Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
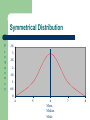
Statistics and Research methods Wiskunde voor HMI Betsy van Dijk Introduction Statistics is about – – – – Systematically studying phenomena in which we are interested Quantifying variables in order to use mathematical techniques Summarizing these quantities in order to describe and make inferences Using these descriptions and inferences to make decisions or understand The Two Branches of Statistical Methods Descriptive statistics (beschrijvende statistiek) – Used to summarize, organize and simplify data Inferential statistics (toetsende statistiek) – – Draw conclusions/make inferences that go beyond the numbers from a research study Techniques that allow us to study samples and then make generalizations about the populations from which they were selected Descriptive Statistics Numbers that describe the characteristics of a particular data set – – “The average age in the class is 27 years” “The range of ages in class is 22 years, from a minimum of 20 to a maximum of 42” Inferential Statistics Descriptive statistics from a sample that are used to make inferences about the characteristics of a population. – “The average age of people taking Research Statistics is 27 years.” a “parameter” People taking Research Statistics A sample of people taking Research Statistics Basic Concepts - Variables Things that change – – – Environmental events or conditions Personal characteristics or attributes Behaviors Anything that takes on different values in different situations (even just through time) Basic Concepts Value – Score – A particular person’s value on a variable Data – A possible number or category that a score can have Scores or measurements of phenomena, behaviors, characteristics, etc. A Statistic – A number that summarizes a set of data in some way Populations and Samples Population – Sample – Set of all the individuals of interest in a population study Set of individuals selected from the population Sampling error – Discrepancy, or amount of error that exists between the sample statistic and population parameter Measurement Measurement is the process of assigning numbers to variables following a set of rules There are different levels of measurement – – – – Nominal Ordinal Interval Ratio Nominal Measurement Places data in categories Non-quantitative (e.g. qualitative), even though there might be numbers involved Nominal (categorical) variables Examples – Male/Female – M,F (0,1) Voting precinct Alucha, Dade, Palm Beach (023, 095, 167) Ordinal Measurement Places data in order Quantitative as far as ranking goes Rank-order (ordinal) variables Distance between values varies Examples – First, second, third – – (1,2,3) (2.7, 2.8, 7.6) Young, Middle Age, Old Very Good, Good, Intermediate, Bad, Very Bad (1,2,3,4,5) Interval Measurement Has all the characteristics of ordinal data Additionally, the differences between values represents a specific amount of whatever is being measured (equal intervals represent equal amounts) Examples – Temperature (the difference between 20C and 40C is the same as 60C and 80C, but 0 is not the absence of temperature) Note: Many rating scales are treated like interval measurements Ratio Measurement Has all the characteristics of interval data Additionally, has a true zero which represents the absence of whatever is being measured Examples – – Time (e.g. reaction time) Distance The zero point allows you to make statements about ratios (e.g. 100 feet is twice as far as 50 feet) A Few More Things Continuous variables – Take on an infinite number of values between two measured levels (e.g. time measurements) Discrete variables – Have no intermediate values (e.g. number of people in class) Math Warm-Up Order of operations – – – Proportion – – – Some portion of some total amount Expressed by a fraction or a decimal To calculate, divide the portion by the total amount Percentage – – Parentheses, exponents, multiplication/division, addition/subtraction PEMDAS, or “please excuse my dear aunt sally” Summation using the summation statistic before other addition/substraction A proportion that is scaled to be out of 100 (instead of some other total amount) To calculate, first calculate the proportion, then multiply by 100 Mathematical operators – Exponents, square roots, parentheses, summation, indexing Math Warm-Up Practice problems y ax b ( x b) 2 y a N y xi b i 1 y 2 ( x b ) a Frequency Tables Used to summarize data Steps in making a frequency table 1. Make a list of each possible value 2. Count up the number of scores with each value 3. Make a table Frequency table shows how often each value occurs A Frequency Table Stress Rating Frequency Percent 10 9 8 7 6 5 4 3 2 1 0 14 15 26 31 13 18 16 12 3 1 2 9.3 9.9 17.2 20.5 8.6 11.9 10.6 7.9 2.0 0.7 1.3 Histogram -- Stress-rating Data 0 1 2 3 4 5 6 7 8 9 10 Frequency 2 1 3 12 16 18 13 31 26 15 14 35 30 25 Frequency Stress 20 15 10 5 0 0 1 2 3 4 5 6 Stress Rating 7 8 9 10 Grouped Frequency Table A frequency table that uses intervals Stress Rating Interval Frequency Percent 10-11 8-9 6-7 4-5 2-3 0-1 14 41 44 34 15 3 9 27 29 23 10 2 Frequency Graphs Histogram Frequency Graphs Frequency polygon Shapes of Frequency Distributions Unimodal, bimodal, and rectangular Shapes of Frequency Distributions Unimodal – there is a single most frequent value or “peak” Bimodal – there are two most-frequent values or peaks Rectangular – there is no peak; all values are about equally frequent Shapes of Frequency Distributions Symmetrical and skewed distributions Shapes of Frequency Distributions Symmetrical – left and right halves of the distribution have approximately the same shape Skewed – left and right halves of the distribution do not have the same shape “skew” is towards the side with the fewer cases Right (or positive) skew = few cases with large scores Left (or negative) skew = few cases with small scores Skewed distributions may be caused by: “Ceiling effects” – limitation in the high end of the scale “Floor effects” – limitation in the low end of the scale Sometimes skewed distributions occur because of the nature of the variable itself… Millions of Families 35 30 25 20 15 10 5 0 0 1 Number of Children 2 Shapes of Frequency Distributions Normal and kurtotic distributions Measures of Central Tendency Median – Mode – The value in the middle The most common value Mean – The average value The Mean X M N M = the mean X = the scores N = the number of scores The Median Rank the scores from lowest to highest Median is the score in the middle – if even number of scores, by convention take the average of the two middle ones Median is not as sensitive to extreme values as the mean The Mode The most frequent score To compute the mode: look at a frequency table and find the most frequent score. In a symmetrical, unimodal distribution, the mean, median and mode are all the same. Symmetrical Distribution F r e q u e n c y 3,5 3 2,5 2 1,5 1 0,5 0 4 5 6 Mean Median Mode 7 8 Question Negative Skew F r e q u e n c y 4,5 4 3,5 3 2,5 2 1,5 1 0,5 0 4 5 6 7 Where (approximately) will Mean, Median and Mode be situated? 8 Problem with the Mean The mean can be strongly influenced by outliers – This distorts the mean as a measure of central tendency The median and mode are less affected by outliers Measures of Variance – A single number that tells you how spread out a distribution is 8 8 7 7 6 Frequency All M = 15.0 5 4 3 5 4 3 2 2 1 1 0 8 0 2.5 7.5 9 7 12.5 17.5 22.5 27.5 11 13 15 17 # of Chews 6 # of Chews Frequency Frequency 6 5 4 3 2 1 0 12 13 14 15 16 # of Chews 17 18 19 21 Measures of Variance Range: difference between the maximum and minimum observed values Variance: a measure of the amount that values differ from the mean of their distribution Standard deviation: the average amount (approximately) that values differ from the mean of their distribution Variance Formula for the sample variance: 2 X M 2 SD N Estimate of the population variance: SD 2 X M 2 N 1 Unbiased estimate of population variance Degrees of freedom: df = N-1 Describing Individual Values Sometimes observations have values that people are familiar with – But sometimes values are on an unfamiliar scale – – Rating 1 to 10, Age, Temperature, SAT Score on the Wisconsin Card Sorting Task APGAR score How can you communicate the relative value of a given observation? – Is that a very high value? very low? somewhere in the middle? Z Scores Characterize a score in relation to the distribution The number of standard deviations the score is above or below the mean is called the Z score Formula for Z score: X M Z SD Standard and Raw Scores Z scores are also called “standard scores” The original scores are called “raw scores” For a distribution of Z scores, always M = 0 ... and always SD = 1