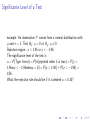Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Basic Statistical Concepts
population–the collection of all items of interest to a researcher.
sample–a subset of the population which we gather information
on. A common sample is SRS (simple random sample).
descriptive statistics–summarize information contained in a
sample.
statistical inference–generalize from the sample to the
population.
statistic–a numerical summary of a sample. A statistic is random.
Its distribution is called sampling distribution.
Descriptive Statistics
frequency distribution and histogram: for summarizing quantitative
data.
Pn
yi
sample mean ȳ = i=1
n
sample median: the midpoint
of the ordered data.
Pn
(y
−ȳ
)2
i
2
sample variance: s = i=1n−1
.
√
sample standard deviation: s = s 2 .
Random Variables
random variable is a mapping from every possible outcome of an
experiment to real numbers. notation: X, Y, Z,...
Example: Ask a student whether she/he works part time or not.
S= {Yes, No}.
X=1 if Yes, X=0 if No.
Y = number of car accidents in a week.
Flip a coin three times. Let Z=number of heads in three flips.
{TTT } → Z = 0
{HTT , THT , TTH} → Z = 1
{HHT , HTH, THH} → Z = 2
{HHH} → Z = 3.
W = the weight of a randomly selected athlete.
Discrete Random Variables
A discrete random variable takes finite or countably infinite
values.
The probability mass function distribution (pmf) of Z is
z
P(z)
——————
0
1/8
1
3/8
2
3/8
3
1/8
Note that
1.) 0P≤ P(x) ≤ 1
2.)
P(x) = 1.
The Mean of X
The mean or expected
value of a random variable X is
P
E (X ) = µX = xP(x).
What is the mean of Z ?
The variance of P
X is
P
2
Var (X ) = σX = (x − µ)2 P(x) = E (X 2 ) − µ2 = x 2 p(x) − µ2 .
Exercise
A Computer shop builds shipments of parts it receives from various
suppliers. Let X be the number of defective hard drives per
shipments. It is assumed X has the following distribution.
x
P(x)
——————–
0
0.55
1
0.15
2
0.10
3
0.10
4
0.05
5
0.05
Find P(X ≥ 2), E (X ).
The Normal Distribution
standard normal distribution: Z ∼ N(0, 1).
R code: pnorm(1.2)
X ∼ N(µ, σ), Z = x−µ
σ ∼ N(0, 1).
example: A large retail firm has accounts receivable that are
normally distributed with mean µ = 281 dollars and standard
deviation σ = 35 dollars. What proportion of accounts has
balances greater than 316 dollars?
) = P(Z > 1) = 0.1587.
P(X > 316) = P(Z > 316−281
35
R code: 1-pnorm(1)
1-pnorm(316,281,35)
exercise
1. Find P(Z > 1.56), P(0 ≤ Z ≤ 1.2), P(Z ≥ 2.33).
2. The exam scores for applicants to a university are normally
distributed with a mean 800 and standard deviation of 100.
Applicants must score 700 to be admitted.
1). What proportion of applicants is granted admission?
2). What proportion will score 1000 or higher?
3). For the coming year, 2500 applicants will take the exam. How
many are expected to qualify for admission?
Solutions
1. P(Z > 1.56) = 0.0594 (R: 1- pnorm(1.56)
P(0 ≤ Z ≤ 1.2) = 0.3849, P(Z ≥ 2.33) = 0.01.
(R:pnorm(1.2)-pnorm(0); 1-pnorm(2.33).
2. 1). 0.8413. (R: 1-pnorm(700, 800, 100)).
2). 0.0228. (R: 1-pnorm(1000,800,100))
3). 2500*0.8413=2103.
Sampling Distribution
Sample mean Ȳ is a random variable with
2
µȲ = µ, σȲ2 = σn or σȲ = √σn .
Example: In a certain production process, the diameter of a part is
normally distributed with a mean 40 centimeters and a standard
deviation 0.2 cm. If a random sample of 16 parts is chosen, what
is the probability that the average of the diameter is greater than
40.1 cm? √
σȲ = 0.2/ 16 = 0.05,
P(Ȳ > 40) = P(Z > 40.1−40
0.05 ) = 0.0228.
Central Limit Theorem CLT
If the sample size is large, the sampling distribution of the sample
mean is approximately normal regardless of the population
distribution. i.e., approximately Ȳ ∼ N(µ, √σn ).
exercise
The time to complete a work in a plant is assumed to have a
standard deviation of 5 min. A random sample of 36 workers is
chosen. What is the probability that the sample mean is within 1
min of the population’s true mean time?
Estimate a population mean
Population distribution is normal with σ known.
(1 − α)100% CI for µ : ȳ ± z √σn ,
where z = zα/2 , i.e, the probability above zα/2 is α/2. e.g, for a
95% CI, z0.025 = 1.96.
R code: qnorm(0.025) or qnorm(0.975).
example
A department store manager wants a 90% CI for the current
average balance of charge customers. A random sample of 100
accounts gives a sample mean of 245 dollars. Suppose the
population standard deviation is 45 dollars. What is the 90% CI for
the true average balance?
) = (237.58, 252.43) dollars.
(245 ± 1.645 √45
100
R code : qnorm(0.05) or qnorm(0.95).
σ unknown
CI: (ȳ ± tα/2,n−1 √sn ).
example: A manager wants to estimate the average life of an
electrical component. The lifetimes in hours of 5 randomly
selected components are
92,110,115,103, 98. The lifetimes of the population are assumed
to be normal. Get a 95% CI for the population mean lifetime.
ȳ = 103.6, s = 9.18, t0.025,4 = 2.776 and
√ ) = (92.2, 115.0) hours.
the CI is (103.6 ± 2.776 9.18
5
R code qt(0.025,4) or qt(0.975,4).
exercise
A quality control manager is concerned with the mean amount of
weight that can be held by a type of steel beam. A random sample
of 4 beams is tested with the following amounts of weight added
before the beams began to show stress: 9,11,10,8. Assume the
population of weights is normally distributed. Get a 90% CI for the
population mean weight that can be held.
HW 1
1.
2.
3.
4.
5.
6.
7.
prob
prob
prob
prob
prob
prob
prob
3 page 16.
5 page 17.
6 page 17.
14 page 24.
17 page 26.
23 page 31.
25 page 31.
Hypothesis Test about a Population Mean
H0 : “prior belief” statement.
Ha : a statement that contradicts H0 .
A test of hypothesis is a method for using sample data to decide
whether H0 should be rejected.
test statistic: a function of sample data on which the decision
(reject H0 or do not reject H0 ) is to be based.
rejection region: The set of all statistic values for which H0 will
be rejected.
Type I error: rejecting H0 when it is true.
Type II error: not rejecting H0 when it is false.
Significance Level of a Test
example: An observation Y comes from a normal distribution with
µ and σ = 1. Test H0 : µ = 0 vs Ha : µ 6= 0.
Rejection region : y > 1.96 or y < −1.96.
The significance level of the test is
α = P(Type I error) = P(H0 rejected when it is true) = P(y >
1.96ory < −1.96whenµ = 0) = P(z > 1.96) + P(z < −1.96) =
0.05.
What the rejection rule should be if it is desired α = 0.10?
Rejection Region
H0 : µ = µ0
A random sample of size n is selected. Assume population
standard deviation σ is known.
ȳ −µ
√0 .
Test statistic value: z = σ/
n
Ha : µ > µ0 rejection region: z > zα
Ha : µ < µ0 rejection region: z < −zα .
Ha : µ 6= µ0 rejection region: z > zα/2 , or z < −zα/2 .
Rejection Region: σ unknown
H0 : µ = µ0
√0 .
Test statistic value: t = ȳs/−µ
n
Ha : µ > µ0 rejection region: t > tα,n−1
Ha : µ < µ0 rejection region: t < −tα,n−1 .
Ha : µ 6= µ0 rejection region: t > tα/2,n−1 , or t < −tα/2,n−1 .
Example 2.7
Five components are randomly selected with lifetimes in hours
92,110,115,103,98. Test if the population average life is below 110
hours using a significance level of α = 0.05.
H0 : µ ≥ 110
Ha : µ < 110.
Reject H0 if t < −t0.05,4 = −2.132.
ȳ = 103.6, s = 9.18,
√
= −1.56.
t = 103.6−110
9.18/ 5
Do not reject H0 .
Exercise
A sample of 16 candy bars from a shipment produces
ȳ = 4.85, s = 0.1 ounce. Test the hypothesis
H0 : µ ≥ 5
Ha : µ < 5 using α = 0.05. Assume the population of candy bar
weights is normally distributed. Does the data support the claim
that the producer has short-weight selling practice?
R Code
y=c(92,110,115,103,98)
t.test(y,alternative=”less”,mu=110)
t.test(y,alternative =”greater”,mu=110)
Reject H0 if p value < α
Do not reject H0 if p value ≥ α.
Estimate µ1 − µ2
If both population distributions are normal, and the two samples
are independent,
Ȳ2 −(µ1 −µ2 )
P(−zα/2 ≤ Ȳ1 −r
≤ zα/2 ) = 1 − α.
2
2
σ
1
n1
σ
+ n2
2
and a 100(1 −q
α)% CI for µ1 − µ2 is
σ2
σ2
ȳ1 − ȳ2 ± zα/2 n11 + n22 .
σ1 , σ2 unknown
Assumptions: both populations are normal. The two samples are
independent.
Ȳ2 −(µ1 −µ2 )
approximately has a t distribution with df
T = Ȳ1 −r
2
2
S
1
n1
S
+ n2
2
calculated by a formula on page 41. Or you can choose
df = min(n1 − 1,q
n2 − 1).
CI: (ȳ1 − ȳ2 ) ± t
s12
n1
+
s22
n2 .
Pooled Sample Variance
Assume σ12 = σ22 , then
2
2
var (ȳ1 − ȳ2 ) = σn1 + σn2 .
(n −1)s 2 +(n −1)s 2
2
1
2
Pooled sample variance: sp2 = 1 n1 −1+n
.
2 −1
1 2
1 2
2
Note if n1 = n2 , then sp = 2 s1 + 2 s2 .
q
and sȳ1 −ȳ2 = sp n11 + n12 .
Fact: If the two independent samples are from normal
distributions, then
(ȳ1 −ȳ2 )−(µ1 −µ2 )
q
∼ tn1 +n2 −2 .
sp n1 + n1
1
2
q
CI: ȳ1 − ȳ2 ± t ∗ sp n11 + n12 .
Exercise
To help validate a new employee-rating form, a company
administers it to independent random samples of employees in two
divisions. The following information is obtained:
n1 = n2 = 15, ȳ1 = 82, ȳ2 = 78, s1 = 3.0, s2 = 2.5.
Get a 95% CI for the mean difference in mean scores between the
two divisions. Assume the two population variances are equal and
the populations are normally distributed.
Hypothesis test about µ1 − µ2
H0 : µ1 − µ2 = 0 or µ1 = µ2
Ha : µ1 − µ2 6= 0 or µ1 6= µ2 .
Reject H0 if t > tα/2,df or t < −tα/2,df .
Where
2
with df=n1 + n2 − 2 if σ12 = σ22 .
t = q 2ȳ1 −ȳ
1
1
t=
sp ( n + n )
1
2
ȳ
r 1 −ȳ2 with
s2
s2
1+ 2
n1
n2
if σ12 6= σ22 .
df given on page 45 or df = min(n1 − 1, n2 − 1)
One-sided Test
H 0 : µ1 − µ1 ≤ 0
H a : µ1 − µ2 > 0
Reject H0 if t > tα,df .
H 0 : µ1 − µ1 ≥ 0
H a : µ1 − µ2 < 0
Reject H0 if t < −tα,df .
R code
Two sample t test
t.test(x, y)
t.test(x,y,alternative=”greater”)
t.test(x,y,alternative=”less”)
t.test(x,y,var.equal=TRUE)
Exercise
Use the plant data set.
Test if the mean height of cross fertilized plants in taller than that
of self fertilized plants.