Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
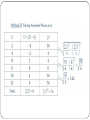
RESEARCH METHODOLOGY RESULT AND ANALYSIS (part 1) Introduction DATA ANALYSIS is a process of inspecting, cleaning, transforming, and modeling data with the goal of highlighting useful information, suggesting conclusions, and supporting decision making. Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, in different business, science, and social science domains. Type of data Quantitative data. data is a number Often this is a continuous decimal number to a specified number of significant digits Sometimes it is a whole counting number Categorical data. data one of several categories Qualitative data. data is a pass/fail or the presence or lack of a characteristic Quantitative data Quantitative data is data measured or identified on a numerical scale. Numerical data can be analyzed using statistical methods, and results can be displayed using tables, charts, histograms and graphs. Examples of quantitative data would be: Counts 'there are 643 dots on the ceiling' 'there are 25 pieces of bubble gum' 'there are 8 planets in the solar system' Measurements 'the length of this table is 1.892m' 'the temperature at 12:00 p.m. was 18.9° Celsius' 'the average flow yesterday in this river was 25 mph (miles per hour)' Categorical data Categorical data is that part of an observed dataset that consists of categorical variables, or for data that has been converted into that form, for example as grouped data. Example The idea of grouped data can be illustrated by considering the following raw dataset: Table 1: Time taken (in seconds) by a group of students to answer a simple math question 20 26 16 14 25 8 21 15 24 19 17 21 33 31 11 18 13 11 34 17 The above data can be organized into a frequency distribution (or a grouped data) in several ways. One method is to use intervals as a basis. The smallest value in the above data is 8 and the largest is 34. Table 2: Frequency distribution of the time taken (in seconds) by the group of students to answer a simple math question Time taken (in seconds) 5 and above, below 10 10 and above, below 15 15 and above, below 20 20 and above, below 25 25 and above, below 30 30 and above, below 35 Frequency 1 4 6 4 2 3 Another method of grouping the data is to use some qualitative characteristics instead of numerical intervals. Table 3: Frequency distribution of the three types of students Frequency Smart 5 Normal 10 Below normal 5 Qualitative data Qualitative data describe items in terms of some quality or categorization that in some cases may be 'informal‘ In regression analysis, dummy variables are a type of qualitative data. For example, if various features are observed about each of various human subjects, one such feature might be gender, in which case a dummy variable can be constructed that equals 0 if the subject is male and equals 1 if the subject is female. Then this dummy variable can be used as an independent variable (explanatory variable) in an ordinary least squares regression. Dummy variables can also be used as dependent variables, in which case the probit or logistic regression technique would typically be used. Quality of data The quality of the data should be checked as early as possible. Data quality can be assessed in several ways, using different types of analyses: frequency counts, descriptive statistics (mean, standard deviation, median), normality (skewness, kurtosis, frequency histograms, normal probability plots), associations (correlations, scatter plots). Data analysis tools Commonly used approaches or tools Statistics Models Standards Statistic Statistics is the study of the collection, organization, analysis, and interpretation of data Modelling Data modeling is a method used to define and analyze data requirements needed to support the business processes of an organization. Standard American Measurement Standard (AMS) Deutsches Institut für Normung (DIN; in English, the German Institute for Standardization) International Standard Organization (ISO) Australia Standards Institute for Reference Materials and Measurements (EU) Statistical Analysis Two main areas of statistics Descriptive statistics. summarize the population data by describing what was observed in the sample numerically or graphically. Numerical descriptors include mean and standard deviation for continuous data types (like heights or weights), while frequency and percentage are more useful in terms of describing categorical data (like race). Involved : data collection, organization, summation Inferential statistics. uses patterns in the sample data to draw inferences about the population represented, accounting for randomness. These inferences may take the form of: answering yes/no questions about the data (hypothesis testing), estimating numerical characteristics of the data (estimation), describing associations within the data (correlation) and modeling relationships within the data (for example, using regression analysis). generalizing from samples to populations. Involved: performing hypothesis testing, determining relationships among variables, and making predictions DATA DESCRIPTION Three aspects: 1. Measures of Central Tendency Mean Median Mode Midrange Definition sum of values divided by total number of value Middle point in the data set Most frequent data value (Lowest value plus highest value)/2 Symbol , x MD None MR 2. Measures of Variation. Sometime the mean is not good enough to describe a data set as in the following example. Example: A testing lab wishes to test two experimental brands of outdoor paint to see how long each would last before fading. Different chemical agents are added in each group and only six cans are involved. These two groups constitute two small populations. The results (in months) follow. Brand A 10 60 50 30 40 20 Mean = 35 Brand B 35 45 30 35 40 25 Mean 35 Note that Brand A and B gave similar means = 35. Thus one might conclude that both brand of paint last equally well. But a different conclusion might be withdrawn when the data set are examined graphically. The range for Brand A: 60-10 = 50 month for Brand B: 45-25 = 20 month Measures indicating the degree of spread/variation Range Definition Symbols distance between highest and lowest value R Variance average of the squares of the distance each value id from the mean Standard Deviation Square root of the variance 2, s2 , s 3. Measure of Position Definition Symbol Standard score Number of standard z or z score deviation a data value is above or below the mean Percentile Position in hundredths a Pn data value is in the distribution Decile Position in tenths a data Dn values is in the distribution Quartile Position in fourths a data Qn value is in the distribution Mode The mode is the most repeated value in a distribution. It is represented by Mo. It is possible to find the mode for categorical and quantitative variables. Median The median is the score of the scale that separates the upper half of the distribution from the lower, that is to say, it divides the series of data into two equal parts. The median is denoted by Me. The median can only be found for quantitative variables. Calculation of the Median for Grouped Data Mean In statistics, mean has two related meanings: the arithmetic mean (and is distinguished from the geometric mean or harmonic mean). the expected value of a random variable, which is also called the population mean. The arithmetic mean is the "standard" average, often simply called the "mean". For example, the arithmetic mean of six values: 34, 27, 45, 55, 22, 34 is Geometric mean (GM) The geometric mean is an average that is useful for sets of positive numbers that are interpreted according to their product and not their sum (as is the case with the arithmetic mean) e.g. rates of growth. For example, the geometric mean of six values: 34, 27, 45, 55, 22, 34 is: Harmonic mean (HM) The harmonic mean is an average which is useful for sets of numbers which are defined in relation to some unit, for example speed (distance per unit of time). For example, the harmonic mean of the six values: 34, 27, 45, 55, 22, and 34 is Population mean The mean of a population has an expected value of μ, known as the population mean. The sample mean makes a good estimator of the population mean, as its expected value is the same as the population mean. The sample mean of a population is a random variable, not a constant, and consequently it will have its own distribution. For a random sample of n observations from a normally distributed population, the sample mean distribution is Standard deviation It shows how much variation or "dispersion" there is from the average (mean, or expected value). Consider a population consisting of the following eight values: These eight data points have the mean (average) of 5: To calculate the population standard deviation, first compute the difference of each data point from the mean, and square the result of each: Next compute the average of these values, and take the square root: Example: Calculate the standard deviation for the following sample data using all methods: 2, 4, 8, 6, 10, and 12. Solution: Percentile percentile (or centile) is the value of a variable below which a certain percent of observations fall. One definition of percentile, often given in texts, is that the P-th percentile ( ) of N ordered values (arranged from least to greatest) is obtained by first calculating the (ordinal) rank rounding the result to the nearest integer, and then taking the value that corresponds to that rank. For example, by this definition, given the numbers 15, 20, 35, 40, 50 the rank of the 30th percentile would be . Thus the 30th percentile is 20, the second number in the sorted list. The 40th percentile would have rank , Percentile Quartiles quartiles of a set of values are the three points that divide the data set into four equal groups, each representing a fourth of the population being sampled. 1. first quartile (designated Q1) = lower quartile = cuts off lowest 25% of data = 25th percentile 2. second quartile (designated Q2) = median = cuts data set in half = 50th percentile 3. third quartile (designated Q3) = upper quartile = cuts off highest 25% of data, or lowest 75% = 75th percentile Exploratory data analysis exploratory data analysis (EDA) is an approach to analysing data set to summarize their main characteristics in easy-to-understand form, often with visual graphs, without using a statistical model or having formulated a hypothesis. To discover various aspects of data. In EDA data are are organised to facilitate further analysis Common methods used 1. Stem and leaf plot 2. Box Plots Stem-and-leaf display A stemplot (or stem-and-leaf display), in statistic, is a device for presenting quantitative data in a grapical format, to assist in visualizing the shape of a distribution. 44 46 47 49 63 64 66 68 68 72 72 75 76 81 84 88 106 Box plot box plot or boxplot (also known as a box-and-whisker diagram or plot) is a convenient way of graphically depicting groups of numerical data through their five-number summaries: the smallest observation (sample minimum), lower quartile (Q1), median (Q2), upper quartile (Q3), and largest observation (sample maximum). Information Obtained from a Box Plot a. If the median is near the center of the box, the distribution is approximately symmetric b. If the median falls to the left of the center of the box, the distribution is positively skewed c. If the median falls to the right of the center, the distribution is negatively skewed d. If the lines are about the same length, the distribution is approximately symmetric e. If the right line is larger than the left line, the distribution is positively skewed f. If the left line is larger than the right line, the distribution is negatively skewed GRAPHICAL PRESENTATION The most commonly used graphs bar chart or bar graph is a chart with rectangular bars with lengths proportional to the values that they represent. The bars can be plotted vertically or horizontally. Histogram histogram is a graphical representation showing a visual impression of the distribution of data. Histogram A histogram is a graphic representation of a variable in the shape of bars (rectangles). They are used for continuous or discrete variables with a large quantity of data that is grouped into classes. The base width of the bars (rectangles) are proportional to the class widths and the height is the absolute frequency of each interval. The surface area of every bar is proportional to the frequency of the represented values. Run chart run-sequence plot is a graph that displays observed data in a time sequence. Pie chart A pie chart can be used to represent all types of variables, but is more commonly used for categorical variables. The data is represented in a circle and the angle of each circular sector is proportional to the corresponding absolute frequency. The pie chart can be constructed with the help of a protractor. Radar chart radar chart is a graphical method of displaying multivariate data in the form of a two-dimensional chart of three or more quantitative variables represented on axes starting from the same point. Scatter plot scatter plot or scattergraph is a type of mathematical diagram using Cartesian coordinates to display values for two variables for a set of data. Problem Given the data set 4 , 10 , 7 , 7 , 6 , 9 , 3 , 8 , 9 Find a) the mode, b) the median, c) the mean (Arithmetic, Geometric and Harmonic) d) the sample standard deviation. e) If we replace the data value 6 in the data set above by 24, will the standard deviation increase, decrease or stay the same? Solution The given data set has 2 modes: 7 and 9 order data : 3 , 4 , 6 , 7 , 7 , 8 , 9 , 9 , 10 : median = 7 (mean) : m = (3+4+6+7+7+8+9+9+10) / 9 = 7 Problem Given the data set 62 , 65 , 68 , 70 , 72 , 74 , 76 , 78 , 80 , 82 , 96 , 101, find a) the median, b) the first quartile, c) the third quartile, c) the interquartile range (IQR). Solution median = 75 first quartile = 69 third quartile = 81 interquartile range = 81 - 69 = 12