Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
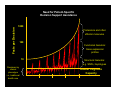
Genomics and Health Data Standards: Lessons from the Past and Present for a Genome-enabled Future Daniel Masys, MD Professor and Chair Department of Biomedical Informatics Professor of Medicine Vanderbilt University School of Medicine Principal Investigator electronic Medical Records and Genomics (eMERGE) Coordination Center Topics z z The eMERGE consortium: on the frontier of genomes and phenotypes derived from clinical sources Lessons for future standards learned from the last 40 years of biomedical informatics RFA HG-07-005: Genome-Wide Studies in Biorepositories with Electronic Medical Record Data z z 2007 NIH Request for Applications from the National Human Genome Research Institute “The purpose of this funding opportunity is to provide support for investigative groups affiliated with existing biorepositories to develop necessary methods and procedures for, and then to perform, if feasible, genome-wide studies in participants with phenotypes and environmental exposures derived from electronic medical records, with the aim of widespread sharing of the resulting individual genotype-phenotype data to accelerate the discovery of genes related to complex diseases.” eMERGE: an NHGRI-funded consortium for Biobanks linked to EMR data z Consortium members z z z z z z Group Health of Puget Sound Marshfield Clinic Mayo Clinic Northwestern University Vanderbilt University Condition of NIH funding: contribute genomic and EMR-derived phenotype data to dbGAP database at NCBI Dementia Cataracts Type II diabetes Coordinating center Peripheral vascular disease QRS duration z z z z Each site includes DNA linked to electronic medical records Each project includes community engagement, genome science, natural language processing capability for EMR data Research plans include identifying a phenotype of interest in 3,000 subjects and conduct of a genomewide association study at each center: Σ=18,000 Supplemental funding provided for cross-network phenotypes Supplement phenotypes using genotyped samples from primary phenotypes* *The benefit of data from routine clinical testing results recorded in EHR RBC/WBC Diabetic Retinopathy Lipid Levels & Height GFR GHC 3,579 230 3,114 1,713 Marshfield 3,865 213 3,693 3,929 Mayo 3,346 806 3,175 3,340 NU 2,484 139 2,816 1,485 VU 2,650 1,449 1,631 2,679 Informatics Issues in eMERGE z z z z Determination of comparability of patient populations across institutions Data exchange standards for phenotype data Representation of change over time (repeated measures) and ‘clinical uncertainty’ for EMR-derived observations (definite – probable – possible for assertion and negation) Re-identification potential of clinical data and associated samples: maximizing scientific value while complying with federal privacy protection policies Lessons learned from eMERGE z z z Structured data alone (ICD9 codes, labs, meds) is not enough to accurately define clinical phenotypes in EMR data. Natural language processing of clinician notes improves both sensitivity and specificity of phenotype selection logic Once selection logic has been validated at one site, it can be successfully shared as pseudocode and implemented at other sites with widely varying EMR systems architectures The problem with ICD codes z z z ICD code sets contain both false negatives and false positives False negatives: z Outpatient billing limited to 4 diagnoses/visit z Outpatient billing done by physicians (e.g., takes too long to find the unknown ICD9) z Inpatient billing done by professional coders: z omit codes that don’t pay well z can only code problems actually explicitly mentioned in documentation False positives z Diagnoses evolve over time -- physicians may initially bill for suspected diagnoses that later are determined to be incorrect z Billing the wrong code (perhaps it is easier to find for a busier clinician) z Physicians may bill for a different condition if it pays for a given treatment z Example: Anti-TNF biologics (e.g., infliximab) originally not covered for psoriatic arthritis, so rheumatologists would code the patient as having rheumatoid arthritis Observations about clinical genomics z z z Genomic data is the current poster child for complexity in healthcare No practitioner can absorb and remember more than a tiny fraction of the knowledge base of human variation Therefore, computerized clinical decision support is the only effective way to insert genomic variation-based guidance into clinical care Need for Patient-Specific Decision Support Assistance Facts per Decision 1000 Proteomics and other effector molecules 100 Functional Genetics: Gene expression profiles 10 Structural Genetics: e.g. SNPs, haplotypes Decisions by clinical phenotype i.e., traditional health care Human Cognitive Capacity 1990 2000 2010 2020 Observations about genomic data in general z z Predictably, some future uses of genomic data will be so creative that nobody could have predicted them. “Raw data” e.g., primary DNA sequence, specific SNP values, should be retained when adding clinical interpretations, not discarded in the synthesis and reporting of those interpretations Lessons learned about standards z z The most successful and widely used standards are messaging and communications standards e.g., TCP/IP, http, smtp, ftp, HL7. Knowledge representation standards tend to be widely used only if driven by financial processes, government mandate (e.g., ICD-9), or sustained government investment (e.g., MeSH, SNOMED, UMLS Metathesaurus) Lessons learned about standards, cont’d z z Familiar and usable wins over theoretically correct but too complex e.g., HL7 v.2 vs. v.3 Lindberg’s axiom: “Systems that get used get better.” URL: www.gwas.net Commander Willard Decker: V'ger... expects an answer. Captain James T. Kirk: An answer? I don't even know the question. Star Trek, the movie 1979