05. So he could, incorrectly, conclude
that telekinesis exists. But there is only a 1 in 20 chance of his project reaching that
incorrect conclusion.
50 other misguided researchers conduct the same research. For each (since telekinesis
still does not exist) the probability is .05 that each will reject (incorrectly) the null
hypothesis is .05.
What’s the probability that one or more of the 50 researchers will (incorrectly) reject
the null hypothesis and incorrectly conclude that telekinesis exists?
This problem has the following form:
What’s the probability of one or more occurrences of a particular event?
Solving a “One or More” problem by computing probabilities directly is difficult:
Suppose there are 3 events: A, B, and C (A is the nonoccurrence of A.)
“One or More” is a collection of events, specifically . . .
ABC ABC ABC ABC ABC ABC ABC .
7 probabilities would have to be computed.
But, not that the event, Not “One or More” is ABC.
ABC is the complement of “One or More”.
Hmm. Why not compute P(ABC) and subtract it from 1.
If the events are independent, the problem can be solved by
1) Realizing the “None” is the complement of “One or more”
Probability of one or more = 1 – Probability of none
2) Since they’re independent,
Probability of none = P(Not 1st) * P(Not 2nd) * P(Not 3rd) * etc etc etc
For the above example, P(ABC) = P(A) * P(B) * P(C).
So, if multiple, identical events are independent,
Probability of One or more = 1 – (P(Not Each event))K where K is the no. of
events.
Standard Scores / Normal Distribution - 12
4/29/2017
Applied to the problem above . .
A researcher conducts research that intent in demonstrating the existence of telekinesis.
The probability of rejecting the null (incorrectly, since telekinesis does not exist) is .05.
49 other misguided researchers conduct the same research. For each (since telekinesis
still does not exist) the probability is .05 that each will reject (incorrectly) the null
hypothesis is .05.
What’s the probability that one or more of the researchers will (incorrectly) reject the null
hypothesis?
P(One or more incorrect rejections) = 1 - .9550 = 1 - .077 = .92
(I used Excel to evaluate .9550.
So, if enough misguided researchers study the same problem such as the above, it’s very
very likely that one or more of them will incorrectly conclude that telekinesis exists.
So, any time someone claims that they have “proof” of some psychic event, consider how
many experiments might have been conducted before that “proof” was obtained.
Standard Scores / Normal Distribution - 13
4/29/2017
Random Variable
A variable whose values are determined by a random process.
Its values are not predictable.
So we can't know which value a random variable will have. But in many instances, we
can know the probability of occurrence of each value.
Random variables are what statisticians study.
Probability Distribution
Q: If we can’t know what the next value of a random variable is, what can we know?
A: We can know the probability that the variable will take on a specific value.
Probability Distribution: A statement, usually in the form of a formula or table,
which gives the probability of occurrence of each value of a random variable.
Standard Scores / Normal Distribution - 14
4/29/2017
Famous probability distributions
The binomial distribution . . .
Suppose a bag of N coins is spilled. Probability of X Hs when the bag is spilled.
Possible outcomes
X: No. of H's
N
N-1
.
.
.
3
2
1
0
Probability
N!
P(X) = -------------* PX(1-P)N-X
X!(N-X)!
Where
N = No. coins spilled.
P = Probability of a Head for with each coin.
! = Factorial operator. K! = K*(K-1)*(K-2) . . . 2*1
Use “ExampleProbabilityDistributions.sps from T\P510511 folder” to illustrate.
*** SPSS Syntax to simulate spills of 100 bags of 10 coins in each bag.
input program.
loop #i=1 to 100.
compute id = $casenum.
end case.
end loop.
end file.
end input program.
execute.
print formats id (f3.0).
COMPUTE bino = RV.BINOM(10,.5) .
XGRAPH CHART=[POINT] BY bino[s] /DISPLAY DOT=ASYMMETRIC.
Standard Scores / Normal Distribution - 15
4/29/2017
Uniform Probability Distribution
Probability
Min
X1
Max
X2
4/0
3
1
P(X between X1 and X2= (X2-X1)/(Max - Min)
2
Example - Playing spin-the-bottle
*** SPSS syntax to generate 1000 random values from a uniform distribution.
input program.
loop #i=1 to 1000.
compute id = $casenum.
end case.
end loop.
end file.
end input program.
execute.
print formats id (f3.0).
compute uni = rv.uniform(0,4).
XGRAPH CHART=[POINT] BY uni[s]/DISPLAY DOT=ASYMMETRIC.
fre var=uni /format=notable /sta=kur /histogram normal.
Statistics
uni
N
Valid
Missing
Kurtosis
Standard Scores / Normal Distribution - 16
1000
0
-1.174
4/29/2017
The Normal Distribution
1
P(X between X1 and X2) = Integral of ------- e
2
-
-(X-)2
----------22
+
*** SPSS syntax to generate 10,000 values from a normally distributed distribution.
input program.
loop #i=1 to 10000.
compute id = $casenum.
end case.
end loop.
end file.
end input program.
execute.
print formats id (f3.0).
compute normi = rv.normal(0,1).
XGRAPH CHART=[POINT] BY normi[s]/DISPLAY DOT=ASYMMETRIC.
fre var=normi /sta=kur /format=notable /histogram normal.
Statistics
normi
N
Valid
Missing
Kurtosis
Standard Scores / Normal Distribution - 17
10000
0
-.022
4/29/2017
Normal Distribution – up close and personal
The most important probability distribution.
Formula, again
P(X) =
1
------------ *
σ SQRT(2π)
-(X-µ)2
-----2σ2
e
Why so ubiquitous?
Quantities which are the accumulations of more elementary, typically
binary, entities tend to follow the normal distribution.
Simplest example: Take a single coin. Flip it and consider the possible proportion of
Heads.
The possibilities are 0 or 1.
Graphically: ---------------------------------------------------------0
1
Take a bag of 3 coins. Spill it and count the possible proportions of Heads.
Graphically: ---------------------------------------------------------0
.5
1
Take a bag of 4 coins. Spill it, and count the possible proportions of Heads.
Graphically: ---------------------------------------------------------0
.25
.5
.75
1
Take a bag of 10 coins. Spill it and count the possible proportions of Heads . . .
Graphically: ---------------------------------------------------------0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Note that the possible values of Proportion of Heads are getting closer and closer to each
other.
Standard Scores / Normal Distribution - 18
4/29/2017
There will be two consequences of this experiment . . .
1. The differences between the possible values will become small relative to the range.
That is, the larger the number of coins in the bag, the more similar adjacent values will be
to each other. If the number of coins was TREMENDOUS, the possible values of
Proportion of Heads would be nearly continuous.
2. Interior outcomes will occur more frequently than others.
If you spill a bag of 2 coins, there is 1 way to get 0 proportion of Heads, 2 ways to
get .5 proportion of Heads, and 1 way to get a proportion of Heads = 1. The distribution
has a mode at proportion = .5.
O
O
O
O
Graphically: ---------------------------------------------------------0
.5
1
If you spill a bag of 4 coins there is
1 way to get proportion = 0;
4 ways to get proportion = .25
6 ways to get proportion = .50
4 ways to get proportion = .75
1 way to get proportion = 1.00
O
O
O
O
O
O
O
O
O
O
O
O
O
O
O
O
Graphically: ---------------------------------------------------------0
.25
.5
.75
1
As the number of coins in the bag increases, the distribution of Percent of Heads
1) has more and more possible values, closer and closer together, and
2) becomes more “nicely” unimodal.
So even though the originating event – flip of a coin – is a categorical, outcome, the
proportion of a bunch of those events yields a quantity that becomes more like a
continuous variable as the number of possible events increases.
And, low and behold, the mathematical description of the shape of the distribution
becomes more and more like the mathematical description of the Normal Distribution.
Standard Scores / Normal Distribution - 19
4/29/2017
So what? Are there worldly outcomes that depend on binary events like this?
Yes: genes.
Individual genes turned on or off determine whether the vast majority of our
characteristics.
While a few characteristics may be determined by just 1 gene, most characteristics are the
result of the accumulations of many, many binary gene states. We have 3,000,000,000 +
genes.
Siddhartha, M. (2016). The Gene: An Intimate History. New York: Scribner.
On page 103, “By 1910, the greatest minds in biology had accepted that discrete particles
of information carried on chromosomes were the carriers of hereditary information. But
everything visible about the biological world suggested near-perfect continuity:
nineteenth-century biometricians . . . had demonstrated that human traits, such as height,
weight, and even intelligence were distributed in smooth, continuous, bell-shaped
curves.”
The resolution of this issue was solved by R. A. Fisher, whose work we will encounter
again. See the excerpt from page 103 below.
Fisher showed how individual, dichotomous genes, could result in nearly continuous
characteristics, if those characteristics were determined not by individual genes acting
alone but by groups of genes.
Standard Scores / Normal Distribution - 20
4/29/2017
Standard Scores / Normal Distribution - 21
4/29/2017
Samples vs. Populations
Population: A complete set of observations or measurements about which conclusions
are to be drawn.
Sample: A subset or part of a population.
Our goal: Samples --> Populations
Not necessarily random
Statistics vs. Parameters
Parameter: A summary characteristic of a population.
Summary of Central tendency, variability, shape, correlation
E.g., Population mean, SD, Median, Proportion Voting for Obamacare, Population
correlation between Systolic & Diastolic BP
Statistic: A summary characteristic of a sample.
Our goal: Statistic --> Parameter
Sample mean, SD, median, correlation coefficient
Standard Scores / Normal Distribution - 22
4/29/2017
Sampling Distributions – Distributions of sample statistics
Consider a population.
Now consider taking a sample of size 4 from that population.
Suppose the mean of that sample was computed.
Now repeat the above steps thousands of times.
The result would be a population of sample means.
A few of the
sample means.
Values of sample mean
The frequency distribution of the sample means is called the Sampling Distribution of
Means.
In general, the distribution of values of any sample statistic is called the Sampling
Distribution of that statistic, e.g., the Sampling Distribution of the standard deviation, of
the median, etc.
Standard Scores / Normal Distribution - 23
4/29/2017
Three theoretical facts and 1 practical fact about the
Sampling Distribution of sample means . . .
Theoretical facts
1. The mean of the population of sample means will be the same as the mean of the
population from which the samples were taken. The mean of the means is the mean.
µX-Bar = µX
Implication: Sample mean is an unbiased estimate of the population mean.
2. The standard deviation of the population of sample means will be equal to original
population's sd divided by the square root of N, the size of each sample.
σX-Bar = σX/sqrt(N)
Implication: Sample mean will be closer to population mean, on the average, as sample
size gets larger.
3. The shape of the distribution of sample means will be the normal distribution if the
original distribution is normal or approach the normal as N gets larger in all other
cases. This fact is called the Central Limit Theorem. It is the foundation upon which
most of modern day statistics rests.
Why do we care about #3? We care because we’ll need to compute probabilities
associated with sample means when doing inferential statistics. To compute those
probabilities, we need a probability distribution.
Practical fact
4. The distribution of Z's computed from each sample, using the formula
X-bar -
Z = -------------------- / N
will be or approach (as sample size gets large) the Standard Normal Distribution with
mean = 0 and SD = 1.
This ties the beginning of this lecture (Z-scores) to the rest of it (the Normal
Distribution).
Standard Scores / Normal Distribution - 24
4/29/2017