Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
9/19/2013
Knowledge Discovery and Data
Mining
Unit # 2
Sajjad Haider
Fall 2013
1
Structured vs. Non-Structured Data
• Most business databases contain structured data
consisting of well-defined fields with numeric or alphanumeric values.
• Examples of semi-structured data are electronic images
of business documents, medical reports, executive
summaries, etc. The majority of web documents also
fall in this category.
• An example of unstructured data is a video recorded by
a surveillance camera in a departmental store. This
form of data generally requires extensive processing to
extract and structure the information contained in it.
Sajjad Haider
Fall 2013
2
1
9/19/2013
Structured vs. Non-Structured Data
(Cont’d)
• Structured data is often referred to as
traditional data, while the semi-structured
and unstructured data are lumped together as
non-traditional data.
• Most of the current data mining methods and
commercial tools are applied to traditional
data.
Sajjad Haider
Fall 2013
3
SQL vs. Data Mining
• SQL (Structured Query Language) is a standard
relational database language that is good for queries
that impose some kind of constraints on data in the
database in order to extract an answer.
• In contrast, data mining methods are good for queries
that are exploratory in nature, trying to extract hidden,
not so obvious information.
• SQL is useful when we know exactly what we are
looking for and we can describe it formally.
• We use data mining methods when we know only
vaguely what we are looking for.
Sajjad Haider
Fall 2013
4
2
9/19/2013
OLAP vs. Data Mining
• OLAP tools make it very easy to look at dimensional
data from any angle or to slice-and-dice it.
• The derivation of answers from data in OLAP is
analogous to calculations in a spreadsheet; because
they use simple and given-in-advance calculations.
• OLAP tools do not learn from data, not do they create
new knowledge.
• They are usually special-purpose visualization tools
that can help end-users draw their own conclusions
and decisions, based on graphically condensed data.
Sajjad Haider
Fall 2013
5
Statistics vs. Machine Learning
• Data mining has its origins in various disciplines, of
which the two most important are statistics and
machine learning.
• Statistics has its roots in mathematics, and therefore,
there has been an emphasis on mathematical rigor, a
desire to establish that something is sensible on
theoretical grounds before testing it in practice.
• In contrast, the machine learning community has its
origin very much in computer practice. This has led to a
practical orientation, a willingness to test something
out to see how well it performs, without waiting for a
formal proof of effectiveness.
Sajjad Haider
Fall 2013
6
3
9/19/2013
Statistics vs. Machine Learning
(Cont’d)
• Modern statistics is entirely driven by the
notion of a model. This is a postulated
structure, or an approximation to a structure,
which could have led to the data.
• In place of the statistical emphasis on models,
machine learning tends to emphasize
algorithms.
Sajjad Haider
Fall 2013
7
Types of Attributes
• There are different types of attributes
– Nominal
• Examples: ID numbers, eye color, zip codes
– Ordinal
• Examples: rankings (e.g., taste of potato chips on a
scale from 1-10), grades, height in {tall, medium,
short}
– Ratio
• Examples: temperature in Kelvin, length, time, counts
Sajjad Haider
Fall 2013
8
4
9/19/2013
Data Preprocessing
•
•
•
•
•
•
Aggregation
Sampling
Dimensionality Reduction
Feature subset selection
Discretization
Attribute Transformation
Sajjad Haider
Fall 2013
9
Aggregation
• Combining two or more attributes (or objects)
into a single attribute (or object)
• Purpose
– Data reduction
• Reduce the number of attributes or objects
– Change of scale
• Cities aggregated into regions, states, countries, etc
– More “stable” data
• Aggregated data tends to have less variability
Sajjad Haider
Fall 2013
10
5
9/19/2013
Data Normalization
• Some data mining methods, typically those that
are based on distance computation between
points in an n-dimensional space, may need
normalized data for best results.
• If the values are not normalized, the distance
measures will overweight those features that
have, on average, larger values.
Sajjad Haider
Fall 2013
11
Normalization Techniques
• Decimal Scaling
– v’(i) = v(i) / 10k
– For the smallest k such that max |v’(i)|< 1.
• Min-Max Normalization
– v’(i) = [v(i) – min(v(i))]/[max(v(i)) – min(v(i))]
• Standard Deviation Normalization
– v’(i) = [v(i) – mean(v)]/sd(v)
Sajjad Haider
Fall 2013
12
6
9/19/2013
Normalization Example
• Given one-dimensional data set X = {-5.0, 23.0,
17.6, 7.23, 1.11}, normalize the data set using
– Decimal scaling on interval [-1, 1].
– Min-max normalization on interval [0, 1].
– Standard deviation normalization.
Sajjad Haider
Fall 2013
13
Outlier Detection
• Statistics-based Methods (for one dimensional
data)
– Threshold = Mean + K x Standard Deviation
– Age = {3, 56, 23, 39, 156, 52, 41, 22, 9, 28, 139, 31, 55,
20, -67, 37, 11, 55, 45, 37}
• Distance-based Methods (for multidimensional
data)
– Distance-based outliers are those samples which do
not have enough neighbors, where neighbors are
defined through the multidimensional distance
between samples.
Sajjad Haider
Fall 2013
14
7
9/19/2013
Outlier Detection (Distance-based)
• S = {s1, s2, s3, s4, s5, s6, s7} = {(2, 4), (3, 2), (1,
1), (4, 3), (1, 6), (5, 3), (4, 2)}
• Threshold Values: p > 4, d > 3
S1
S1
S2
S3
S4
S5
Sample
p
S2
S3
S4
S5
S6
s7
S1
2
2.236
3.162
2.236
2.236
3.162
2.828
S2
2.236
1.414
4.472
2.236
1.000
1
3.605
5.000
4.472
3.162
S3
5
4.242
1.000
1.000
S4
2
5.000
5.000
S5
5
s6
3
s6
1.414
Sajjad Haider
Fall 2013
15
Outlier Detection Example II
• The number of children for different patients
in a database is given with a vector C = {3, 1, 0,
2, 7, 3, 6, 4, -2, 0, 0, 10, 15, 6}.
– Find the outliers in the set C using standard
statistical parameters mean and variance.
– If the threshold value is changed from +3 standard
deviations to +2 standard deviations, what
additional outliers are found?
Sajjad Haider
Fall 2013
16
8
9/19/2013
Outlier Detection Example III
• For a given data set X of three-dimensional samples, X
= [{1, 2, 0}, {3, 1, 4}, {2, 1, 5}, {0, 1, 6}, {2, 4, 3}, {4, 4, 2},
{5, 2, 1}, {7, 7, 7}, {0, 0, 0}, {3, 3, 3}].
• Find the outliers using the distance-based technique if
– The threshold distance is 4, and threshold fraction p for
non-neighbor samples is 3.
– The threshold distance is 6, and threshold fraction p for
non-neighbor samples is 2.
• Describe the procedure and interpret the results of
outlier detection based on mean values and variances
for each dimension separately.
Sajjad Haider
Fall 2013
17
Data Reduction
• The three basic operations in a data-reduction process are:
– Delete a row
– Delete a column (dimensionality reduction)
– Reduce the number of values in a column (smooth a feature)
• The main advantages of data reduction are
– Computing time – simpler data can hopefully lead to a
reduction in the time taken for data mining.
– Predictive/descriptive accuracy – We generally expect that by
using only relevant features, a data mining algorithm can not
only learn faster but with higher accuracy. Irrelevant data may
mislead a learning process.
– Representation of the data-mining model – The simplicity of
representation often implies that a model can be better
understood.
Sajjad Haider
Fall 2013
18
9
9/19/2013
Sampling …
• The key principle for effective sampling is the
following:
– using a sample will work almost as well as using
the entire data sets, if the sample is
representative
– A sample is representative if it has approximately
the same property (of interest) as the original set
of data
Sajjad Haider
Fall 2013
19
Types of Sampling
• Simple Random Sampling
– There is an equal probability of selecting any particular item
• Stratified sampling
– Split the data into several partitions; then draw random samples from
each partition
• Sampling without replacement
– As each item is selected, it is removed from the population
• Sampling with replacement
– Objects are not removed from the population as they are selected for the
sample.
•
Sajjad Haider
In sampling with replacement, the same object can be picked up more than
once
Fall 2013
20
10
9/19/2013
Sample Size
8000 points
Sajjad Haider
2000 Points
500 Points
Fall 2013
21
Feature Subset Selection
• Another way to reduce dimensionality of data
• Redundant features
– duplicate much or all of the information contained in
one or more other attributes
– Example: purchase price of a product and the amount
of sales tax paid
• Irrelevant features
– contain no information that is useful for the data
mining task at hand
– Example: students' ID is often irrelevant to the task of
predicting students' GPA
Sajjad Haider
Fall 2013
22
11
9/19/2013
Mean and Variance based Feature
Selection
• Suppose A and B are sets of feature values
measured for two different classes, and n1
and n2 are the corresponding number of
samples.
– SE(A – B) = Sqrt (var(A)/n1 + var(B)/n2)
– TEST: |mean(A) – mean(B)|/SE(A – B) > threshold
value
• It is assumed that the given feature is
independent of the others.
Sajjad Haider
Fall 2013
23
Mean-Variance Example
• SE(XA – XB) = 0.169
• SE(YA – YB) = 0.0875
• |mean(XA) – mean(XB)| /
SE(XA – XB) = 0.0375 < 0.5
• |mean(YA) – mean(YB)| /
SE(YA – YB) = 2.2667 > 0.5
Sajjad Haider
Fall 2013
X
Y
C
0.3
0.7
A
0.2
0.9
B
0.6
0.6
A
0.5
0.5
A
0.7
0.7
B
0.4
0.9
B
24
12
9/19/2013
Feature Ranking Exercise
• Given the data set X with three input features and
one output feature representing the classification
of samples
I1
I2
I3
O
2.5
1.6
5.9
0
7.2
4.3
2.1
1
3.4
5.8
1.6
1
5.6
3.6
6.8
0
4.8
7.2
3.1
1
8.1
4.9
8.3
0
6.3
4.8
2.4
1
• Rank the features using a comparison of means
and variances
Sajjad Haider
Fall 2013
25
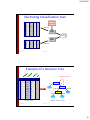
Classification: Definition
• Given a collection of records (training set )
– Each record contains a set of attributes, one of the
attributes is the class.
• Find a model for class attribute as a function
of the values of other attributes.
• Goal: previously unseen records should be
assigned a class as accurately as possible.
– A test set is used to determine the accuracy of the
model. Usually, the given data set is divided into training
and test sets, with training set used to build the model
and test set used to validate it.
Sajjad Haider
Fall 2013
26
13
9/19/2013
Classification: Motivation
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
income student credit_rating
high
no fair
high
no excellent
high
no fair
medium
no fair
low
yes fair
low
yes excellent
low
yes excellent
medium
no fair
low
yes fair
medium
yes fair
medium
yes excellent
medium
no excellent
high
yes fair
medium
no excellent
Sajjad Haider
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
Fall 2013
27
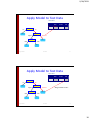
Decision/Classification Tree
age?
<=30
31..40
overcast
student?
no
no
Sajjad Haider
yes
>40
credit rating?
excellent
yes
fair
yes
yes
Fall 2013
28
14
9/19/2013
Illustrating Classification Task
Tid
Attrib1
1
Yes
Large
Attrib2
125K
Attrib3
No
2
No
Medium
100K
No
3
No
Small
70K
No
4
Yes
Medium
120K
No
5
No
Large
95K
Yes
6
No
Medium
60K
No
7
Yes
Large
220K
No
8
No
Small
85K
Yes
9
No
Medium
75K
No
10
No
Small
90K
Yes
Learning
algorithm
Class
Induction
Learn
Model
Model
10
Training Set
Tid
Attrib1
Attrib2
Attrib3
11
No
Small
55K
?
12
Yes
Medium
80K
?
13
Yes
Large
110K
?
14
No
Small
95K
?
15
No
Large
67K
?
Apply
Model
Class
Deduction
10
Test Set
Sajjad Haider
Fall 2013
29
Example of a Decision Tree
Tid Refund Marital
Status
Taxable
Income Cheat
1
Yes
Single
125K
No
2
No
Married
100K
No
3
No
Single
70K
No
4
Yes
Married
120K
No
5
No
Divorced 95K
Yes
6
No
Married
No
7
Yes
Divorced 220K
No
8
No
Single
85K
Yes
9
No
Married
75K
No
10
No
Single
90K
Yes
60K
Splitting Attributes
Refund
Yes
No
NO
MarSt
Single, Divorced
TaxInc
< 80K
NO
Married
NO
> 80K
YES
10
Model: Decision Tree
Training Data
Sajjad Haider
Fall 2013
30
15
9/19/2013
Another Example of Decision Tree
Tid Refund Marital
Status
Taxable
Income Cheat
1
Yes
Single
125K
No
2
No
Married
100K
No
3
No
Single
70K
No
4
Yes
Married
120K
No
5
No
Divorced 95K
Yes
6
No
Married
No
7
Yes
Divorced 220K
No
8
No
Single
85K
Yes
9
No
Married
75K
No
10
No
Single
90K
Yes
60K
MarSt
Married
NO
Single,
Divorced
Refund
No
Yes
NO
TaxInc
< 80K
> 80K
YES
NO
There could be more than one tree that fits
the same data!
10
Sajjad Haider
Fall 2013
31
Decision Tree Classification Task
Tid
Attrib1
1
Yes
Large
Attrib2
125K
Attrib3
No
2
No
Medium
100K
No
3
No
Small
70K
No
4
Yes
Medium
120K
No
5
No
Large
95K
Yes
6
No
Medium
60K
No
7
Yes
Large
220K
No
8
No
Small
85K
Yes
9
No
Medium
75K
No
10
No
Small
90K
Yes
Tree
Induction
algorithm
Class
Induction
Learn
Model
Model
10
Training Set
Tid
Attrib1
Attrib2
Attrib3
11
No
Small
55K
?
12
Yes
Medium
80K
?
13
Yes
Large
110K
?
14
No
Small
95K
?
15
No
Large
67K
?
Apply
Model
Class
Decision
Tree
Deduction
10
Test Set
Sajjad Haider
Fall 2013
32
16
9/19/2013
Apply Model to Test Data
Test Data
Start from the root of tree.
Refund
Yes
Refund Marital
Status
Taxable
Income Cheat
No
80K
Married
?
10
No
NO
MarSt
Married
Single, Divorced
TaxInc
NO
< 80K
> 80K
YES
NO
Sajjad Haider
Fall 2013
33
Apply Model to Test Data
Test Data
Refund
Yes
Refund Marital
Status
Taxable
Income Cheat
No
80K
Married
?
10
No
NO
MarSt
Married
Single, Divorced
TaxInc
< 80K
NO
Sajjad Haider
NO
> 80K
YES
Fall 2013
34
17
9/19/2013
Apply Model to Test Data
Test Data
Refund
Yes
Refund Marital
Status
Taxable
Income Cheat
No
80K
Married
?
10
No
NO
MarSt
Married
Single, Divorced
TaxInc
NO
< 80K
> 80K
YES
NO
Sajjad Haider
Fall 2013
35
Apply Model to Test Data
Test Data
Refund
Yes
Refund Marital
Status
Taxable
Income Cheat
No
80K
Married
?
10
No
NO
MarSt
Married
Single, Divorced
TaxInc
< 80K
NO
Sajjad Haider
NO
> 80K
YES
Fall 2013
36
18
9/19/2013
Apply Model to Test Data
Test Data
Refund
Yes
Refund Marital
Status
Taxable
Income Cheat
No
80K
Married
?
10
No
NO
MarSt
Married
Single, Divorced
TaxInc
NO
< 80K
> 80K
YES
NO
Sajjad Haider
Fall 2013
37
Apply Model to Test Data
Test Data
Refund
Yes
Refund Marital
Status
Taxable
Income Cheat
No
80K
Married
?
10
No
NO
MarSt
Married
Single, Divorced
TaxInc
< 80K
NO
Sajjad Haider
Assign Cheat to “No”
NO
> 80K
YES
Fall 2013
38
19
9/19/2013
Decision Tree Classification Task
Tid
Attrib1
1
Yes
Large
Attrib2
125K
Attrib3
No
2
No
Medium
100K
No
3
No
Small
70K
No
4
Yes
Medium
120K
No
5
No
Large
95K
Yes
6
No
Medium
60K
No
7
Yes
Large
220K
No
8
No
Small
85K
Yes
9
No
Medium
75K
No
10
No
Small
90K
Yes
Tree
Induction
algorithm
Class
Induction
Learn
Model
Model
10
Training Set
Tid
Attrib1
Attrib2
Attrib3
11
No
Small
55K
?
12
Yes
Medium
80K
?
13
Yes
Large
110K
?
14
No
Small
95K
?
15
No
Large
67K
?
Apply
Model
Class
Decision
Tree
Deduction
10
Test Set
Sajjad Haider
Fall 2013
39
Tree Induction
• Greedy strategy.
– Split the records based on an attribute test that
optimizes certain criterion.
• Issues
– Determine how to split the records
• How to specify the attribute test condition?
• How to determine the best split?
– Determine when to stop splitting
Sajjad Haider
Fall 2013
40
20
9/19/2013
How to Specify Test Condition?
• Depends on attribute types
– Nominal
– Ordinal
– Continuous
• Depends on number of ways to split
– 2-way split
– Multi-way split
Sajjad Haider
Fall 2013
41
How to determine the Best Split
• Greedy approach:
– Nodes with homogeneous class distribution are
preferred
• Need a measure of node impurity:
C0: 5
C1: 5
Sajjad Haider
C0: 9
C1: 1
Non-homogeneous,
Homogeneous,
High degree of impurity
Low degree of impurity
Fall 2013
42
21
9/19/2013
Measures of Node Impurity
• Gini Index
• Entropy
• Misclassification error
Sajjad Haider
Fall 2013
43
Measure of Impurity: GINI
• Gini Index for a given node t :
GINI (t ) 1 [ p( j | t )]2
j
(NOTE: p( j | t) is the relative frequency of class j at node t).
– Maximum (1 - 1/nc) when records are equally distributed
among all classes, implying least interesting information
– Minimum (0.0) when all records belong to one class,
implying most interesting information
C1
C2
0
6
Gini=0.000
Sajjad Haider
C1
C2
1
5
Gini=0.278
C1
C2
2
4
Gini=0.444
Fall 2013
C1
C2
3
3
Gini=0.500
44
22
9/19/2013
Examples for computing GINI
GINI (t ) 1 [ p( j | t )]2
j
C1
C2
0
6
C1
C2
1
5
P(C1) = 1/6
C1
C2
2
4
P(C1) = 2/6
Sajjad Haider
P(C1) = 0/6 = 0
P(C2) = 6/6 = 1
Gini = 1 – P(C1)2 – P(C2)2 = 1 – 0 – 1 = 0
P(C2) = 5/6
Gini = 1 – (1/6)2 – (5/6)2 = 0.278
Gini = 1 –
P(C2) = 4/6
(2/6)2 –
(4/6)2 = 0.444
Fall 2013
45
Classification: Motivation
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
Sajjad Haider
income student credit_rating
high
no fair
high
no excellent
high
no fair
medium
no fair
low
yes fair
low
yes excellent
low
yes excellent
medium
no fair
low
yes fair
medium
yes fair
medium
yes excellent
medium
no excellent
high
yes fair
medium
no excellent
Fall 2013
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
46
23
9/19/2013
Binary Attributes: Computing GINI Index
• Splits into two partitions
• Effect of Weighing partitions:
– Larger and Purer Partitions are sought for.
Student?
Yes
Gini(N1)
= 1 – (6/7)2 – (1/7)2
= 0.24
No
Node N1
Node N2
Gini(Student)
= 7/14 * 0.24 +
7/14 * 0.49
= ??
Gini(N2)
= 1 – (3/7)2 – (4/7)2
= 0.49
Sajjad Haider
GINI Index for Buy Computer Example
• Gini (Income):
• Gini (Credit_Rating):
• Gini (Age):
Sajjad Haider
Fall 2013
48
24