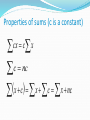Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Methods for Describing Sets of Data 2.1 Describing Qualitative Data Example Operations Performed at a Hospital last year Thoracic 20 Bones and joints 45 Eye, ear, nose, and throat 58 General 98 Abdominal 115 Urologic 74 Neurosurgery 23 Other 65 100 90 80 70 60 50 40 Sum of Frequency 120 110 30 20 Urologic Thoracic Other Neurosurge General Eye, Ear, No Bones and Abdominal Bar Graph: displays number or percentage of items in each category using bars Used for qualitative data The height of a bar represents the quantity we wish to compare The bars should be of uniform width and uniformly spaced 2.2 Graphical Methods for Describing Quantitative Data Stem and Leaf – separates data entries into “leading digits” or “stems” and “trailing digits” or “leaves” A device that organizes and groups data but allows us to recover the original data if desired Good for spotting extreme values and patterns Example 14 male weights in pounds 139, 153, 179, 201, 163, 168, 157, 170, 172, 165, 145, 155, 161, 151 Frequency distribution – a summary table in which the data are arranged into conveniently established class groupings useful when dealing with very large data sets through the grouping process the original data is lost should have between 5 and 15 classes each class grouping should be of equal width overlapping the classes must be avoided class midpoint – the point halfway between the boundaries of each class Weight 130 but less than 140 140 but less than 150 150 but less than 160 160 but less than 170 170 but less than 180 180 but less than 190 190 but less than 200 200 but less than 210 Total Number of males 1 1 4 4 3 0 0 1 14 Histogram – a picture of a frequency distribution differs from a bar chart Used for quantitative data 4 Frequency 3 2 1 0 135 145 155 165 175 C1 185 195 205 Symmetric Uniform Skewed Right Skewed Left Bimodal There are several terms that are commonly used to describe histograms Symmetrical – both sides are the same when the graph is folded vertically Uniform – every class has equal frequency (bars are the same height) Skewed Left or Skewed Right – one tail is stretched longer than the other. The direction of the skewness is on the side of the longer tail. Bimodal – the two classes with largest frequencies are separated by at least one class (can indicate that we are sampling from two populations) . 2.3 Summation Notation The sum of values, x1 x2 xn n , can be denoted as x i 1 i Example Select 4 students and ask “how many brothers and sisters do you have?” Data: 2, 3, 1, 3 4 x i 1 i 2 3 1 3 9 Or we can write x 9 Properties of sums (c is a constant) cx c x c nc x c x c x nc Example Solve the following: 4x x 3 4x 3 4x 3 2 2.4 Numerical Measures of Central Tendency Description of Average (Typical Value) Sample Mean: x x n Example number of siblings – Data: 2, 3, 1, 3 Suppose we had selected a 5th person for our sample which had 10 siblings. New Data: 2, 3, 1, 3, 10 The sample mean is sensitive to extreme values and does not have to be a possible data value. ~ Sample Median, x rank data from smallest to largest if n is odd, median is the middle score if n is even, median is the mean of two middle scores Example number of siblings – Data: 2, 3, 1, 3 New Data: 2, 3, 1, 3, 10 Sample median is not sensitive to extreme scores Half the data will fall above the sample median and half below the sample median The median is a better measure of central tendency if extreme scores exist. If extreme scores are unlikely, the mean varies less from sample to sample than the median and is a better measure. Shape of a distribution If the distribution is right skewed ~ xx If the distribution is symmetric ~ xx If the distribution is left skewed ~ xx sample mode: most frequent score Example number of siblings – Data: 2,3,1,3 Mode = 3 New Data: 2,3,1,3,10 Mode = 3 Mode does not always exist/can be more than one Also, it is unstable Should be used with qualitative data sample midrange, Low High 2 Example number of siblings – Data: 2,3,1,3 Low High 1 3 2 Midrange = 2 2 New Data: 2,3,1,3,10 Low High 1 10 Midrange = 5.5 2 2 Midrange is totally dependent on extreme scores. 2.5 Numerical Measures of Variability Distribution #1 1 2 5 3 5555555 4 5 5 Distribution #2 1 5 2 55 3 555 4 55 5 5 Distribution #1 X = 35 ~ = 35 X mode = 35 midrange =35 Distribution #2 X = 35 ~ = 35 X mode = 35 midrange = 35 Sample Range = High - Low Example Years of experience of faculty - Data: 1, 30, 22, 10, 5 Range is sensitive to extreme scores (Based entirely on the high and low) Range is easy to compute sample variance - measures the average squared distance the data points are from x Sum of Squared X SSX S n 1 n 1 2 x x 2 n 1 Large values suggest large variability Difficult to interpret since it is in square units Can never be negative n x x 2 nn 1 2 Example Years of experience of faculty - Data: 1, 30, 22, 10, 5 sample standard deviation – measures the average distance data points are from x S S2 Standard deviation is in the same units as the data 2.6 Interpreting the Standard Deviation Z-score – Gives the number of standard deviations an observation is above or below the mean xx z s Example Test scores X = 79, s = 9 If your score is 88%, what is your z-score? If your score is 63%, what is your z-score? Empirical rule (For mound shaped distributions) Approximately 68% of the data fall within 1 standard deviation of the mean ( x s, x s ) Approximately 95% of the data fall within 2 standard deviations of the mean ( x 2 s, x 2s ) Approximately 99.7% of the data fall within 3 standard deviations of the mean ( x 3s, x 3s) Example Suppose that the amount of liquid in “12 oz.” Pepsi cans is a mound shaped distribution with x 12 oz. and s = 0.1 oz. 2.7 Numerical Measures of Relative Standing Percentiles – gives the percentage below an observation Quartiles – divide the data into four equally sized parts Q1 - First Quartile: 25th percentile Q2 - Second Quartile ( ~x ), 50th percentile Q3 - Third Quartile, 75th percentile Procedure to Compute Quartiles Order the data from smallest to largest Find ~ x . This is Q2 Q1 is the median of the lower half of the data; that is, it is the median of the data falling below Q2 (not including Q2 ) Q3 is the median of the upper half of the data; (same as above) Interquartile range (IQR) = Q3 – Q1 Range of the middle 50% of the data 5 number summary – The low score, Q1, Q2, Q3, and the high score Example Amount of money individuals have at a meeting Students 0 0013555678 1 0 2 3 4 5 6 7 Faculty 0 1 055 2 04588 3 1 4 3 5 6 7 3 Students Low = 0 Q1 = 1 Q2 = 5 Q3 = 7 High = 10 Faculty Low = 10 Q1 = 15 Q2 = 25 Q3 = 31 High = 73 2.8 Methods for Detecting Outliers: Box Plots and z-Scores Box Plots The box goes from Q1 to Q3 and represents IQR The line through the box is Q2 ( ~ x) Extreme values are identified by *’s Lines, called whiskers, run from Q1 to the lowest value and from Q3 to the highest value (If the low or high are extreme then the whisker goes to the next value) 80 70 Students 60 50 40 30 20 10 0 Students Faculty Example How does tread design affect an automobiles stopping distance? (One Qualitative and One Quantitative Variable) A 43 38 33 A B C 2.9 Graphing Bivariate Relationships Two Quantitative Variables Plot observed data on a graph Horizontal (X axis) independent variable Vertical (Y axis) dependent variable We call the graph a scatter diagram or scatter plot Example X = Dosage of Drug Y = Reduction in Blood Pressure X Y 100 10 200 18 300 32 400 44 500 56 Note the strong relationship between X and Y Perfect positive linear correlation 50 40 C1 30 20 10 0 0 10 20 30 C2 40 50 Perfect negative linear correlation 50 40 C1 30 20 10 0 0 10 20 30 C2 40 50 Positive linear correlation 50 40 C1 30 20 10 0 0 10 20 30 C2 40 50 Negative linear correlation 50 40 C1 30 20 10 0 0 10 20 30 C2 40 50 Non-linear correlation 30 C2 20 10 0 0 10 20 30 C1 40 50 No correlation 50 40 C2 30 20 10 0 0 10 20 30 C1 40 50 2.10 Distorting the Truth with Descriptive Statistics One trick with graphs is to not start the scale at zero This makes small differences look much bigger