Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
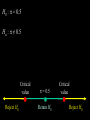
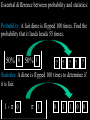
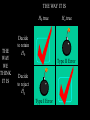
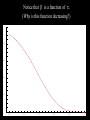
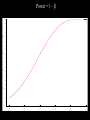
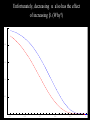
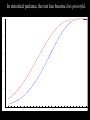
Math 3680 Lecture #6 Introduction to Hypothesis Testing We illustrate the method of hypothesis testing with an example. Throughout this example, the lingo of hypothesis testing will be introduced. We will use this terminology throughout the rest of the chapter. Example: Historically, an average of 1,808 people have entered a certain store each day. In hopes of increasing the number of customers, a designer is hired to refurbish the store's entrance. After the redesign, a simple random sample of 45 days is taken. In this sample, an average of 1,895 people enter the store daily, with a sample SD of 187. Does it appear that the redesign of the store's entrance was effective? “Solution”: There are two possibilities: 1. The increase in the average number of customers may be plausibly attributed to a run of good luck, or 2. The average increased after the redesign. We cannot give a decisive answer to this question, since both of these explanations are possible. The first option, which attributes the increase in the number of customers to mere chance, is called the null hypothesis. The other option is called the alternative hypothesis. We need to assess which option is more plausible. Under certain extremes, the choice is fairly obvious. • If 10,000 people were now entering the story daily, then it can be confidently concluded that, after the redesign, the store had more customers. In this case, we would reject the null hypothesis. • On the other hand, if the store averaged only 1,809 people entering daily, then such an increase is reasonably attributable to chance. In this case, we would retain (or fail to reject) the null hypothesis. Somewhere between these two extremes will be a certain cut-off point called the critical value. Above this critical value, it will be more plausible to think that the average number of customers increased after the redesign. Below this critical value, it will be more plausible to think that the increase is simply attributable to chance. 1808 1809 Critical value 10,000 Therefore, the question may be rephrased as follows: Is the sample average of 1,895 close enough to 1,808 to be consistent with the assumption that the population mean is still 1,808? This question leads to two hypotheses: H0 : The average is still 1,808. Ha : The average is greater than 1,808. (Why greater?) H0 : The average is still 1,808. Ha : The average is greater than 1,808. 1808 Decision: Retain H0 Critical value Reject H0 Example: A dime is flipped 100 times to determine if it is fair. State the null and alternative hypotheses. H0 : p = 0.5 Ha : p ≠ 0.5 Critical value Reject H0 p = 0.5 Retain H0 Critical value Reject H0 Essential difference between probability and statistics: Probability: A fair dime is flipped 100 times. Find the probability that it lands heads 55 times. 50% 0 50% 1 ? ? ? ? ? Statistics: A dime is flipped 100 times to determine if it is fair. 1-p 0 p 1 0 1 1 0 0 Example: Many staff members in teaching hospitals are hired in July. Because of these inexperienced staff members, is it more dangerous to be admitted to a teaching hospital between July and September than it is during the rest of the year? State the null and alternative hypotheses. Example: A dime is suspected of landing heads more often than tails. It is flipped 100 times to determine if it is fair. State the null and alternative hypotheses, and draw the corresponding figure. No matter where we set the critical value, we will occasionally make a mistake. By chance, a fair coin may land heads more times than the critical value. This situation is called a Type I error, meaning that we would decide to reject the null hypothesis even though the coin was fair. The probability of a Type I error is denoted by a. • Another type of error could occur if the coin that favors heads actually lands heads less often than the critical value. • This is called a Type II error, meaning that we fail to reject the null hypothesis even though the coin is imbalanced. • The probability of a Type II error is denoted by b. • We define the power of the test to be 1 - b. This is the probability of correctly rejecting the null hypothesis when the null hypothesis is false. Type I Error: The null hypothesis is true but we reject it. P(reject H0| H0 is true) = α Type II Error: The null hypothesis is false but we retain it. P(retain H0| H0 is false) = β Power: P(reject H0| H0 is false) = 1- β THE WAY IT IS H0 true THE WAY WE THINK IT IS Ha true Decide to retain H0 Type II Error Decide to reject H0 Type I Error Example: Many staff members in teaching hospitals are hired in July. Because of these inexperienced staff members, is it more dangerous to be admitted to a teaching hospital between July and September than it is during the rest of the year? State in words what a Type I error means. Repeat for a Type II error. Example: Historically, an average of 1,808 people have entered a certain store each day. In the hopes of increasing the number of customers, a designer is hired to refurbish the store's entrance. After the redesign, a simple random sample of 45 days is taken. In this sample, an average of 1,895 people enter the store daily, with a sample standard deviation of 187. State in words what a Type I error means. Repeat for a Type II error. Basic question: “How do we pick the critical value?” Typically, the value of a is prescribed and the critical values are determined by a. We will discuss this in more depth later. For now, to develop our intuition, we’ll take the critical values as prescribed and compute a and b from these critical values. Example: A scientific article compared two different methods for the analysis of ampicillin dosages. It was thought that the first method generally returned a higher amount than the second method. In one series of experiments, pairs of tablets were analyzed by the two methods. The data below give the percentages of claimed amount of ampicillin found by the two methods in 15 pairs of tablets. State the null and alternative hypotheses. 97.2 105.8 99.5 100.0 93.8 97.2 97.8 96.2 101.8 88.0 79.2 76.0 69.5 23.5 95.2 74.0 75.0 67.5 21.2 94.8 96.8 95.8 99.2 98.0 99.2 99.0 91.0 100.2 72.0 67.5 Solution #1 (in words): H0 : If there is a difference, the probability that the first method returns a higher amount is 50%. Ha : If there is a difference, the probability that the first method returns a higher amount is greater than 50%. Solution #2 (more precise): Let p be the population proportion of pairs in which the first method returns a higher amount. H0 : p = 0.5 (simple hypothesis) Ha : p > 0.5 (compound hypothesis) Example: For this particular data set, there are 14 pairs in which there is a measurable difference. Let K denote the number of pairs in which the first method returned a higher amount. Suppose we make the decision rule Retain H0 if K 9, and reject H0 if K 10. Compute a. 97.2 105.8 99.5 100.0 93.8 97.2 97.8 96.2 101.8 88.0 79.2 76.0 69.5 23.5 95.2 74.0 75.0 67.5 21.2 94.8 96.8 95.8 99.2 98.0 99.2 99.0 91.0 100.2 72.0 67.5 Solution: This is the risk of an error in case that H0 is true. a = P(H0 is rejected | H0 is true) = P(K 10 | p = 0.5) 14 14 14 10 4 11 3 (0.5) (0.5) (0.5) (0.5) (0.5)12 (0.5) 2 10 11 12 14 14 13 1 14 0 (0.5) (0.5) (0.5) (0.5) 13 14 0.0897827 Example: Suppose we make the decision rule retain H0 if K 9 reject H0 if K 10 Compute b if (a) p = 0.7 (b) p = 0.9 Solution: (a) This is the risk of an error in case that p = 0.7, so that H0 is false. b = b (0.7) = P(H0 is retained | p = 0.7) = P(K 9 | p = 0.7) 14 14 14 0 14 1 13 (0.7) (0.3) (0.7) (0.3) (0.7) 2 (0.3)12 0 1 2 14 14 7 7 14 8 6 (0.7) (0.3) (0.7) (0.3) (0.7)9 (0.3)5 7 8 9 0.415799 Solution: (b) This is the risk of an error in case that p = 0.9, so that H0 is false. b = b (0.9) = P(H0 is retained | p = 0.9) = P(K 9 | p = 0.9) 14 14 14 0 14 1 13 (0.9) (0.1) (0.9) (0.1) (0.9) 2 (0.1)12 0 1 2 14 14 7 7 14 8 6 (0.9) (0.1) (0.9) (0.1) (0.9) 9 (0.1) 5 7 8 9 0.00923021 Notice that b is a function of p. (Why is this function decreasing?) 1 0.8 0.6 0.4 0.2 0.5 0.6 0.7 0.8 0.9 1 Power = 1 - b. 1 0.8 0.6 0.4 0.2 0.5 0.6 0.7 0.8 0.9 1 Note. This lengthy calculation may be facilitated by using page 505 from the back of the book: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 0.1 0.2288 0.5846 0.8416 0.9559 0.9908 0.9985 0.9998 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 0.2 0.0440 0.1979 0.4481 0.6982 0.8702 0.9561 0.9884 0.9976 0.9996 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 0.25 0.0178 0.1010 0.2811 0.5213 0.7415 0.8883 0.9617 0.9897 0.9978 0.9997 1.0000 1.0000 1.0000 1.0000 1.0000 0.3 0.0068 0.0475 0.1608 0.3552 0.5842 0.7805 0.9067 0.9685 0.9917 0.9983 0.9998 1.0000 1.0000 1.0000 1.0000 0.4 0.0008 0.0081 0.0398 0.1243 0.2793 0.4859 0.6925 0.8499 0.9417 0.9825 0.9961 0.9994 0.9999 1.0000 1.0000 0.5 0.0001 0.0009 0.0065 0.0287 0.0898 0.2120 0.3953 0.6047 0.7880 0.9102 0.9713 0.9935 0.9991 0.9999 1.0000 0.6 0.0000 0.0001 0.0006 0.0039 0.0175 0.0583 0.1501 0.3075 0.5141 0.7207 0.8757 0.9602 0.9919 0.9992 1.0000 0.7 0.0000 0.0000 0.0000 0.0002 0.0017 0.0083 0.0315 0.0933 0.2195 0.4158 0.6448 0.8392 0.9525 0.9932 1.0000 0.8 0.0000 0.0000 0.0000 0.0000 0.0000 0.0004 0.0024 0.0116 0.0439 0.1298 0.3018 0.5519 0.8021 0.9560 1.0000 0.9 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0002 0.0015 0.0092 0.0441 0.1584 0.4154 0.7712 1.0000 0.95 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0004 0.0042 0.0301 0.1530 0.5123 1.0000 This lengthy calculation may also be facilitated with EXCEL: =BINOMDIST(9,14,0.7,1) TI-83: binomcdf(14,0.7,9) Example: For this particular data set, there are 14 pairs in which there is a measurable difference. Let K denote the number of pairs in which the first method returned a higher amount. Suppose we make the decision rule Retain H0 if K 10, and reject H0 if K 11. Compute a. 97.2 105.8 99.5 100.0 93.8 97.2 97.8 96.2 101.8 88.0 79.2 76.0 69.5 23.5 95.2 74.0 75.0 67.5 21.2 94.8 96.8 95.8 99.2 98.0 99.2 99.0 91.0 100.2 72.0 67.5 Solution: This is the risk of an error in case that H0 is true. a = P(H0 is rejected | H0 is true) = P(K 11 | p = 0.5) 14 14 11 3 (0.5) (0.5) (0.5)12 (0.5) 2 11 12 14 14 13 1 (0.5) (0.5) (0.5)14 (0.5) 0 13 14 0.0286865 Practically, why did this decrease? Note. This lengthy calculation may be facilitated by using page 505 from the back of the book: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 0.1 0.2288 0.5846 0.8416 0.9559 0.9908 0.9985 0.9998 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 0.2 0.0440 0.1979 0.4481 0.6982 0.8702 0.9561 0.9884 0.9976 0.9996 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 0.25 0.0178 0.1010 0.2811 0.5213 0.7415 0.8883 0.9617 0.9897 0.9978 0.9997 1.0000 1.0000 1.0000 1.0000 1.0000 0.3 0.0068 0.0475 0.1608 0.3552 0.5842 0.7805 0.9067 0.9685 0.9917 0.9983 0.9998 1.0000 1.0000 1.0000 1.0000 0.4 0.0008 0.0081 0.0398 0.1243 0.2793 0.4859 0.6925 0.8499 0.9417 0.9825 0.9961 0.9994 0.9999 1.0000 1.0000 0.5 0.0001 0.0009 0.0065 0.0287 0.0898 0.2120 0.3953 0.6047 0.7880 0.9102 0.9713 0.9935 0.9991 0.9999 1.0000 0.6 0.0000 0.0001 0.0006 0.0039 0.0175 0.0583 0.1501 0.3075 0.5141 0.7207 0.8757 0.9602 0.9919 0.9992 1.0000 0.7 0.0000 0.0000 0.0000 0.0002 0.0017 0.0083 0.0315 0.0933 0.2195 0.4158 0.6448 0.8392 0.9525 0.9932 1.0000 0.8 0.0000 0.0000 0.0000 0.0000 0.0000 0.0004 0.0024 0.0116 0.0439 0.1298 0.3018 0.5519 0.8021 0.9560 1.0000 From the back of the book, 1 - 0.9713 = 0.0287 From Excel, use =1 - BINOMDIST(10,14,0.5,1) 0.9 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0002 0.0015 0.0092 0.0441 0.1584 0.4154 0.7712 1.0000 0.95 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0004 0.0042 0.0301 0.1530 0.5123 1.0000 Unfortunately, decreasing a also has the effect of increasing b. (Why?) 1 0.8 0.6 0.4 0.2 0.5 0.6 0.7 0.8 0.9 1 In statistical parlance, the test has become less powerful. 1 0.8 0.6 0.4 0.2 0.5 0.6 0.7 0.8 0.9 1 Note: In a perfect world, we would have a = b = 0, but this can only happen in trivial cases. For any realistic scenario of hypothesis testing, decreasing a will increase b, and vice versa. In practice, we set the significance level a in advance, usually at a fairly small number (a 0.05 is typical) . We then compute b for this level of a. (Ideally, we would like to construct a test that makes b as small as possible. This topic will be considered in future statistics courses.) In these problems, the critical regions were prescribed and a was computed. In practice, a is chosen and the critical value is computed to match this value of a.