Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Mining Confident Minimal Rules with
Fixed-Consequents
Imad Rahal, Dongmei Ren, Weihua (Allan) Wu,
and William Perrizo
Computer Science & Operations Research Department
North Dakota State University
Association Rule Mining
A sub-branch under the broad umbrella of
data mining
Initially proposed in the context of MBR by
Agrawal from IBM Almaden
The process of extracting interesting, usseful
and actionable associations and/or correlation
relationships among large sets of data items.
From data
if-then statements
Probabilistic in nature
strength could be measured
An association rule defines a relationship
of the form:
A C (if A then C)
A is the antecedent and C the consequent
Given a set of transactions D containing
items form some itemspace I
“find all strong association rules with support
> s and confidence > c.”
APRIORI
First successful attempt to do ARM
APRIORI is a two-step process:
Find all frequent itemsets
Satisfy minimum support threshold
Most computationally intensive
Generate strong association rules
from the frequent itemsets
Satisfy minimum confidence threshold
Title
Mining Confident Minimal Rules with
Fixed-Consequents
Important keywords in the title are
Confident
Minimal
Fixed-Consequent
Confident
Confidence-based
No elimination of the importance of support
No support pruning
very low that it is impractical to be used as a base for
pruning
“blow-up” in the rule space due to the
inapplicability of the downward closure property
of support:
No itemset I can be frequent unless all of its subsets
are also frequent
Confidence gives us trust in a rule
A 95% confident induces an error rate of 5%
when generalized
Thus we always want high confidence (so
as to tolerate less error)
Unlike confidence, the support fluctuates
depending on the dataset we operate on
Cohen et al (2001) argues that rules with high
support are obvious and uninteresting
For MBR data store managers always like
to see high support values for their rules
More statistical significance to the result
Analysis patient records databases for
combination of attributes values
associated with specific diseases
Repetitive to detect strong patterns early on
Support values expected to be (and hoped to
be) relatively low
A number of confidence-based ARM approaches
have been devised to mine rules of item pairs
that match some confidence threshold (Fujiwara
and Ullman , 2000)
Our approach would be an extension to those
Minimal instead of singleton
Other approaches uses variants of support
(Bayardo (1999) – Dense-Miner)
Minimality
A rule, R, is said to be minimal if there exists no
other rule, S, such that
R and S are confident,
R and S have the same consequent,
and the antecedent of R is a superset of that of S
In some applications, non-minimal rules don’t
add much knowledge
R1:“formula milk” “diapers” with highly enough
confidence
R2:“formula milk”, “baby shampoo” “diapers”.
Support of a minimal rule forms an upper
bound on all derived non-minimal rules
highest support rules without having the
user to specify a minimum support threshold
Minimal antecedents
Ordonez (1999)…medical data
Becquet (2002)…genome analysis
Bastide (2000)
Fixed-Consequent
The consequent of all rules is pre-specified
by the user
Very well motivated in the literature
Sometimes used for classification
In the context of Precision Agriculture
Finding association between high yield quality other
properties bands like Red, Green, Blue, NIR,…
High yield would be the fixed consequent
Approach
Set Enumerations trees (Raymon 1993) to
mine all antecedents of the selected
consequent
Proposed before for ARM
Transform the problem from a random subset
search problem to an organized tree search
problem
Depth first discovery of antecedents
Pruning conditions
Less-than-two-support pruning: If the
support (IC) < 2, then eliminate I
all supersets of I will produce rules with
support < 2
downward closed
Minimality pruning: If the confidence
(IC) >= minconf, then
all supersets of I might only produce nonminimal rules
downward closed
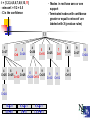
-I = {1,2,3,4,5,6,7,8,9,10,11}
- minconf. = 1/2 = 0.5
- C is the confidence
- Nodes in red have zero or one
support
- Terminated nodes with confidence
greater or equal to minconf are
labeled with X (produce rules)
{}
1
C=3/7
4
6
C=2/5 C=2/5
4
C=2/6
5
C=1/5
6
C=2/5
9
6
8
C=2/5
C=2/4 C=1/3
8
C=1/2
3
2
C=0 C=2/4
9
8
C=2/6
C=1/2
9
C=2/4
1011
4,611
6,911
311
6,811
1,4,911
7
C=0
9
C=1/2
8
C=2/6
9
C=1/3
9
C=3/7
10
C=2/4
A problem
Some non-minimal rules might be
generated!
{1,9} 11
{1,8,9} 11
To rectify the problem, we utilize an
adapted form of Tabu search
During the processing of an item I
Associate a temporary taboo list (TL)
Store all the nodes that don’t produce rules when joined
with I
Before testing for a new potential rule including I, X,I C,
check if any subset X is in TLI
In Tabu search, we store moves in the space that
have been visited without a desired result so as not
to revisit them
Here we, store all itemsets that violate any of the
pruning steps (downward closed) so as not to revisit
any of their supersets
Supersets need to be pruned
Implementation
We adopt a vertical data representation
Antecedents of rules are produced in
depth-first order which induces a lot of
database scans for horizontal data
Faster computation of support and
confidence
Compressed in the case of highly sparse data
better memory utilization
Processing based on logical operations
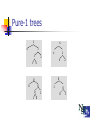
Predicate Tree (P-tree) Technology
Column1 Column2
0
1
0
1
0
1
0
1
1
0
0
0
1
1
1
1
3
6
0
1
1
c) P1
Pure1
3
Mixed
1
1
1
1
0
0
1
1
b) The resulting two bit
groups
a) A 2-column table
Pure0
0
0
0
0
1
0
1
1
4
2
2
0
0
d) P2
2
Pure-1 trees
3
6
0
3
1
1
4
2
2
0
0
2
0
0
0
0
0
1 0
1
1
0
0
1
Every data item has is represented using a Ptree
Conf(ac) = RootCount(Pa AND Pc)/ RootCount(Pa)
Additionally all Taboo lists are represented in
binary using P-trees to speed up their scan
Comparison analysis
Conducted on a P-II 400 with 128 SDRAM
running Red hat Linux 9.1.
C++ was used for coding
No benchmarks
Compared with Dense-Miner (Bayardo 1999)
capable of mining association rules with fixed
consequents at very low support thresholds
Fundamental differences exists between the
two approaches:
Dense-Miner mines all association rules while we
only mine minimal, confident rules
Dense-Miner uses a variant of support (coverage
= minimum support divided by support of the
fixed consequent ) as a pruning mechanism while
this is not the case in our work (expect for support
of less than 2)
All rules produced by our approach that have
a support value greater than the minimum
support threshold used for Dense-Miner will
be produced by Dense-Miner also.
Trans.
Items
Items per trans.
Connect-4
67557
129
43
PUMSB
49046
7117
74
Connect-4 Dataset
P-tree based
Dense Miner
P-tree based
PUMSB Dataset
3500
Dense Miner
2500
3000
2000
2000
Time (s)
Time (s)
2500
1500
1500
1000
1000
500
500
0
20 30 40 50 60 70 80 90 100
0
40
Confidence Threshold (% )
50
60
70
80
90
100
Confidence Threshold (% )
Results for Dense-Miner are observed with minimum coverage
threshold fixed at 1% and 5%
Number of produced rules
PUMSB-4 Dataset
Connect-4 Dataset
200
150
100
50
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95
99
99
.5
0
Confidence Threshold (%)
160000
140000
120000
100000
80000
60000
40000
20000
0
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
91
91
.5
Number of rules
Number of rules
250
Confidence Threshold (%)
-# ranges from around 500,000 rules to less than 10 rules over
both data sets
-larger (smaller) number of rules produced at higher (lower)
confidence thresholds
Summary
Proposed an approach based on SE-trees, Tabu
search and the P-tree technology for extracting
minimal, confident rules with fixed-consequent
Efficient when such rules are desired
The approach is complete in the sense that it does
not miss any minimal, confident rule
Suffers in situations where the desired minimal
rules lie deep in the tree
A large number of nodes and levels need to be traversed
Future direction
Finding heuristic measures
estimating the probability of rule availability along
certain branches
quitting early in cases where such probability is low.
Experiment limiting how deep down the tree we go
using
Fixed number of plies
Iterative deepening