Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
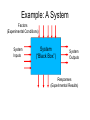
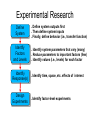
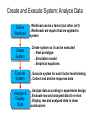
VLSI Systems Design—Experiments Necessary steps: • Explore the problem space • Design experiment(s) • Carry out experiment(s) • Analyze results software packages: R, Matlab, … • Report results Example: design a “better” transistor What do we mean by “better”? What FACTORS influence design? --fabrication --design --environmental For which of these is there random variation? Which “factors” do we want to investigate? SUMMARY—15 IMPORTANT POINTS FOR EXPERIMENTERS: 1. Even careful experimentation and observation may miss important facts; new experiments may cause old conclusions to be discarded; EXPERIMENTS ARE NOT PROOFS. 2. It is just as important to report NEGATIVE results as to report POSITIVE results. The experimenter must always accurately record and thoroughly report ALL results. 3. IGNORING IMPORTANT FACTORS CAN LEAD TO ERRONEOUS CONCLUSIONS, SOMETIMES WITH TRAGIC RESULTS. 4. YOUR RESULTS ARE ONLY VALID FOR THE PART OF THE DATA-TREATMENT SPACE YOU HAVE EXPLORED; YOU CANNOT CLAIM KNOWLEDGE OF WHAT YOU HAVE NOT EXPLORED 5. An experiment is worthless unless it can be REPEATED by other researchers using the same experimental setup; experimenters have a duty to the research community to report enough about their experiment and data so that other researchers can verify their claims 6. YOU ONLY GET ANSWERS TO THE QUESTIONS YOU ASK 7. if your are going to use a (pseudo-)RANDOM NUMBER GENERATOR, make sure the output behaves enough like a sequence of TRUE RANDOM NUMBERS 8. An experiment must be repeated a SUFFICIENT NUMBER OF TIMES for the results to be attributed to more than random error 9. Choosing the CORRECT MEASURE for the question you are asking is an important part of the experimental design 10. Reporting CORRECT results, PROPERLY DISPLAYED, is an integral part of a well-done experiment 11. MISUSE OF GRAPH LABELING can lead to MISLEADING RESULTS AND INCORRECT CONCLUSIONS 12. INTERPOLATING your results to regions you have not explored can lead to INCORRECT CONCLUSIONS 13. IGNORING the “NULL HYPOTHESIS” when reporting your results can be very misleading 14. Don’t mistake CORRELATION for DEPENDENCE 15. Justify your choice of CURVE using VALID STATISTICS, not “appearance” Topics • Analyzing and Displaying Data – Simple Statistical Analysis – Comparing Results – Curve Fitting • Designing Experiments: Factorial Designs – 2K Designs Including Replications – Full Factorial Designs • Ensuring Data Meets Analysis Criteria • Presenting Your Results; Drawing Conclusions Example: A System Factors (Experimental Conditions) System Inputs System (“Black Box”) System Outputs Responses (Experimental Results) Experimental Research Define System Identify Factors and Levels Define system outputs first ● Then define system inputs ● Finally, define behavior (i.e., transfer function) ● Identify system parameters that vary (many) ● Reduce parameters to important factors (few) ● Identify values (i.e., levels) for each factor ● Identify Response(s) ● Identify time, space, etc. effects of interest Design Experiments ● Identify factor-level experiments Create and Execute System; Analyze Data Define Workload Create System Execute System Analyze & Display Data Workload can be a factor (but often isn't) ● Workloads are inputs that are applied to system ● Create system so it can be executed ● Real prototype ● Simulation model ● Empirical equations ● Execute system for each factor-level binding ● Collect and archive response data ● Analyze data according to experiment design ● Evaluate raw and analyzed data for errors ● Display raw and analyzed data to draw conclusions ● Some Examples Analog Simulation – Which of three solvers is best? – What is the system? – Responses • Fastest simulation time • Most accurate result • Most robust to types of circuits being simulated – Factors • Solver • Type of circuit model • Matrix data structure Epitaxial growth – New method using nonlinear temp profile – What is the system? – Responses • Total time • Quality of layer • Total energy required • Maximum layer thickness – Factors • Temperature profile • Oxygen density • Initial temperature • Ambient temperature Basic Descriptive Statistics for a Random Sample X • Mean • Median • Mode • Variance / standard deviation • Z scores: Z = (X – mean)/ (standard deviation) • Quartiles, box plots • Q-Q plot Note: these can be deceptive. For example, if P (X = 0) = P(X = 100) = 0.5 and P (Y = 50 ) = 1, Then X and Y have the same mean (and nastier examples can be constructed) home.oise.utoronto.ca/~thollenstein/Exploratory%20Data%20Analysis.ppt SIMPLE MODELS OF DATA Example: Evaluation of a new wireless network protocol System: wireless network with new protocol Workload: 10 messages applied at single source Each message identical configuration Experiment output: Roundtrip latency per message (ms) Data file “latency.dat” Ms. # Latency 1 2 3 4 5 6 7 8 9 10 22 23 19 18 15 20 26 17 19 17 Mean: 19.6 ms Variance: 10.71 ms2 Std Dev: 3.27 ms Hypothesis: Distribution is N(m,s2) Verify Model Preconditions Check randomness Use plot of residuals around mean Residuals “appear” random Check normal distribution Use quantile-quantile (Q-Q) plot Pattern adheres consistently along ideal quantile-quantile line http://itl.nist.gov/div898/software/dataplot/refman1/ch2/quantile.pdf Confidence Intervals Sample mean vs Population mean If many samples are collected, about 1 - a will contain the “true mean” CI: > 30 samples ( x z[1a / 2] s / n , x z[1a / 2] s / n ) CI: < 30 samples x t[1a / 2;n1] s / n , x t[1a / 2;n1] s / n ) For the latency data, m = 10, a = 0.05: (17.26, 21.94) Raj Jain, “The Art of Computer Systems Performance Analysis,” Wiley, 1991. Depth Scatter and Line Plots Resistance profile of doped silicon epitaxial layer Expect linear resistance increase as depth increases Resistance 1 1.689015 2 4.486722 3 7.915209 4 6.362388 5 11.830739 6 12.329104 7 14.011396 8 17.600094 9 19.022146 10 21.513802 Linear Regression Statistics (hypothesis: resistance = b0 + b1*depth + error) model = lm(Resistance ~ Depth) summary(model) Residuals: Min -2.11330 1Q -0.40679 Median 0.05759 3Q 0.51211 Max 1.57310 t value -0.077 17.336 “reject hypotheses b0 = 0, b1 = 0” Pr(>|t|) 0.94 1.25e-07 *** Coefficients: Estimate -0.05863 2.13358 Std. Error 0.76366 0.12308 (Intercept) Depth --Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 Residual standard error: 1.118 on 8 degrees of freedom “variance of error: (1.118)2” Multiple R-Squared: 0.9741, Adjusted R-squared: 0.9708 F-statistic: 300.5 on 1 and 8 DF, p-value: 1.249e-07 “evidence this estimate valid” (Using R system; based on http://www.stat.umn.edu/geyer/5102/examp/reg.html Validating Residuals Errors are marginally normally distributed due to “tails” Comparing Two Sets of Data Example: Consider two different wireless access points. Which one is faster? Inputs: same set of 10 messages communicated through both access points. Approach: Take difference of data and determine CI of difference. If CI straddles zero, cannot tell which access point is faster. Response (usecs): Latency1 Latency2 22 19 23 20 19 24 18 20 15 14 20 18 26 21 17 17 19 17 17 18 CI95% = (-1.27, 2.87) usecs Confidence interval straddles zero. Thus, cannot determine which is faster with 95% confidence Plots with error bars Execution time of SuperLU linear system solution on parallel computer Ax = b For each p, ran problem multiple times with same matrix size but different values Determined mean and CI for each p to obtain curve and error intervals Matrix density p > model = lm(t ~ poly(p,4)) > summary(model) Curve Fitting Call: lm(formula = t ~ poly(p, 4)) Residuals: 1 2 -0.4072 0.7790 3 4 5 0.5840 -1.3090 -0.9755 Coefficients: Estimate Std. Error t value (Intercept) 236.9444 0.7908 299.636 poly(p, 4)1 679.5924 2.3723 286.467 poly(p, 4)2 268.3677 2.3723 113.124 poly(p, 4)3 42.8772 2.3723 18.074 poly(p, 4)4 2.4249 2.3723 1.022 --Signif. codes: 0 `***' 0.001 `**' 0.01 6 0.8501 Pr(>|t|) 7.44e-10 8.91e-10 3.66e-08 5.51e-05 0.364 7 8 2.6749 -3.1528 *** *** *** *** `*' 0.05 `.' 0.1 ` ' 1 Residual standard error: 2.372 on 4 degrees of freedom Multiple R-Squared: 1, Adjusted R-squared: 0.9999 F-statistic: 2.38e+04 on 4 and 4 DF, p-value: 5.297e-09 9 0.9564 Model Validation: y’ = ax + b R2 – Coefficient of Determination “How well does the data fit your model?” What proportion of the “variability” is accounted for by the statistical model? (what is ratio of explained variation to total variation?) Suppose we have measurements y1, y2, …, yn with mean m And predicted values y1’, y2’, …, yn’ (yi’ = axi + b = yi + ei) SSE = sum of squared errors = ∑ (yi – yi’)2 = ∑ei2 SST = total sum of squares =∑ (yi – m)2 SSR = SST – SSE = residual sum of squares = ∑ (m – yi’)2 R2 = SSR/SST = (SST-SSE)/SST R2 is a measure of how good the model is. The closer R2 is to 1 the better. Example: Let SST = 1499 and SSE = 97. Then R2 = 93.5% http://www-stat.stanford.edu/~jtaylo/courses/stats191/notes/simple_diagnostics.pdf Using the t-test Consider the following data (“sleep.R”) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 extra group 0.7 1 -1.6 1 -0.2 1 -1.2 1 -0.1 1 3.4 1 3.7 1 0.8 1 0.0 1 2.0 1 1.9 2 0.8 2 1.1 2 0.1 2 -0.1 2 4.4 2 5.5 2 1.6 2 4.6 2 3.4 2 From “Introduction to R”, http://www.R-project.org T.test result > t.test(extra ~ group, data = sleep) Welch Two Sample t-test data: extra by group t = -1.8608, df = 17.776, p-value = 0.0794 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -3.3654832 0.2054832 sample estimates: mean of x mean of y p-value is smallest 1- confidence where null 0.75 2.33 hypothesis. not true. p-value = 0.0794 means difference not 0 above 92% Factorial Design What “factors” need to be taken into account? How do we design an efficient experiment to test all these factors? How much do the factors and the interactions among the factors contribute to the variation in results? Example: 3 factors a,b,c, each with 2 values: 8 combinations But what if we want random order of experiments? What if each of a,b,c has 3 values? Do we need to run all experiments? http://www.itl.nist.gov/div898/handbook/pri/section3/pri3332.htm Standard Procedure-Full Factorial Design (Example) Variables A,B,C: each with 3 values, Low, Medium, High (coded as -1,0,1) “Signs Table”: 1 A B C -1 -1 -1 2 +1 -1 -1 3 -1 +1 -1 4 +1 +1 -1 5 -1 -1 +1 6 +1 -1 +1 7 -1 +1 +1 8 +1 +1 +1 1.Run the experiments in the table (“2 level, full factorial design”) 2.Repeat the experiments in this order n times by using rows 1,…,8,1,…,8, … (“replication”) 3.Use step 2, but choose the rows randomly (“randomization”) 4.Use step 4, but add some “center point runs”, for example, run the case 0,0,0, then use 8 rows, then run 0,0,0, …finish with a 0,0,0 case In general, for 5 or more factors, use a “fractional factorial design” 2k Factorial Design Example: k = 2, factors are A,B, and X’s are computed from the signs table: y = q0 + qAxA + qBxB + qABxAB SST = total variation around the mean = ∑ (yi – mean)2 = SSA+SSB+SSAB where SSA = 22qA2 (variation allocated to A), and SSB, SSAB are defined similarly Note: var(y) = SST/( 2k – 1) Fraction of variation explained by A = SSA/SST Example: 2k Design www.stat.nuk.edu.tw/Ray-Bing /ex-design/ex-design/ExChapter6.ppt Factor Levels Line Length (L) 32, 512 words No. Sections (K) 4, 16 sections Control Method (C) multiplexed, linear Experiment Design Address Trace Cache Misses Are all factors needed? If a factor has little effect on the variability of the output, why study it further? L 32 512 32 512 32 512 32 512 K 4 4 16 16 4 4 16 16 C Misses mux mux mux mux lin lin lin lin Encoded Experiment Design Method? L K C Misses a. Evaluate variation for each factor using only -1 -1 -1 two levels each 1 -1 -1 b. Must consider interactions as well -1 1 -1 Interaction: effect of a factor dependent on the levels of another 1 -1 1 -1 1 1 -1 -1 1 1 -1 1 1 1 1 Example: 2k Design (continued) http://www.cs.wustl.edu/~jain/cse567-06/ftp/k_172kd/sld001.htm Obtain Reponses L -1 1 -1 1 -1 1 -1 1 K -1 -1 1 1 -1 -1 1 1 C -1 -1 -1 -1 1 1 1 1 Misses 14 22 10 34 46 58 50 86 Analyze Results (Sign Table) I L K C LK LC KC LKC 1 -1 -1 -1 1 1 1 -1 1 1 -1 -1 -1 -1 1 1 1 -1 1 -1 -1 1 -1 1 1 1 1 -1 1 -1 -1 -1 1 -1 -1 1 1 -1 -1 1 1 1 -1 1 -1 1 -1 -1 1 -1 1 1 -1 -1 1 -1 1 1 1 1 1 1 1 1 qi: 40 10 5 20 5 2 3 Ex: y1 = 14 = q0 – qL –qK –qC + qLK + qLC + qKC – qLKC = 1/∑(signi*Responsei) Solve for q’s SSL = 23q2L = 800 SST = SSL+SSK+SSC+SSLK+SSLC+SSKC+SSLKC = 800+200+3200+200+32+72+8 = 4512 %variation(L) = SSL/SST = 800/4512 = 17.7% Miss.Rate (yj) 14 22 10 34 46 58 50 86 1 Effect % Variation L 17.7 C 4.4 K 70.9 LC 4.4 LK 0.7 CK 1.6 LCK 0.2 Full Factorial Design Model: yij = m+ai + bj + eij Effects computed such that ∑ai = 0 and ∑bj = 0 m = mean(y..) aj = mean(y.j) – m bi = mean(yi.) – m Experimental Errors SSE = ei2j SS0 = abm2 SSA= b∑a2 SSB= a∑b2 SST = SS0+SSA+SSB+SSE Full-Factorial Design Example Determination of the speed of light Morley Experiments Factors: Experiment No. (Expt) Run No. (Run) Levels: Expt – 5 experiments Run – 20 repeated runs 001 002 003 004 019 020 021 022 023 096 097 098 099 100 Expt Run Speed 1 1 850 1 2 740 1 3 900 1 4 1070 <more data> 1 19 960 1 20 960 2 1 960 2 2 940 2 3 960 <more data> 5 16 940 5 17 950 5 18 800 5 19 810 5 20 870 Box Plots of Factors Two-Factor Full Factorial > fm <- aov(Speed~Run+Expt, data=mm) # Determine ANOVA > summary(fm) # Display ANOVA of factors Df Sum Sq Mean Sq F value Pr(>F) Run 19 113344 5965 1.1053 0.363209 Expt 4 94514 23629 4.3781 0.003071 ** Residuals 76 410166 5397 --Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 Conclusion: Data across experiments has acceptably small variation, but variation within runs is significant Visualizing Results: Tufte’s Principles • Have a properly chosen format and design • Use words, numbers, and drawing together • Reflect a balance, a proportion, a sense of relevant scale • Display an accessible complexity of detail • Have a story to tell about the data • Draw in a professional manner • Avoid content-free decoration, including “chart junk” Back to the transistor: • What factors are there? • Which ones do we want to investigate? • How should we define our experiments? • What role will randomness play? (simulation/actual) • How should we report the results?